 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing high-content imaging for studying microtubule networks at large-scale
Oct 01, 2019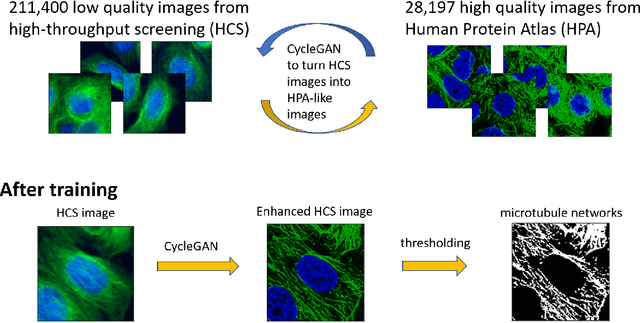
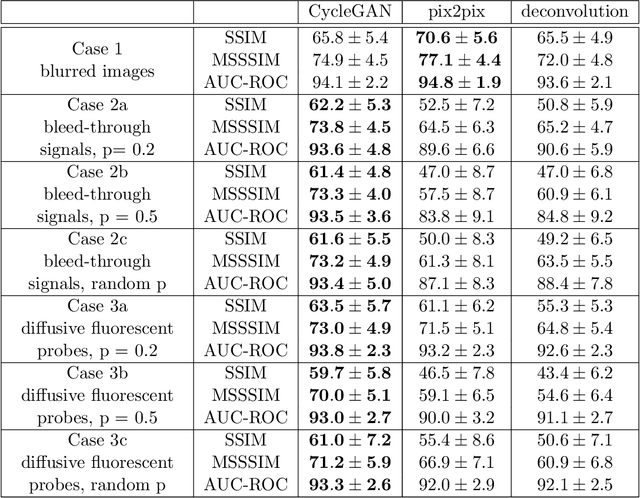
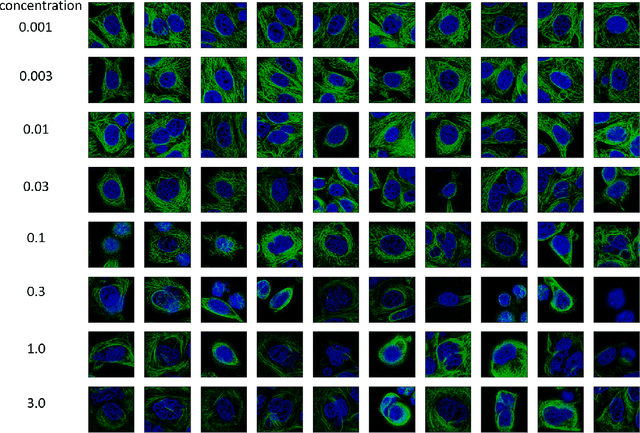
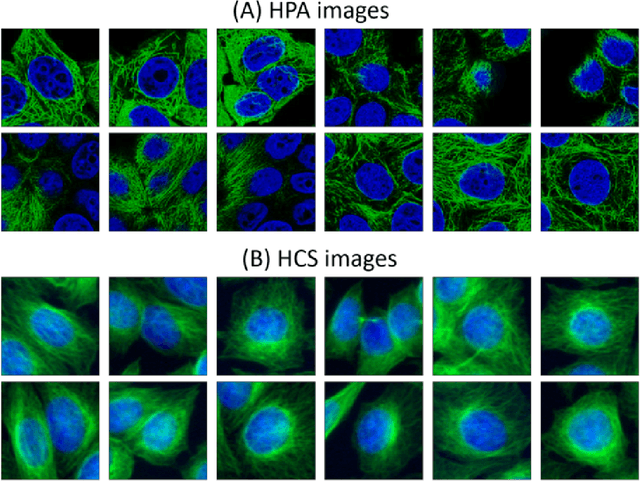
Given the crucial role of microtubules for cell survival, many researchers have found success using microtubule-targeting agents in the search for effective cancer therapeutics. Understanding microtubule responses to targeted interventions requires that the microtubule network within cells can be consistently observed across a large sample of images. However, fluorescence noise sources captured simultaneously with biological signals while using wide-field microscopes can obfuscate fine microtubule structures. Such requirements are particularly challenging for high-throughput imaging, where researchers must make decisions related to the trade-off between imaging quality and speed. Here, we propose a computational framework to enhance the quality of high-throughput imaging data to achieve fast speed and high quality simultaneously. Using CycleGAN, we learn an image model from low-throughput, high-resolution images to enhance features, such as microtubule networks in high-throughput low-resolution images. We show that CycleGAN is effective in identifying microtubules with 0.93+ AUC-ROC and that these results are robust to different kinds of image noise. We further apply CycleGAN to quantify the changes in microtubule density as a result of the application of drug compounds, and show that the quantified responses correspond well with known drug effects
Natural Language Processing of Clinical Notes on Chronic Diseases: Systematic Review
Aug 15, 2019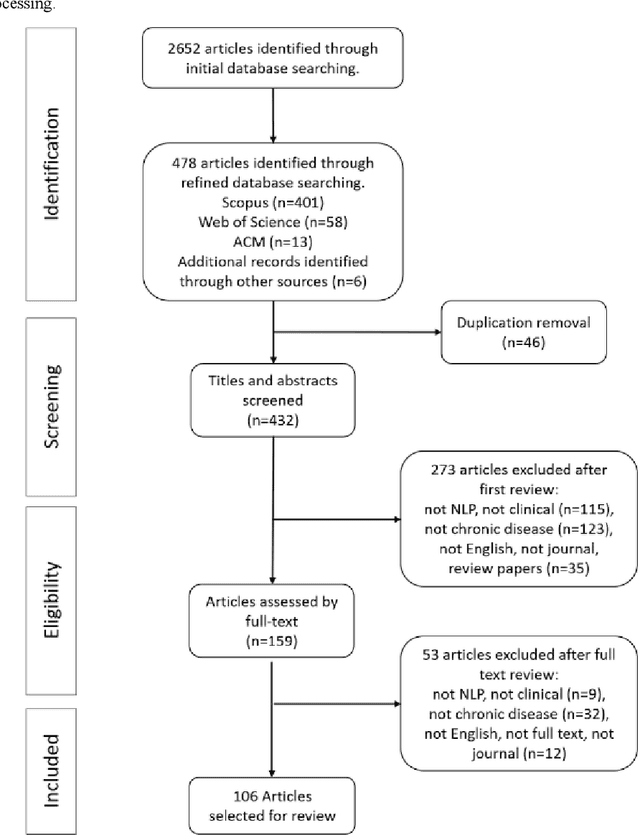

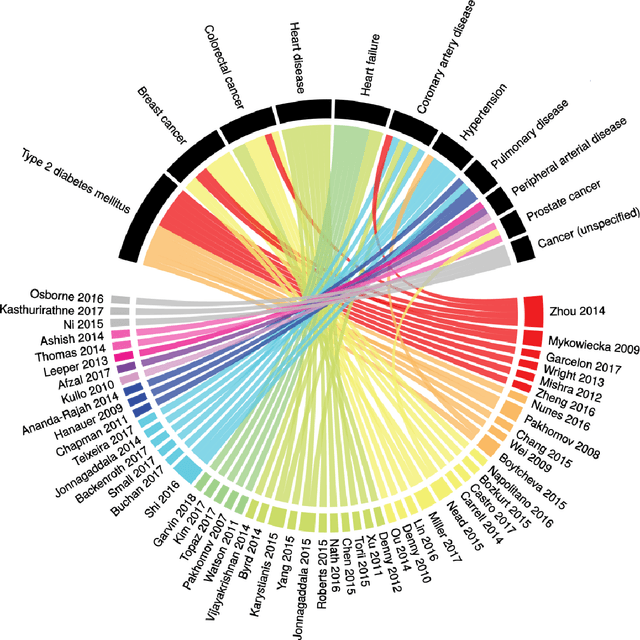

Of the 2652 articles considered, 106 met the inclusion criteria. Review of the included papers resulted in identification of 43 chronic diseases, which were then further classified into 10 disease categories using ICD-10. The majority of studies focused on diseases of the circulatory system (n=38) while endocrine and metabolic diseases were fewest (n=14). This was due to the structure of clinical records related to metabolic diseases, which typically contain much more structured data, compared with medical records for diseases of the circulatory system, which focus more on unstructured data and consequently have seen a stronger focus of NLP. The review has shown that there is a significant increase in the use of machine learning methods compared to rule-based approaches; however, deep learning methods remain emergent (n=3). Consequently, the majority of works focus on classification of disease phenotype with only a handful of papers addressing extraction of comorbidities from the free text or integration of clinical notes with structured data. There is a notable use of relatively simple methods, such as shallow classifiers (or combination with rule-based methods), due to the interpretability of predictions, which still represents a significant issue for more complex methods. Finally, scarcity of publicly available data may also have contributed to insufficient development of more advanced methods, such as extraction of word embeddings from clinical notes. Further efforts are still required to improve (1) progression of clinical NLP methods from extraction toward understanding; (2) recognition of relations among entities rather than entities in isolation; (3) temporal extraction to understand past, current, and future clinical events; (4) exploitation of alternative sources of clinical knowledge; and (5) availability of large-scale, de-identified clinical corpora.
* Supplementary material detailing articles reviewed, classification of diseases and associated algorithms, can be found at: http://venetosmani.com/research/publications.html