 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Tree Detection in Large-Scale Urban Environments using High-Resolution Multispectral Imagery
Aug 24, 2022


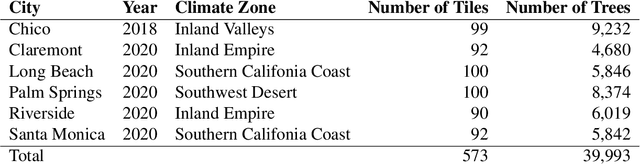
We introduce a novel deep learning method for detection of individual trees in urban environments using high-resolution multispectral aerial imagery. We use a convolutional neural network to regress a confidence map indicating the locations of individual trees, which are localized using a peak finding algorithm. Our method provides complete spatial coverage by detecting trees in both public and private spaces, and can scale to very large areas. In our study area spanning five cities in Southern California, we achieved an F-score of 0.735 and an RMSE of 2.157 m. We used our method to produce a map of all trees in the urban forest of California, indicating the potential for our method to support future urban forestry studies at unprecedented scales.
P1AC: Revisiting Absolute Pose From a Single Affine Correspondence
Nov 17, 2020


We introduce a novel solution to the problem of estimating the pose of a calibrated camera given a single observation of an oriented point and an affine correspondence to a reference image. Affine correspondences have traditionally been used to improve feature matching over wide baselines; however, little previous work has considered the use of such correspondences for absolute camera pose computation. The advantage of our approach (P1AC) is that it requires only a single correspondence in the minimal case in comparison to the traditional point-based approach (P3P) which requires at least three points. Our method removes the limiting assumptions made in previous work and provides a general solution that is applicable to large-scale image-based localization. Our evaluation on synthetic data shows that our approach is numerically stable and more robust to point observation noise than P3P. We also evaluate the application of our approach for large-scale image-based localization and demonstrate a practical reduction in the number of iterations and computation time required to robustly localize an image.
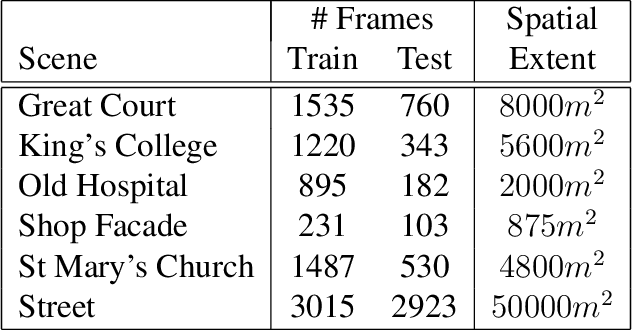
Unsupervised Learning of Depth and Ego-Motion from Cylindrical Panoramic Video with Applications for Virtual Reality
Nov 10, 2020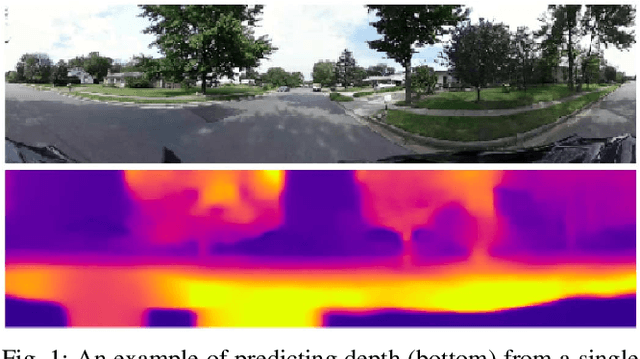
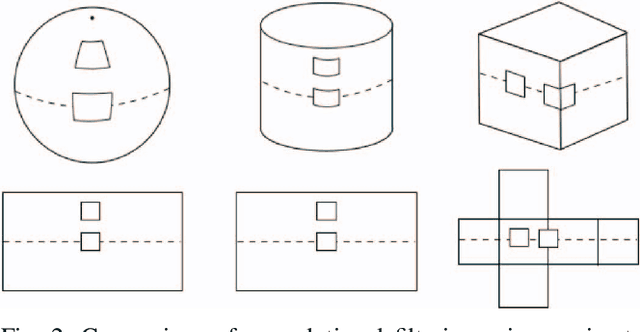

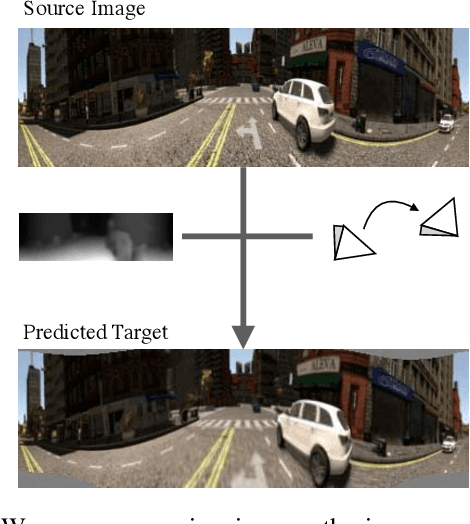
We introduce a convolutional neural network model for unsupervised learning of depth and ego-motion from cylindrical panoramic video. Panoramic depth estimation is an important technology for applications such as virtual reality, 3D modeling, and autonomous robotic navigation. In contrast to previous approaches for applying convolutional neural networks to panoramic imagery, we use the cylindrical panoramic projection which allows for the use of the traditional CNN layers such as convolutional filters and max pooling without modification. Our evaluation of synthetic and real data shows that unsupervised learning of depth and ego-motion on cylindrical panoramic images can produce high-quality depth maps and that an increased field-of-view improves ego-motion estimation accuracy. We create two new datasets to evaluate our approach: a synthetic dataset created using the CARLA simulator, and Headcam, a novel dataset of panoramic video collected from a helmet-mounted camera while biking in an urban setting. We also apply our network to the problem of converting monocular panoramas to stereo panoramas.
* Expansion on arXiv:1901.00979 for IJSC SI; correct table 1 and 3 headings, reduce file size
Self-Supervised Poisson-Gaussian Denoising
Feb 21, 2020
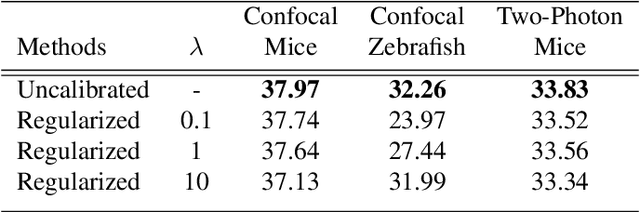
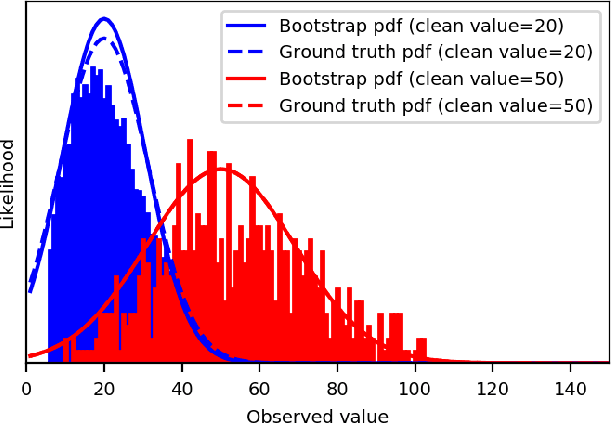
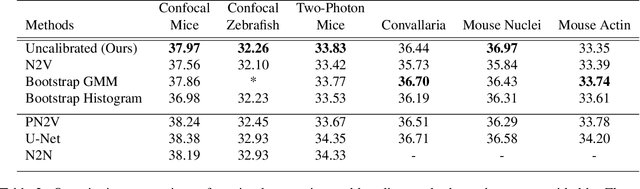
We extend the blindspot model for self-supervised denoising to handle Poisson-Gaussian noise and introduce an improved training scheme that avoids hyperparameters and adapts the denoiser to the test data. Self-supervised models for denoising learn to denoise from only noisy data and do not require corresponding clean images, which are difficult or impossible to acquire in some application areas of interest such as low-light microscopy. We introduce a new training strategy to handle Poisson-Gaussian noise which is the standard noise model for microscope images. Our new strategy eliminates hyperparameters from the loss function, which is important in a self-supervised regime where no ground truth data is available to guide hyperparameter tuning. We show how our denoiser can be adapted to the test data to improve performance. Our evaluation on a microscope image denoising benchmark validates our approach.
Unsupervised Learning of Depth and Ego-Motion from Panoramic Video
Jan 04, 2019

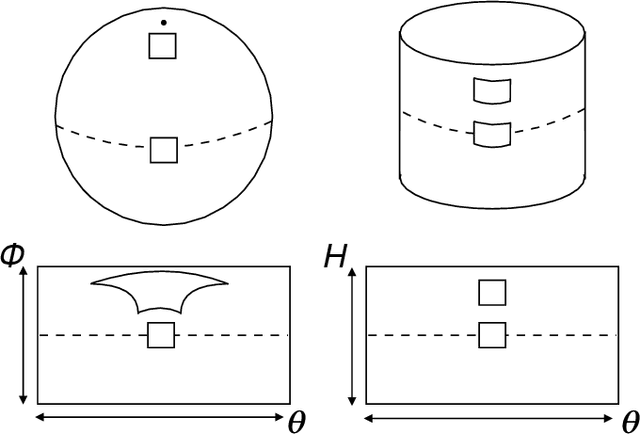

We introduce a convolutional neural network model for unsupervised learning of depth and ego-motion from cylindrical panoramic video. Panoramic depth estimation is an important technology for applications such as autonomous robotic navigation, virtual reality, and 3D modeling. In contrast to previous approaches for applying convolutional neural networks to panoramic imagery, we use the cylindrical panoramic projection which allows for the use of the traditional CNN layers such as convolutional filters and max pooling without modification. Our evaluation on synthetic and real data shows that unsupervised learning of depth and ego-motion on panoramic images increases depth prediction accuracy in comparison to training on perspective images which have a narrower field-of-view.
An Aggregated Multicolumn Dilated Convolution Network for Perspective-Free Counting
Apr 20, 2018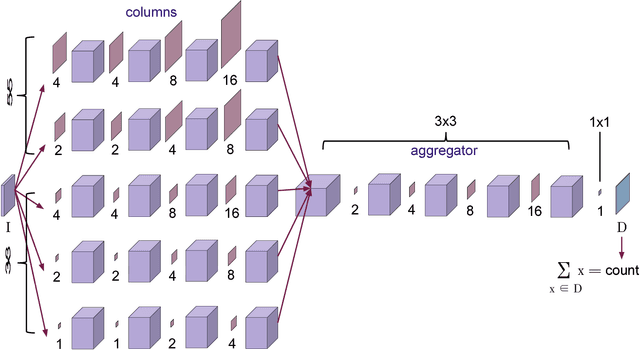
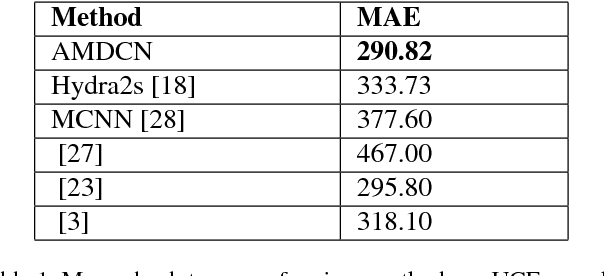

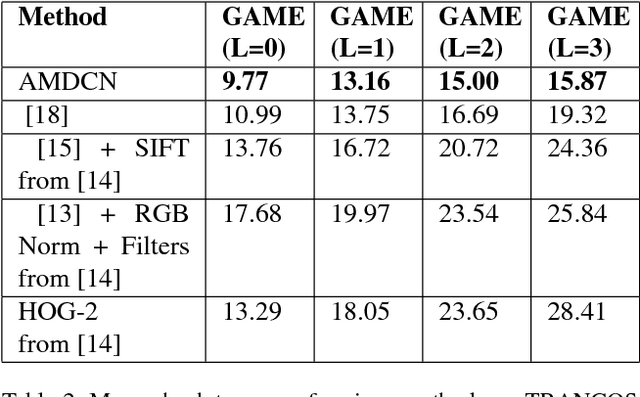
We propose the use of dilated filters to construct an aggregation module in a multicolumn convolutional neural network for perspective-free counting. Counting is a common problem in computer vision (e.g. traffic on the street or pedestrians in a crowd). Modern approaches to the counting problem involve the production of a density map via regression whose integral is equal to the number of objects in the image. However, objects in the image can occur at different scales (e.g. due to perspective effects) which can make it difficult for a learning agent to learn the proper density map. While the use of multiple columns to extract multiscale information from images has been shown before, our approach aggregates the multiscale information gathered by the multicolumn convolutional neural network to improve performance. Our experiments show that our proposed network outperforms the state-of-the-art on many benchmark datasets, and also that using our aggregation module in combination with a higher number of columns is beneficial for multiscale counting.
Structure from Motion on a Sphere
Sep 05, 2016


We describe a special case of structure from motion where the camera rotates on a sphere. The camera's optical axis lies perpendicular to the sphere's surface. In this case, the camera's pose is minimally represented by three rotation parameters. From analysis of the epipolar geometry we derive a novel and efficient solution for the essential matrix relating two images, requiring only three point correspondences in the minimal case. We apply this solver in a structure-from-motion pipeline that aggregates pairwise relations by rotation averaging followed by bundle adjustment with an inverse depth parameterization. Our methods enable scene modeling with an outward-facing camera and object scanning with an inward-facing camera.
Global 6DOF Pose Estimation from Untextured 2D City Models
Mar 18, 2015

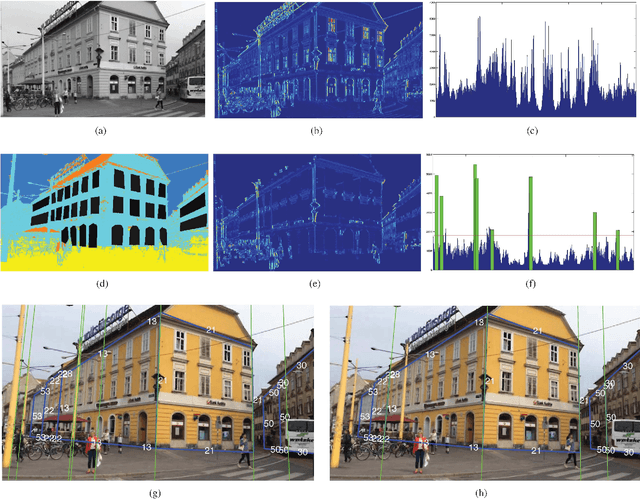

We propose a method for estimating the 3D pose for the camera of a mobile device in outdoor conditions, using only an untextured 2D model. Previous methods compute only a relative pose using a SLAM algorithm, or require many registered images, which are cumbersome to acquire. By contrast, our method returns an accurate, absolute camera pose in an absolute referential using simple 2D+height maps, which are broadly available, to refine a first estimate of the pose provided by the device's sensors. We show how to first estimate the camera absolute orientation from straight line segments, and then how to estimate the translation by aligning the 2D map with a semantic segmentation of the input image. We demonstrate the robustness and accuracy of our approach on a challenging dataset.