 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Complexity Prediction: An Overview
Paper and Code
Mar 08, 2023

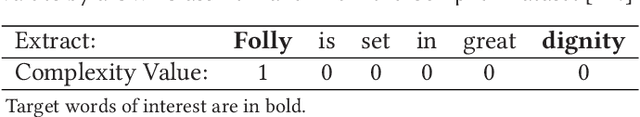

The occurrence of unknown words in texts significantly hinders reading comprehension. To improve accessibility for specific target populations, computational modelling has been applied to identify complex words in texts and substitute them for simpler alternatives. In this paper, we present an overview of computational approaches to lexical complexity prediction focusing on the work carried out on English data. We survey relevant approaches to this problem which include traditional machine learning classifiers (e.g. SVMs, logistic regression) and deep neural networks as well as a variety of features, such as those inspired by literature in psycholinguistics as well as word frequency, word length, and many others. Furthermore, we introduce readers to past competitions and available datasets created on this topic. Finally, we include brief sections on applications of lexical complexity prediction, such as readability and text simplification, together with related studies on languages other than English.