 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen a RF Beats a CNN and GRU, Together -- A Comparison of Deep Learning and Classical Machine Learning Approaches for Encrypted Malware Traffic Classification
Paper and Code
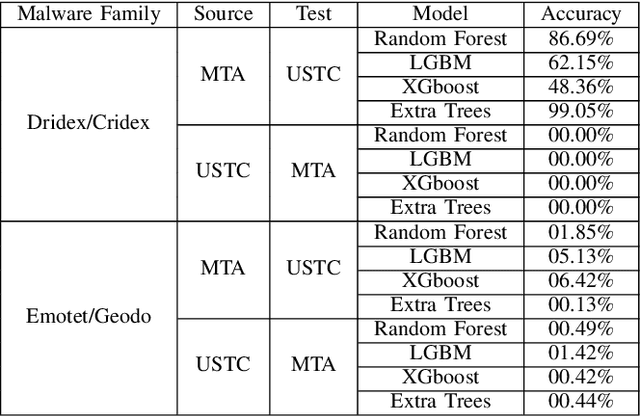
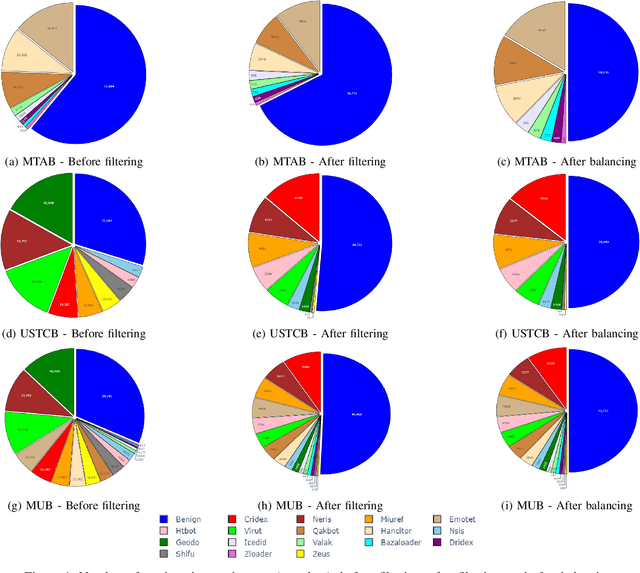
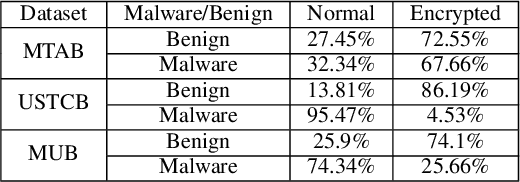
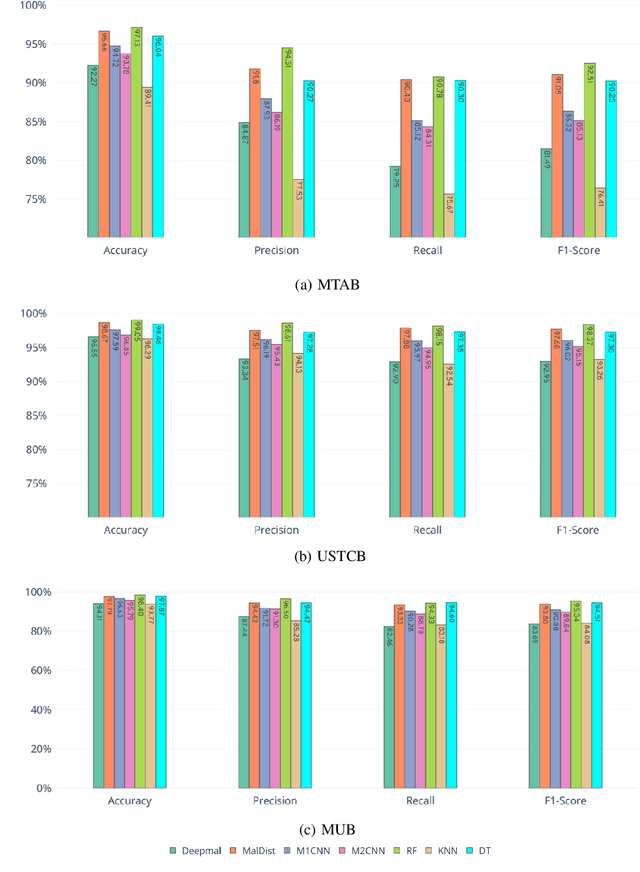
Internet traffic classification is widely used to facilitate network management. It plays a crucial role in Quality of Services (QoS), Quality of Experience (QoE), network visibility, intrusion detection, and traffic trend analyses. While there is no theoretical guarantee that deep learning (DL)-based solutions perform better than classic machine learning (ML)-based ones, DL-based models have become the common default. This paper compares well-known DL-based and ML-based models and shows that in the case of malicious traffic classification, state-of-the-art DL-based solutions do not necessarily outperform the classical ML-based ones. We exemplify this finding using two well-known datasets for a varied set of tasks, such as: malware detection, malware family classification, detection of zero-day attacks, and classification of an iteratively growing dataset. Note that, it is not feasible to evaluate all possible models to make a concrete statement, thus, the above finding is not a recommendation to avoid DL-based models, but rather empirical proof that in some cases, there are more simplistic solutions, that may perform even better.