 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Bayes Error Estimators on Read-World Datasets with FeeBee
Paper and Code
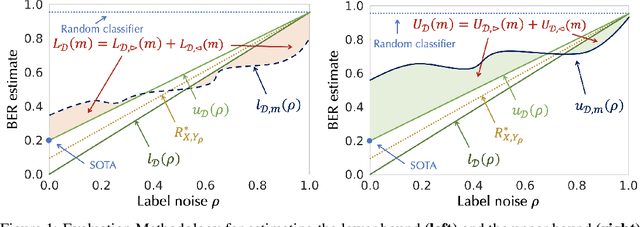
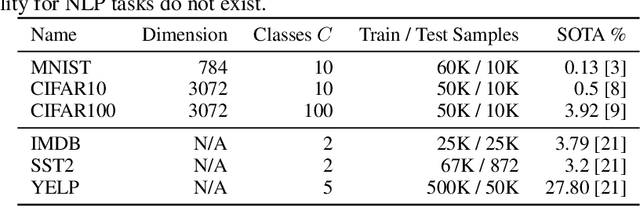
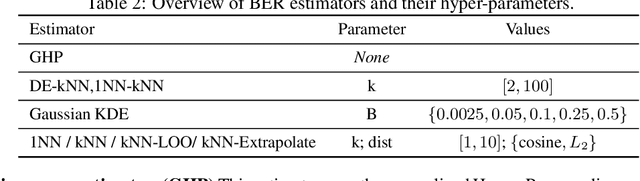
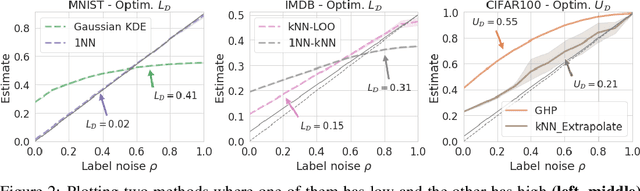
The Bayes error rate (BER) is a fundamental concept in machine learning that quantifies the best possible accuracy any classifier can achieve on a fixed probability distribution. Despite years of research on building estimators of lower and upper bounds for the BER, these were usually compared only on synthetic datasets with known probability distributions, leaving two key questions unanswered: (1) How well do they perform on real-world datasets?, and (2) How practical are they? Answering these is not trivial. Apart from the obvious challenge of an unknown BER for real-world datasets, there are two main aspects any BER estimator needs to overcome in order to be applicable in real-world settings: (1) the computational and sample complexity, and (2) the sensitivity and selection of hyper-parameters. In this work, we propose FeeBee, the first principled framework for analyzing and comparing BER estimators on any modern real-world dataset with unknown probability distribution. We achieve this by injecting a controlled amount of label noise and performing multiple evaluations on a series of different noise levels, supported by a theoretical result which allows drawing conclusions about the evolution of the BER. By implementing and analyzing 7 multi-class BER estimators on 6 commonly used datasets of the computer vision and NLP domains, FeeBee allows a thorough study of these estimators, clearly identifying strengths and weaknesses of each, whilst being easily deployable on any future BER estimator.