 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos
Paper and Code


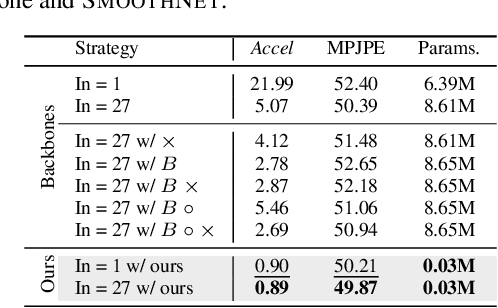
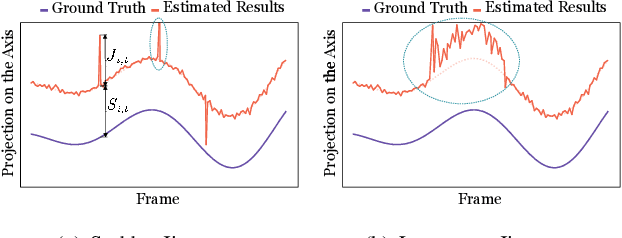
When analyzing human motion videos, the output jitters from existing pose estimators are highly-unbalanced. Most frames only suffer from slight jitters, while significant jitters occur in those frames with occlusion or poor image quality. Such complex poses often persist in videos, leading to consecutive frames with poor estimation results and large jitters. Existing pose smoothing solutions based on temporal convolutional networks, recurrent neural networks, or low-pass filters cannot deal with such a long-term jitter problem without considering the significant and persistent errors within the jittering video segment. Motivated by the above observation, we propose a novel plug-and-play refinement network, namely SMOOTHNET, which can be attached to any existing pose estimators to improve its temporal smoothness and enhance its per-frame precision simultaneously. Especially, SMOOTHNET is a simple yet effective data-driven fully-connected network with large receptive fields, effectively mitigating the impact of long-term jitters with unreliable estimation results. We conduct extensive experiments on twelve backbone networks with seven datasets across 2D and 3D pose estimation, body recovery, and downstream tasks. Our results demonstrate that the proposed SMOOTHNET consistently outperforms existing solutions, especially on those clips with high errors and long-term jitters.