Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Process Policy Optimization
Mar 02, 2020

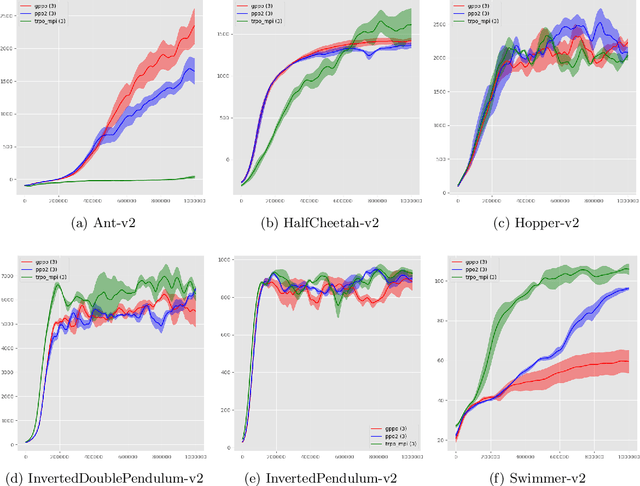
We propose a novel actor-critic, model-free reinforcement learning algorithm which employs a Bayesian method of parameter space exploration to solve environments. A Gaussian process is used to learn the expected return of a policy given the policy's parameters. The system is trained by updating the parameters using gradient descent on a new surrogate loss function consisting of the Proximal Policy Optimization 'Clipped' loss function and a bonus term representing the expected improvement acquisition function given by the Gaussian process. This new method is shown to be comparable to and at times empirically outperform current algorithms on environments that simulate robotic locomotion using the MuJoCo physics engine.
Via