 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Design of Continuum Robots with Reachability Constraints
Mar 14, 2025While multi-joint continuum robots are highly dexterous and flexible, designing an optimal robot can be challenging due to its kinematics involving curvatures. Hence, the current work presents a computational method developed to find optimal designs of continuum robots given reachability constraints. First, we leverage both forward and inverse kinematic computations to perform reachability analysis in an efficient yet accurate manner. While implementing inverse kinematics, we also integrate torque minimization at joints such that robot configurations with the minimum actuator torque required to reach a given workspace could be found. Lastly, we apply an estimation of distribution algorithm (EDA) to find optimal robot dimensions while considering reachability, where the objective function could be the total length of the robot or the actuator torque required to operate the robot. Through three application problems, we show that the EDA is superior to a genetic algorithm (GA) in finding better solutions within a given number of iterations, as the objective values of the best solutions found by the EDA are 4-15\% lower than those found by the GA.
Configuration Design of Mechanical Assemblies using an Estimation of Distribution Algorithm and Constraint Programming
Mar 14, 2025A configuration design problem in mechanical engineering involves finding an optimal assembly of components and joints that realizes some desired performance criteria. Such a problem is a discrete, constrained, and black-box optimization problem. A novel method is developed to solve the problem by applying Bivariate Marginal Distribution Algorithm (BMDA) and constraint programming (CP). BMDA is a type of Estimation of Distribution Algorithm (EDA) that exploits the dependency knowledge learned between design variables without requiring too many fitness evaluations, which tend to be expensive for the current application. BMDA is extended with adaptive chi-square testing to identify dependencies and Gibbs sampling to generate new solutions. Also, repair operations based on CP are used to deal with infeasible solutions found during search. The method is applied to a vehicle suspension design problem and is found to be more effective in converging to good solutions than a genetic algorithm and other EDAs. These contributions are significant steps towards solving the difficult problem of configuration design in mechanical engineering with evolutionary computation.
Physics-based simulation ontology: an ontology to support modelling and reuse of data for physics-based simulation
Mar 14, 2025The current work presents an ontology developed for physics-based simulation in engineering design, called Physics-based Simulation Ontology (PSO). The purpose of the ontology is to assist in modelling the physical phenomenon of interest in a veridical manner, while capturing the necessary and reusable information for physics-based simulation solvers. The development involved extending an existing upper ontology, Basic Formal Ontology (BFO), to define lower-level terms of PSO. PSO has two parts: PSO-Physics, which consists of terms and relations used to model physical phenomena based on the perspective of classical mechanics involving partial differential equations, and PSO-Sim, which consists of terms used to represent the information artefacts that are about the physical phenomena modelled with PSO-Physics. The former terms are used to model the physical phenomenon of interest independent of solver-specific interpretations, which can be reused across different solvers, while the latter terms are used to instantiate solver-specific input data. A case study involving two simulation solvers was conducted to demonstrate this capability of PSO. Discussion around the benefits and limitations of using BFO for the current work is also provided, which should be valuable for any future work that extends an existing upper ontology to develop ontologies for engineering applications.
mPOLICE: Provable Enforcement of Multi-Region Affine Constraints in Deep Neural Networks
Feb 04, 2025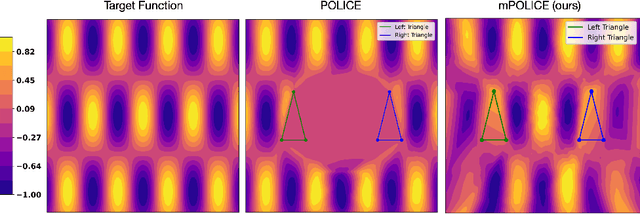


Deep neural networks are increasingly employed in fields such as climate modeling, robotics, and industrial control, where strict output constraints must be upheld. Although prior methods like the POLICE algorithm can enforce affine constraints in a single convex region by adjusting network parameters, they struggle with multiple disjoint regions, often leading to conflicts or unintended affine extensions. We present mPOLICE, a new method that extends POLICE to handle constraints imposed on multiple regions. mPOLICE assigns a distinct activation pattern to each constrained region, preserving exact affine behavior locally while avoiding overreach into other parts of the input domain. We formulate a layer-wise optimization problem that adjusts both the weights and biases to assign unique activation patterns to each convex region, ensuring that constraints are met without conflicts, while maintaining the continuity and smoothness of the learned function. Our experiments show the enforcement of multi-region constraints for multiple scenarios, including regression and classification, function approximation, and non-convex regions through approximation. Notably, mPOLICE adds zero inference overhead and minimal training overhead.
e-SimFT: Alignment of Generative Models with Simulation Feedback for Pareto-Front Design Exploration
Feb 04, 2025



Deep generative models have recently shown success in solving complex engineering design problems where models predict solutions that address the design requirements specified as input. However, there remains a challenge in aligning such models for effective design exploration. For many design problems, finding a solution that meets all the requirements is infeasible. In such a case, engineers prefer to obtain a set of Pareto optimal solutions with respect to those requirements, but uniform sampling of generative models may not yield a useful Pareto front. To address this gap, we introduce a new framework for Pareto-front design exploration with simulation fine-tuned generative models. First, the framework adopts preference alignment methods developed for Large Language Models (LLMs) and showcases the first application in fine-tuning a generative model for engineering design. The important distinction here is that we use a simulator instead of humans to provide accurate and scalable feedback. Next, we propose epsilon-sampling, inspired by the epsilon-constraint method used for Pareto-front generation with classical optimization algorithms, to construct a high-quality Pareto front with the fine-tuned models. Our framework, named e-SimFT, is shown to produce better-quality Pareto fronts than existing multi-objective alignment methods.
Synthetic Vision: Training Vision-Language Models to Understand Physics
Dec 11, 2024



Physical reasoning, which involves the interpretation, understanding, and prediction of object behavior in dynamic environments, remains a significant challenge for current Vision-Language Models (VLMs). In this work, we propose two methods to enhance VLMs' physical reasoning capabilities using simulated data. First, we fine-tune a pre-trained VLM using question-answer (QA) pairs generated from simulations relevant to physical reasoning tasks. Second, we introduce Physics Context Builders (PCBs), specialized VLMs fine-tuned to create scene descriptions enriched with physical properties and processes. During physical reasoning tasks, these PCBs can be leveraged as context to assist a Large Language Model (LLM) to improve its performance. We evaluate both of our approaches using multiple benchmarks, including a new stability detection QA dataset called Falling Tower, which includes both simulated and real-world scenes, and CLEVRER. We demonstrate that a small QA fine-tuned VLM can significantly outperform larger state-of-the-art foundational models. We also show that integrating PCBs boosts the performance of foundational LLMs on physical reasoning tasks. Using the real-world scenes from the Falling Tower dataset, we also validate the robustness of both approaches in Sim2Real transfer. Our results highlight the utility that simulated data can have in the creation of learning systems capable of advanced physical reasoning.
Deep Generative Model for Mechanical System Configuration Design
Sep 09, 2024



Generative AI has made remarkable progress in addressing various design challenges. One prominent area where generative AI could bring significant value is in engineering design. In particular, selecting an optimal set of components and their interfaces to create a mechanical system that meets design requirements is one of the most challenging and time-consuming tasks for engineers. This configuration design task is inherently challenging due to its categorical nature, multiple design requirements a solution must satisfy, and the reliance on physics simulations for evaluating potential solutions. These characteristics entail solving a combinatorial optimization problem with multiple constraints involving black-box functions. To address this challenge, we propose a deep generative model to predict the optimal combination of components and interfaces for a given design problem. To demonstrate our approach, we solve a gear train synthesis problem by first creating a synthetic dataset using a grammar, a parts catalogue, and a physics simulator. We then train a Transformer using this dataset, named GearFormer, which can not only generate quality solutions on its own, but also augment search methods such as an evolutionary algorithm and Monte Carlo tree search. We show that GearFormer outperforms such search methods on their own in terms of satisfying the specified design requirements with orders of magnitude faster generation time. Additionally, we showcase the benefit of hybrid methods that leverage both GearFormer and search methods, which further improve the quality of the solutions.
DesignQA: A Multimodal Benchmark for Evaluating Large Language Models' Understanding of Engineering Documentation
Apr 11, 2024



This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.