 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequentist Consistency of Prior-Data Fitted Networks for Causal Inference
Mar 12, 2026Foundation models based on prior-data fitted networks (PFNs) have shown strong empirical performance in causal inference by framing the task as an in-context learning problem.However, it is unclear whether PFN-based causal estimators provide uncertainty quantification that is consistent with classical frequentist estimators. In this work, we address this gap by analyzing the frequentist consistency of PFN-based estimators for the average treatment effect (ATE). (1) We show that existing PFNs, when interpreted as Bayesian ATE estimators, can exhibit prior-induced confounding bias: the prior is not asymptotically overwritten by data, which, in turn, prevents frequentist consistency. (2) As a remedy, we suggest employing a calibration procedure based on a one-step posterior correction (OSPC). We show that the OSPC helps to restore frequentist consistency and can yield a semi-parametric Bernstein-von Mises theorem for calibrated PFNs (i.e., both the calibrated PFN-based estimators and the classical semi-parametric efficient estimators converge in distribution with growing data size). (3) Finally, we implement OSPC through tailoring martingale posteriors on top of the PFNs. In this way, we are able to recover functional nuisance posteriors from PFNs, required by the OSPC. In multiple (semi-)synthetic experiments, PFNs calibrated with our martingale posterior OSPC produce ATE uncertainty that (i) asymptotically matches frequentist uncertainty and (ii) is well calibrated in finite samples in comparison to other Bayesian ATE estimators.
CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
Jun 09, 2025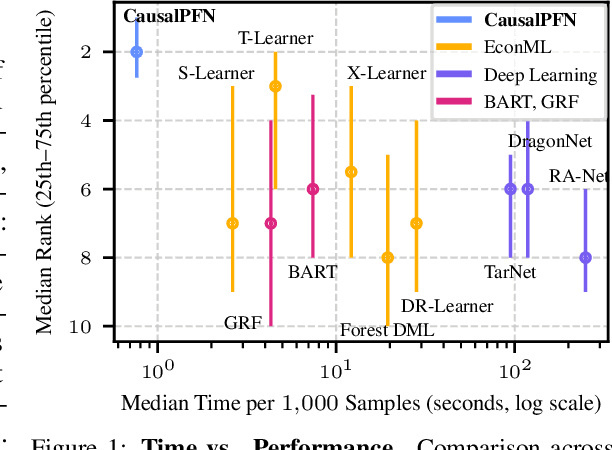
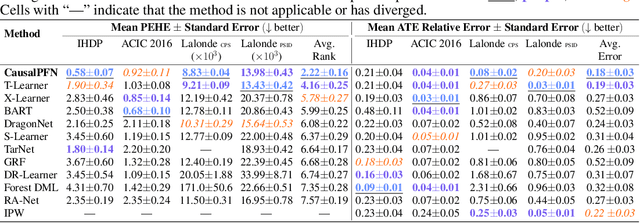
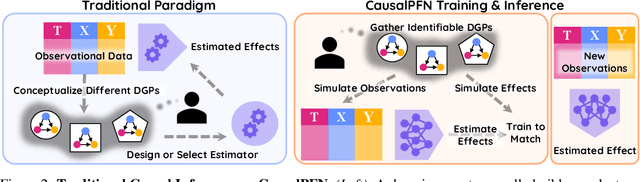
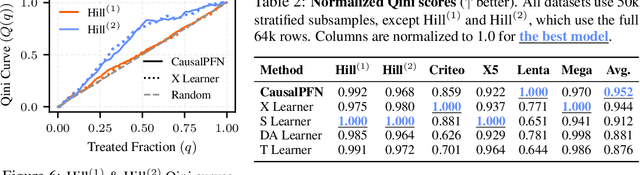
Causal effect estimation from observational data is fundamental across various applications. However, selecting an appropriate estimator from dozens of specialized methods demands substantial manual effort and domain expertise. We present CausalPFN, a single transformer that amortizes this workflow: trained once on a large library of simulated data-generating processes that satisfy ignorability, it infers causal effects for new observational datasets out-of-the-box. CausalPFN combines ideas from Bayesian causal inference with the large-scale training protocol of prior-fitted networks (PFNs), learning to map raw observations directly to causal effects without any task-specific adjustment. Our approach achieves superior average performance on heterogeneous and average treatment effect estimation benchmarks (IHDP, Lalonde, ACIC). Moreover, it shows competitive performance for real-world policy making on uplift modeling tasks. CausalPFN provides calibrated uncertainty estimates to support reliable decision-making based on Bayesian principles. This ready-to-use model does not require any further training or tuning and takes a step toward automated causal inference (https://github.com/vdblm/CausalPFN).
Red Teaming Large Language Models for Healthcare
May 01, 2025We present the design process and findings of the pre-conference workshop at the Machine Learning for Healthcare Conference (2024) entitled Red Teaming Large Language Models for Healthcare, which took place on August 15, 2024. Conference participants, comprising a mix of computational and clinical expertise, attempted to discover vulnerabilities -- realistic clinical prompts for which a large language model (LLM) outputs a response that could cause clinical harm. Red-teaming with clinicians enables the identification of LLM vulnerabilities that may not be recognised by LLM developers lacking clinical expertise. We report the vulnerabilities found, categorise them, and present the results of a replication study assessing the vulnerabilities across all LLMs provided.
Synthetic Vision: Training Vision-Language Models to Understand Physics
Dec 11, 2024



Physical reasoning, which involves the interpretation, understanding, and prediction of object behavior in dynamic environments, remains a significant challenge for current Vision-Language Models (VLMs). In this work, we propose two methods to enhance VLMs' physical reasoning capabilities using simulated data. First, we fine-tune a pre-trained VLM using question-answer (QA) pairs generated from simulations relevant to physical reasoning tasks. Second, we introduce Physics Context Builders (PCBs), specialized VLMs fine-tuned to create scene descriptions enriched with physical properties and processes. During physical reasoning tasks, these PCBs can be leveraged as context to assist a Large Language Model (LLM) to improve its performance. We evaluate both of our approaches using multiple benchmarks, including a new stability detection QA dataset called Falling Tower, which includes both simulated and real-world scenes, and CLEVRER. We demonstrate that a small QA fine-tuned VLM can significantly outperform larger state-of-the-art foundational models. We also show that integrating PCBs boosts the performance of foundational LLMs on physical reasoning tasks. Using the real-world scenes from the Falling Tower dataset, we also validate the robustness of both approaches in Sim2Real transfer. Our results highlight the utility that simulated data can have in the creation of learning systems capable of advanced physical reasoning.
Personalized Adaptation via In-Context Preference Learning
Oct 17, 2024

Reinforcement Learning from Human Feedback (RLHF) is widely used to align Language Models (LMs) with human preferences. However, existing approaches often neglect individual user preferences, leading to suboptimal personalization. We present the Preference Pretrained Transformer (PPT), a novel approach for adaptive personalization using online user feedback. PPT leverages the in-context learning capabilities of transformers to dynamically adapt to individual preferences. Our approach consists of two phases: (1) an offline phase where we train a single policy model using a history-dependent loss function, and (2) an online phase where the model adapts to user preferences through in-context learning. We demonstrate PPT's effectiveness in a contextual bandit setting, showing that it achieves personalized adaptation superior to existing methods while significantly reducing the computational costs. Our results suggest the potential of in-context learning for scalable and efficient personalization in large language models.
Sequential Decision Making with Expert Demonstrations under Unobserved Heterogeneity
Apr 10, 2024We study the problem of online sequential decision-making given auxiliary demonstrations from experts who made their decisions based on unobserved contextual information. These demonstrations can be viewed as solving related but slightly different tasks than what the learner faces. This setting arises in many application domains, such as self-driving cars, healthcare, and finance, where expert demonstrations are made using contextual information, which is not recorded in the data available to the learning agent. We model the problem as a zero-shot meta-reinforcement learning setting with an unknown task distribution and a Bayesian regret minimization objective, where the unobserved tasks are encoded as parameters with an unknown prior. We propose the Experts-as-Priors algorithm (ExPerior), a non-parametric empirical Bayes approach that utilizes the principle of maximum entropy to establish an informative prior over the learner's decision-making problem. This prior enables the application of any Bayesian approach for online decision-making, such as posterior sampling. We demonstrate that our strategy surpasses existing behaviour cloning and online algorithms for multi-armed bandits and reinforcement learning, showcasing the utility of our approach in leveraging expert demonstrations across different decision-making setups.
OCDaf: Ordered Causal Discovery with Autoregressive Flows
Aug 14, 2023



We propose OCDaf, a novel order-based method for learning causal graphs from observational data. We establish the identifiability of causal graphs within multivariate heteroscedastic noise models, a generalization of additive noise models that allow for non-constant noise variances. Drawing upon the structural similarities between these models and affine autoregressive normalizing flows, we introduce a continuous search algorithm to find causal structures. Our experiments demonstrate state-of-the-art performance across the Sachs and SynTReN benchmarks in Structural Hamming Distance (SHD) and Structural Intervention Distance (SID). Furthermore, we validate our identifiability theory across various parametric and nonparametric synthetic datasets and showcase superior performance compared to existing baselines.
Partial Identification of Treatment Effects with Implicit Generative Models
Oct 14, 2022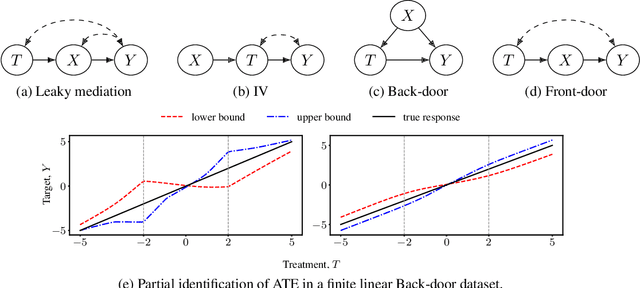

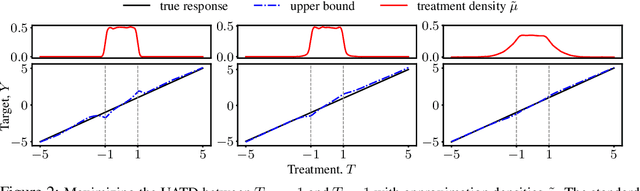
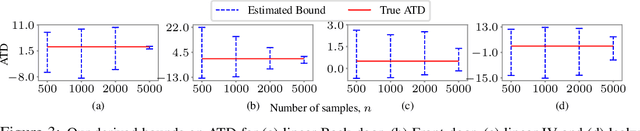
We consider the problem of partial identification, the estimation of bounds on the treatment effects from observational data. Although studied using discrete treatment variables or in specific causal graphs (e.g., instrumental variables), partial identification has been recently explored using tools from deep generative modeling. We propose a new method for partial identification of average treatment effects(ATEs) in general causal graphs using implicit generative models comprising continuous and discrete random variables. Since ATE with continuous treatment is generally non-regular, we leverage the partial derivatives of response functions to define a regular approximation of ATE, a quantity we call uniform average treatment derivative (UATD). We prove that our algorithm converges to tight bounds on ATE in linear structural causal models (SCMs). For nonlinear SCMs, we empirically show that using UATD leads to tighter and more stable bounds than methods that directly optimize the ATE.