 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Encrypted Internet Traffic Classification Through Advanced Data Augmentation Techniques
Jul 23, 2024The increasing popularity of online services has made Internet Traffic Classification a critical field of study. However, the rapid development of internet protocols and encryption limits usable data availability. This paper addresses the challenges of classifying encrypted internet traffic, focusing on the scarcity of open-source datasets and limitations of existing ones. We propose two Data Augmentation (DA) techniques to synthetically generate data based on real samples: Average augmentation and MTU augmentation. Both augmentations are aimed to improve the performance of the classifier, each from a different perspective: The Average augmentation aims to increase dataset size by generating new synthetic samples, while the MTU augmentation enhances classifier robustness to varying Maximum Transmission Units (MTUs). Our experiments, conducted on two well-known academic datasets and a commercial dataset, demonstrate the effectiveness of these approaches in improving model performance and mitigating constraints associated with limited and homogeneous datasets. Our findings underscore the potential of data augmentation in addressing the challenges of modern internet traffic classification. Specifically, we show that our augmentation techniques significantly enhance encrypted traffic classification models. This improvement can positively impact user Quality of Experience (QoE) by more accurately classifying traffic as video streaming (e.g., YouTube) or chat (e.g., Google Chat). Additionally, it can enhance Quality of Service (QoS) for file downloading activities (e.g., Google Docs).
CBR -- Boosting Adaptive Classification By Retrieval of Encrypted Network Traffic with Out-of-distribution
Mar 17, 2024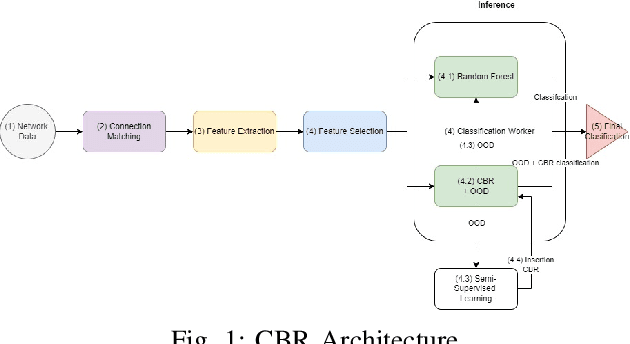
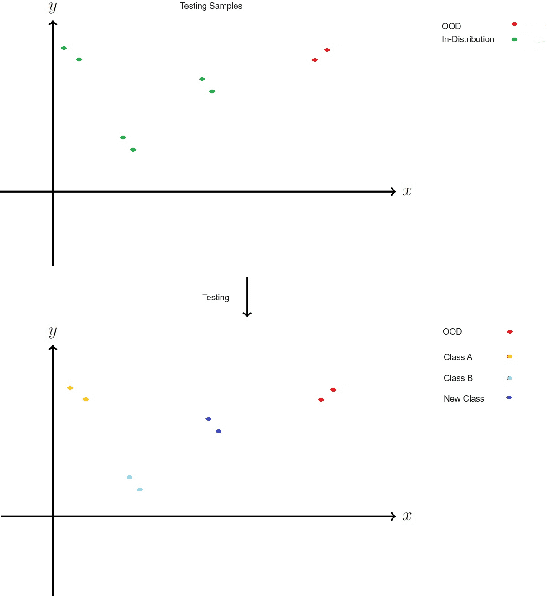
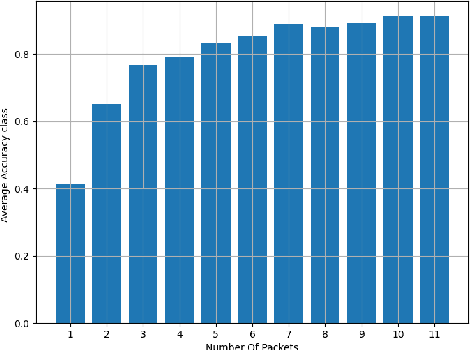
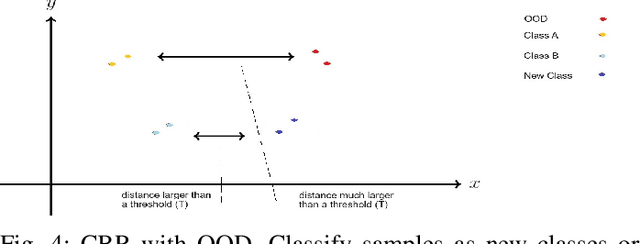
Encrypted network traffic Classification tackles the problem from different approaches and with different goals. One of the common approaches is using Machine learning or Deep Learning-based solutions on a fixed number of classes, leading to misclassification when an unknown class is given as input. One of the solutions for handling unknown classes is to retrain the model, however, retraining models every time they become obsolete is both resource and time-consuming. Therefore, there is a growing need to allow classification models to detect and adapt to new classes dynamically, without retraining, but instead able to detect new classes using few shots learning [1]. In this paper, we introduce Adaptive Classification By Retrieval CBR, a novel approach for encrypted network traffic classification. Our new approach is based on an ANN-based method, which allows us to effectively identify new and existing classes without retraining the model. The novel approach is simple, yet effective and achieved similar results to RF with up to 5% difference (usually less than that) in the classification tasks while having a slight decrease in the case of new samples (from new classes) without retraining. To summarize, the new method is a real-time classification, which can classify new classes without retraining. Furthermore, our solution can be used as a complementary solution alongside RF or any other machine/deep learning classification method, as an aggregated solution.
Open-Source Framework for Encrypted Internet and Malicious Traffic Classification
Jun 21, 2022
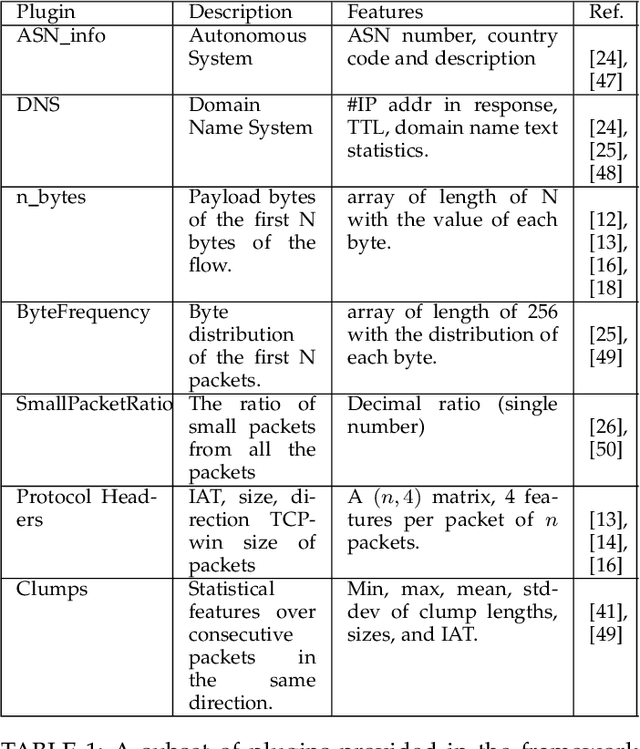
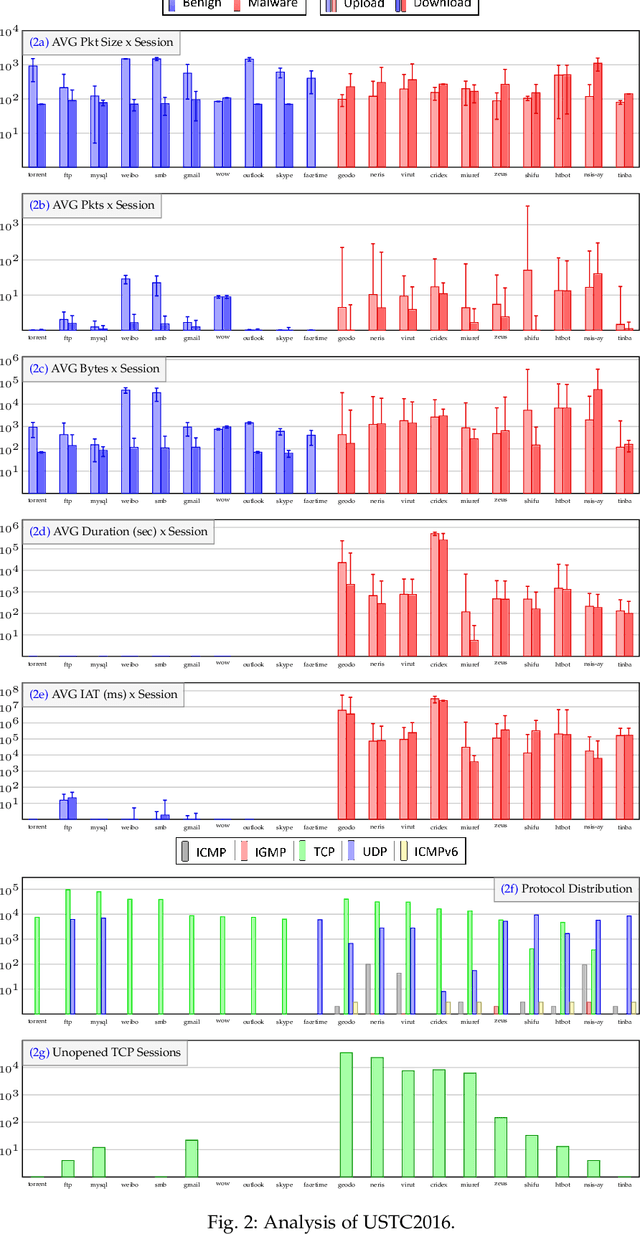
Internet traffic classification plays a key role in network visibility, Quality of Services (QoS), intrusion detection, Quality of Experience (QoE) and traffic-trend analyses. In order to improve privacy, integrity, confidentiality, and protocol obfuscation, the current traffic is based on encryption protocols, e.g., SSL/TLS. With the increased use of Machine-Learning (ML) and Deep-Learning (DL) models in the literature, comparison between different models and methods has become cumbersome and difficult due to a lack of a standardized framework. In this paper, we propose an open-source framework, named OSF-EIMTC, which can provide the full pipeline of the learning process. From the well-known datasets to extracting new and well-known features, it provides implementations of well-known ML and DL models (from the traffic classification literature) as well as evaluations. Such a framework can facilitate research in traffic classification domains, so that it will be more repeatable, reproducible, easier to execute, and will allow a more accurate comparison of well-known and novel features and models. As part of our framework evaluation, we demonstrate a variety of cases where the framework can be of use, utilizing multiple datasets, models, and feature sets. We show analyses of publicly available datasets and invite the community to participate in our open challenges using the OSF-EIMTC.
When a RF Beats a CNN and GRU, Together -- A Comparison of Deep Learning and Classical Machine Learning Approaches for Encrypted Malware Traffic Classification
Jun 16, 2022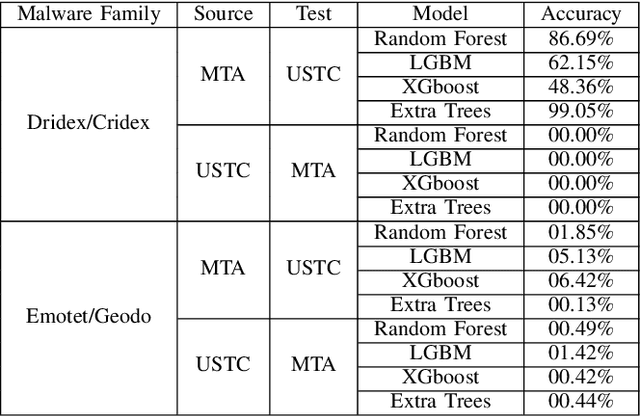
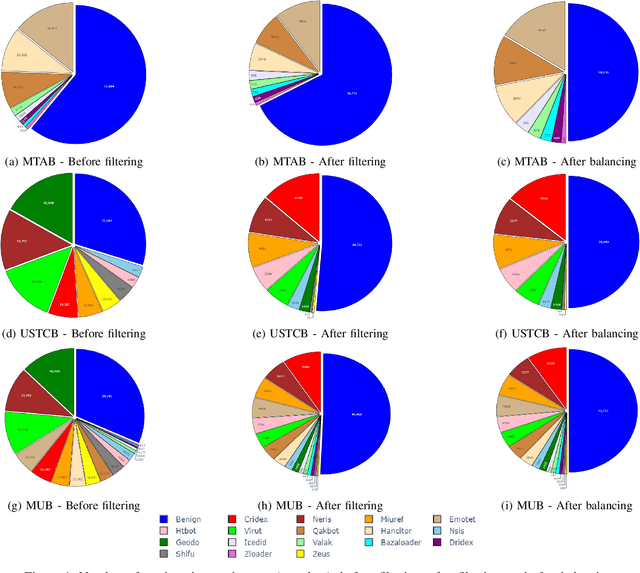
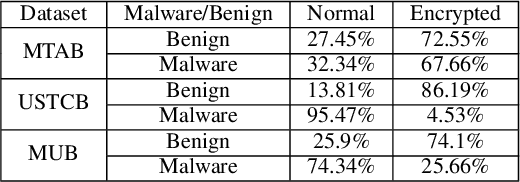
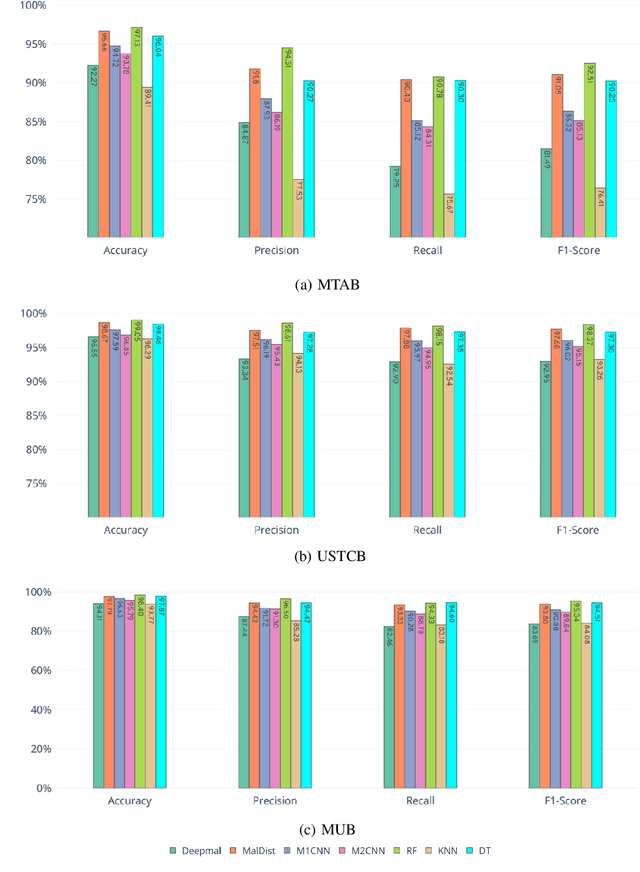
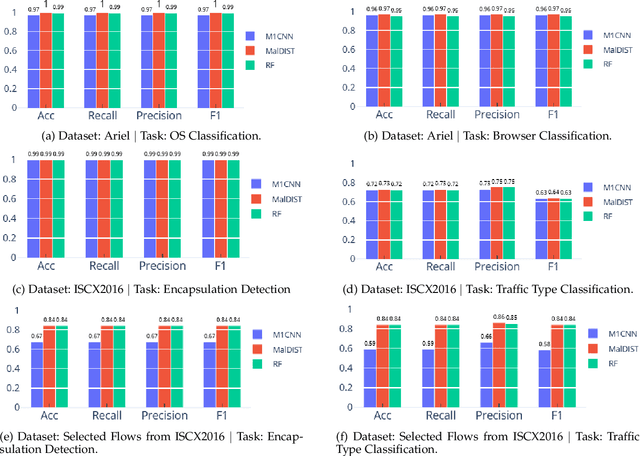
Internet traffic classification is widely used to facilitate network management. It plays a crucial role in Quality of Services (QoS), Quality of Experience (QoE), network visibility, intrusion detection, and traffic trend analyses. While there is no theoretical guarantee that deep learning (DL)-based solutions perform better than classic machine learning (ML)-based ones, DL-based models have become the common default. This paper compares well-known DL-based and ML-based models and shows that in the case of malicious traffic classification, state-of-the-art DL-based solutions do not necessarily outperform the classical ML-based ones. We exemplify this finding using two well-known datasets for a varied set of tasks, such as: malware detection, malware family classification, detection of zero-day attacks, and classification of an iteratively growing dataset. Note that, it is not feasible to evaluate all possible models to make a concrete statement, thus, the above finding is not a recommendation to avoid DL-based models, but rather empirical proof that in some cases, there are more simplistic solutions, that may perform even better.
MaMaDroid2.0 -- The Holes of Control Flow Graphs
Feb 28, 2022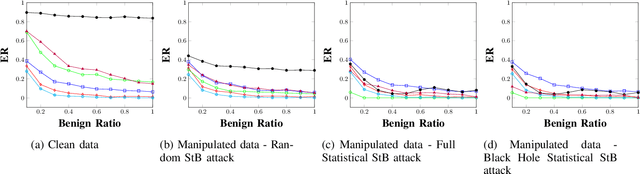
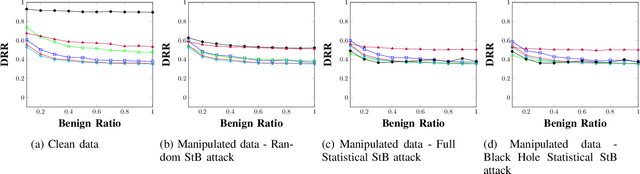
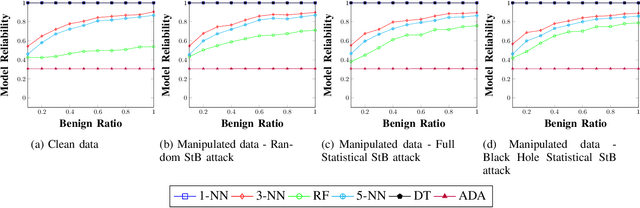
Android malware is a continuously expanding threat to billions of mobile users around the globe. Detection systems are updated constantly to address these threats. However, a backlash takes the form of evasion attacks, in which an adversary changes malicious samples such that those samples will be misclassified as benign. This paper fully inspects a well-known Android malware detection system, MaMaDroid, which analyzes the control flow graph of the application. Changes to the portion of benign samples in the train set and models are considered to see their effect on the classifier. The changes in the ratio between benign and malicious samples have a clear effect on each one of the models, resulting in a decrease of more than 40% in their detection rate. Moreover, adopted ML models are implemented as well, including 5-NN, Decision Tree, and Adaboost. Exploration of the six models reveals a typical behavior in different cases, of tree-based models and distance-based models. Moreover, three novel attacks that manipulate the CFG and their detection rates are described for each one of the targeted models. The attacks decrease the detection rate of most of the models to 0%, with regards to different ratios of benign to malicious apps. As a result, a new version of MaMaDroid is engineered. This model fuses the CFG of the app and static analysis of features of the app. This improved model is proved to be robust against evasion attacks targeting both CFG-based models and static analysis models, achieving a detection rate of more than 90% against each one of the attacks.
A Framework for Validating Models of Evasion Attacks on Machine Learning, with Application to Malware Detection
Jun 13, 2018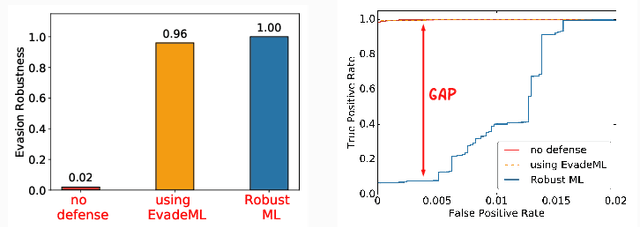
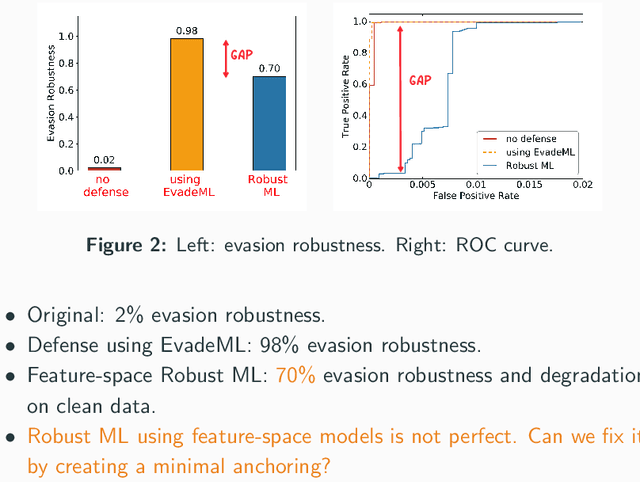
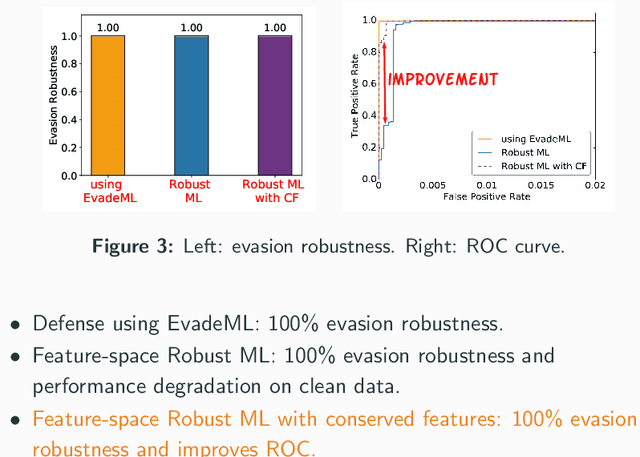
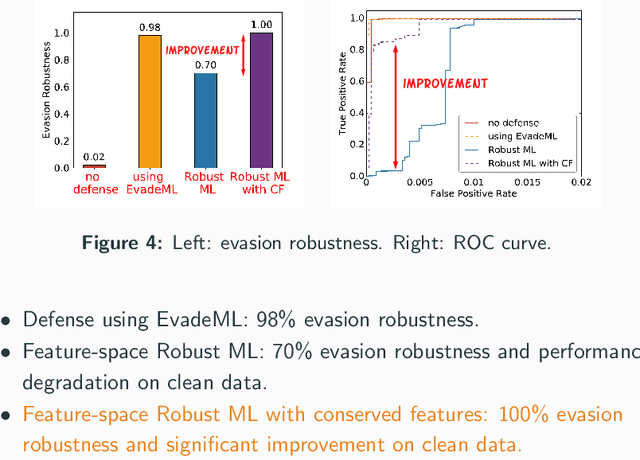
Machine learning (ML) techniques are increasingly common in security applications, such as malware and intrusion detection. However, there is increasing evidence that machine learning models are susceptible to evasion attacks, in which an adversary makes small changes to the input (such as malware) in order to cause erroneous predictions (for example, to avoid being detected). Evasion attacks on ML fall into two broad categories: 1) those which generate actual malicious instances and demonstrate both evasion of ML and efficacy of attack (we call these problem space attacks), and 2) attacks which directly manipulate features used by ML, abstracting efficacy of attack into a mathematical cost function (we call these feature space attacks). Central to our inquiry is the following fundamental question: are feature space models of attacks useful proxies for real attacks? In the process of answering this question, we make two major contributions: 1) a general methodology for evaluating validity of mathematical models of ML evasion attacks, and 2) an application of this methodology as a systematic hypothesis-driven evaluation of feature space evasion attacks on ML-based PDF malware detectors. Specific to our case study, we find that a) feature space evasion models are in general not adequate in representing real attacks, b) such models can be significantly improved by identifying conserved features (features that are invariant in real attacks) whenever these exist, and c) ML hardened using the improved feature space models remains robust to alternative attacks, in contrast to ML hardened using a very powerful class of problem space attacks, which does not.