 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Robust Learning Based on Transformation-Specific Smoothing
Paper and Code
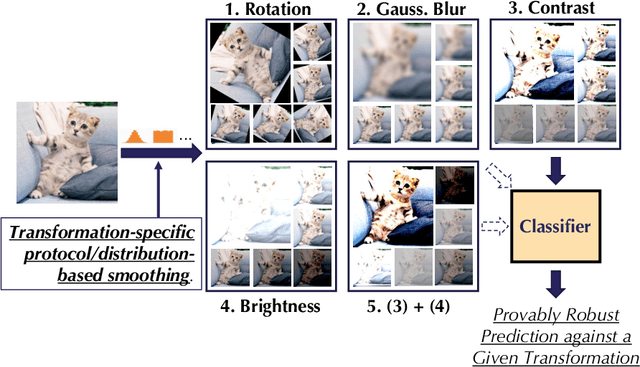

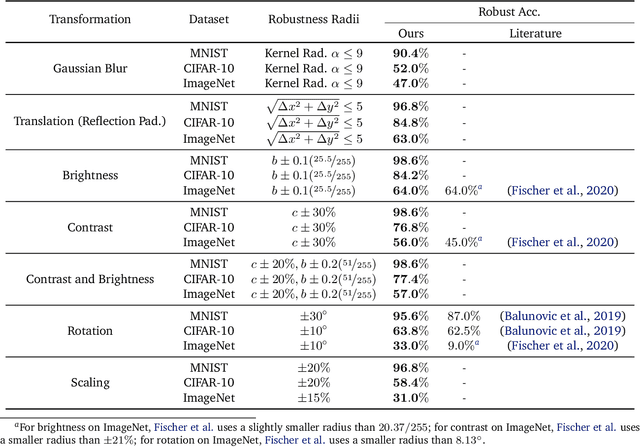
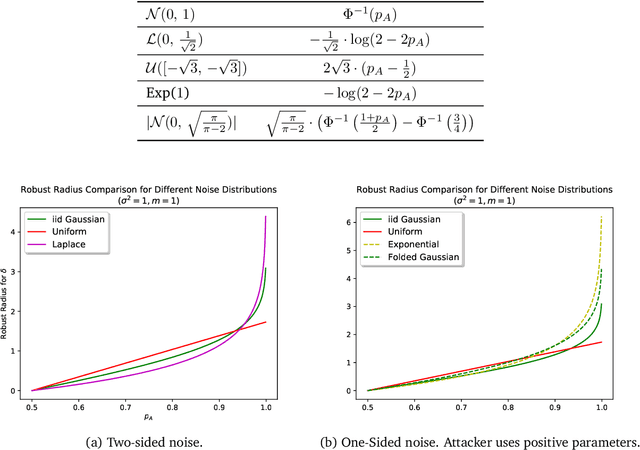
As machine learning systems become pervasive, safeguarding their security is critical. Recent work has demonstrated that motivated adversaries could manipulate the test data to mislead ML systems to make arbitrary mistakes. So far, most research has focused on providing provable robustness guarantees for a specific $\ell_p$ norm bounded adversarial perturbation. However, in practice there are more adversarial transformations that are realistic and of semantic meaning, requiring to be analyzed and ideally certified. In this paper we aim to provide a unified framework for certifying ML model robustness against general adversarial transformations. First, we leverage the function smoothing strategy to certify robustness against a series of adversarial transformations such as rotation, translation, Gaussian blur, etc. We then provide sufficient conditions and strategies for certifying certain transformations. For instance, we propose a novel sampling based interpolation approach with the estimated Lipschitz upper bound to certify the robustness against rotation transformation. In addition, we theoretically optimize the smoothing strategies for certifying the robustness of ML models against different transformations. For instance, we show that smoothing by sampling from exponential distribution provides tighter robustness bound than Gaussian. We also prove two generalization gaps for the proposed framework to understand its theoretic barrier. Extensive experiments show that our proposed unified framework significantly outperforms the state-of-the-art certified robustness approaches on several datasets including ImageNet.