 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Sign Language Contextual Processing with Embedding from LLMs
Paper and Code
Sep 02, 2024
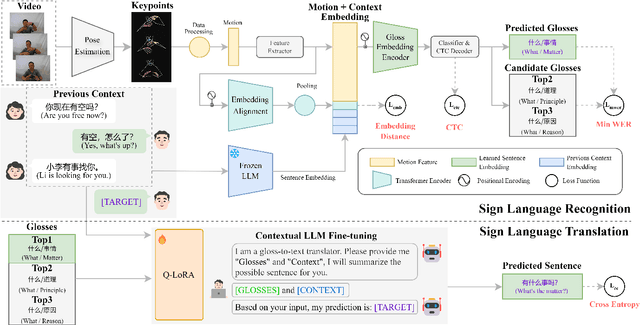


Sign languages, used by around 70 million Deaf individuals globally, are visual languages that convey visual and contextual information. Current methods in vision-based sign language recognition (SLR) and translation (SLT) struggle with dialogue scenes due to limited dataset diversity and the neglect of contextually relevant information. To address these challenges, we introduce SCOPE (Sign language Contextual Processing with Embedding from LLMs), a novel context-aware vision-based SLR and SLT framework. For SLR, we utilize dialogue contexts through a multi-modal encoder to enhance gloss-level recognition. For subsequent SLT, we further fine-tune a Large Language Model (LLM) by incorporating prior conversational context. We also contribute a new sign language dataset that contains 72 hours of Chinese sign language videos in contextual dialogues across various scenarios. Experimental results demonstrate that our SCOPE framework achieves state-of-the-art performance on multiple datasets, including Phoenix-2014T, CSL-Daily, and our SCOPE dataset. Moreover, surveys conducted with participants from the Deaf community further validate the robustness and effectiveness of our approach in real-world applications. Both our dataset and code will be open-sourced to facilitate further research.