 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Framework for Encrypted Internet and Malicious Traffic Classification
Jun 21, 2022
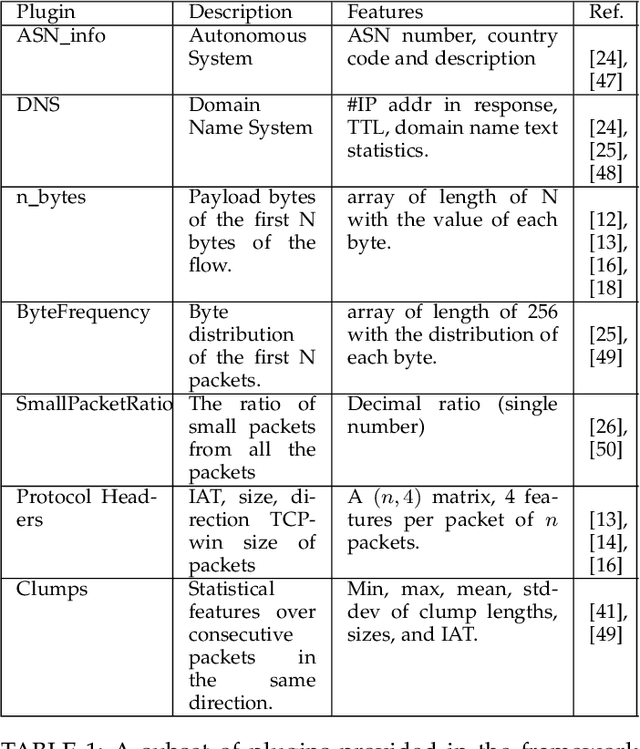
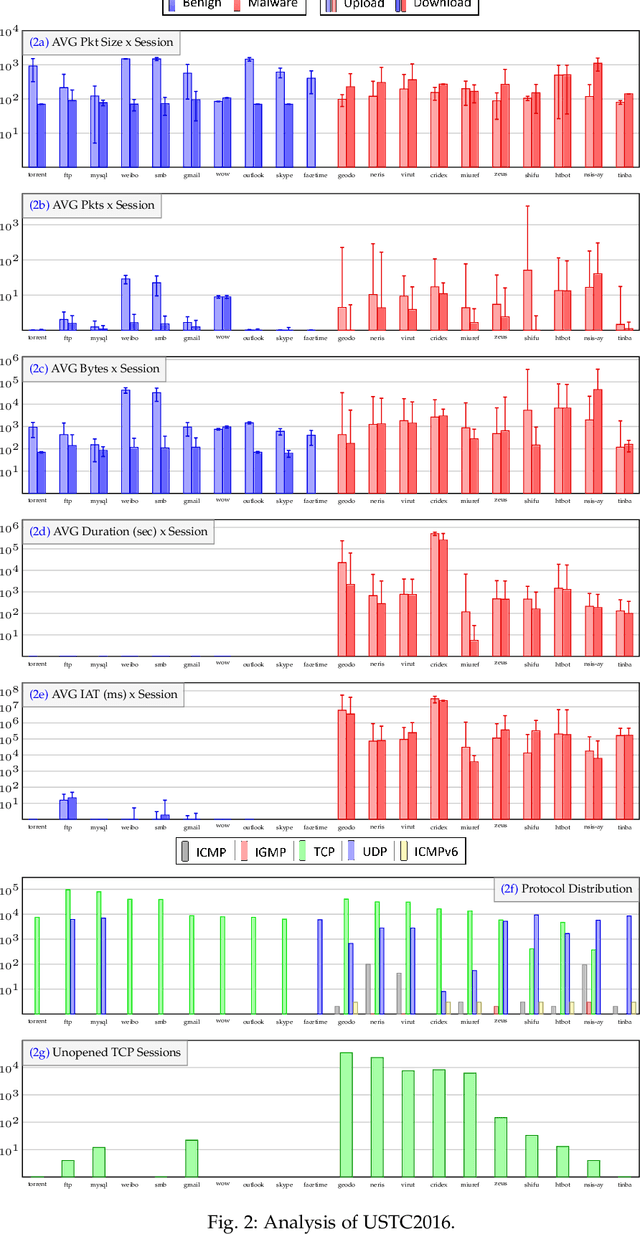
Internet traffic classification plays a key role in network visibility, Quality of Services (QoS), intrusion detection, Quality of Experience (QoE) and traffic-trend analyses. In order to improve privacy, integrity, confidentiality, and protocol obfuscation, the current traffic is based on encryption protocols, e.g., SSL/TLS. With the increased use of Machine-Learning (ML) and Deep-Learning (DL) models in the literature, comparison between different models and methods has become cumbersome and difficult due to a lack of a standardized framework. In this paper, we propose an open-source framework, named OSF-EIMTC, which can provide the full pipeline of the learning process. From the well-known datasets to extracting new and well-known features, it provides implementations of well-known ML and DL models (from the traffic classification literature) as well as evaluations. Such a framework can facilitate research in traffic classification domains, so that it will be more repeatable, reproducible, easier to execute, and will allow a more accurate comparison of well-known and novel features and models. As part of our framework evaluation, we demonstrate a variety of cases where the framework can be of use, utilizing multiple datasets, models, and feature sets. We show analyses of publicly available datasets and invite the community to participate in our open challenges using the OSF-EIMTC.
When a RF Beats a CNN and GRU, Together -- A Comparison of Deep Learning and Classical Machine Learning Approaches for Encrypted Malware Traffic Classification
Jun 16, 2022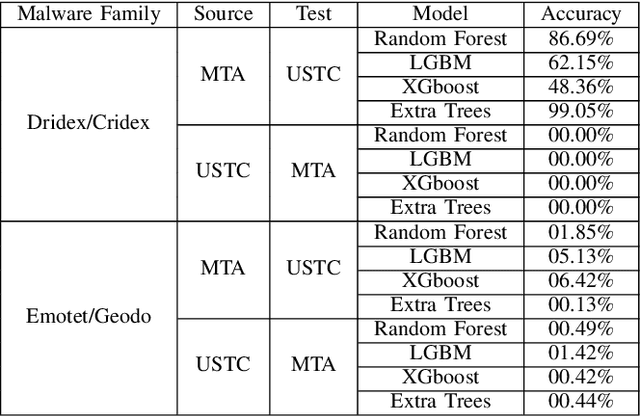
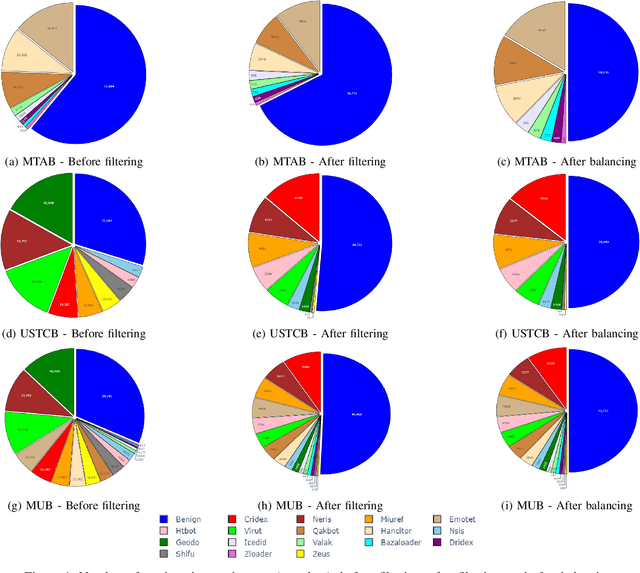
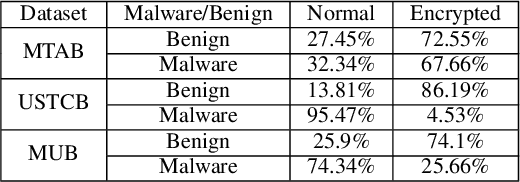
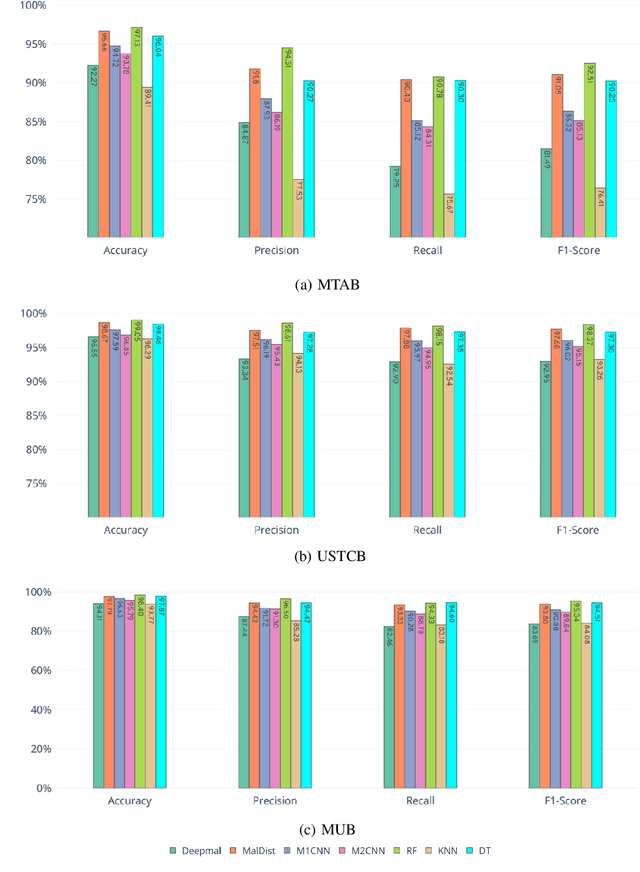
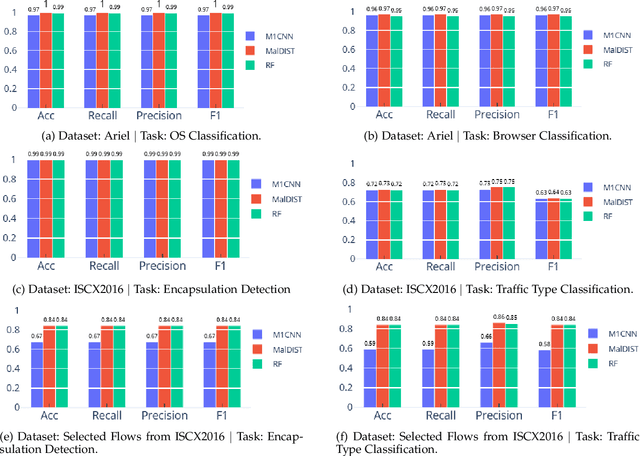
Internet traffic classification is widely used to facilitate network management. It plays a crucial role in Quality of Services (QoS), Quality of Experience (QoE), network visibility, intrusion detection, and traffic trend analyses. While there is no theoretical guarantee that deep learning (DL)-based solutions perform better than classic machine learning (ML)-based ones, DL-based models have become the common default. This paper compares well-known DL-based and ML-based models and shows that in the case of malicious traffic classification, state-of-the-art DL-based solutions do not necessarily outperform the classical ML-based ones. We exemplify this finding using two well-known datasets for a varied set of tasks, such as: malware detection, malware family classification, detection of zero-day attacks, and classification of an iteratively growing dataset. Note that, it is not feasible to evaluate all possible models to make a concrete statement, thus, the above finding is not a recommendation to avoid DL-based models, but rather empirical proof that in some cases, there are more simplistic solutions, that may perform even better.