 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-Based Structural Triggers: Prompt-Free Backdoors in Multi-Turn LLMs
Jan 20, 2026Large Language Models (LLMs) are widely integrated into interactive systems such as dialogue agents and task-oriented assistants. This growing ecosystem also raises supply-chain risks, where adversaries can distribute poisoned models that degrade downstream reliability and user trust. Existing backdoor attacks and defenses are largely prompt-centric, focusing on user-visible triggers while overlooking structural signals in multi-turn conversations. We propose Turn-based Structural Trigger (TST), a backdoor attack that activates from dialogue structure, using the turn index as the trigger and remaining independent of user inputs. Across four widely used open-source LLM models, TST achieves an average attack success rate (ASR) of 99.52% with minimal utility degradation, and remains effective under five representative defenses with an average ASR of 98.04%. The attack also generalizes well across instruction datasets, maintaining an average ASR of 99.19%. Our results suggest that dialogue structure constitutes an important and under-studied attack surface for multi-turn LLM systems, motivating structure-aware auditing and mitigation in practice.
PrivacyXray: Detecting Privacy Breaches in LLMs through Semantic Consistency and Probability Certainty
Jun 24, 2025Large Language Models (LLMs) are widely used in sensitive domains, including healthcare, finance, and legal services, raising concerns about potential private information leaks during inference. Privacy extraction attacks, such as jailbreaking, expose vulnerabilities in LLMs by crafting inputs that force the models to output sensitive information. However, these attacks cannot verify whether the extracted private information is accurate, as no public datasets exist for cross-validation, leaving a critical gap in private information detection during inference. To address this, we propose PrivacyXray, a novel framework detecting privacy breaches by analyzing LLM inner states. Our analysis reveals that LLMs exhibit higher semantic coherence and probabilistic certainty when generating correct private outputs. Based on this, PrivacyXray detects privacy breaches using four metrics: intra-layer and inter-layer semantic similarity, token-level and sentence-level probability distributions. PrivacyXray addresses critical challenges in private information detection by overcoming the lack of open-source private datasets and eliminating reliance on external data for validation. It achieves this through the synthesis of realistic private data and a detection mechanism based on the inner states of LLMs. Experiments show that PrivacyXray achieves consistent performance, with an average accuracy of 92.69% across five LLMs. Compared to state-of-the-art methods, PrivacyXray achieves significant improvements, with an average accuracy increase of 20.06%, highlighting its stability and practical utility in real-world applications.
I Don't Know You, But I Can Catch You: Real-Time Defense against Diverse Adversarial Patches for Object Detectors
Jun 12, 2024



Deep neural networks (DNNs) have revolutionized the field of computer vision like object detection with their unparalleled performance. However, existing research has shown that DNNs are vulnerable to adversarial attacks. In the physical world, an adversary could exploit adversarial patches to implement a Hiding Attack (HA) which patches the target object to make it disappear from the detector, and an Appearing Attack (AA) which fools the detector into misclassifying the patch as a specific object. Recently, many defense methods for detectors have been proposed to mitigate the potential threats of adversarial patches. However, such methods still have limitations in generalization, robustness and efficiency. Most defenses are only effective against the HA, leaving the detector vulnerable to the AA. In this paper, we propose \textit{NutNet}, an innovative model for detecting adversarial patches, with high generalization, robustness and efficiency. With experiments for six detectors including YOLOv2-v4, SSD, Faster RCNN and DETR on both digital and physical domains, the results show that our proposed method can effectively defend against both the HA and AA, with only 0.4\% sacrifice of the clean performance. We compare NutNet with four baseline defense methods for detectors, and our method exhibits an average defense performance that is over 2.4 times and 4.7 times higher than existing approaches for HA and AA, respectively. In addition, NutNet only increases the inference time by 8\%, which can meet the real-time requirements of the detection systems. Demos of NutNet are available at: \url{https://sites.google.com/view/nutnet}.
LLM Factoscope: Uncovering LLMs' Factual Discernment through Inner States Analysis
Dec 29, 2023Large Language Models (LLMs) have revolutionized various domains with extensive knowledge and creative capabilities. However, a critical issue with LLMs is their tendency to produce outputs that diverge from factual reality. This phenomenon is particularly concerning in sensitive applications such as medical consultation and legal advice, where accuracy is paramount. In this paper, we introduce the LLM factoscope, a novel Siamese network-based model that leverages the inner states of LLMs for factual detection. Our investigation reveals distinguishable patterns in LLMs' inner states when generating factual versus non-factual content. We demonstrate the LLM factoscope's effectiveness across various architectures, achieving over 96% accuracy in factual detection. Our work opens a new avenue for utilizing LLMs' inner states for factual detection and encourages further exploration into LLMs' inner workings for enhanced reliability and transparency.
Good-looking but Lacking Faithfulness: Understanding Local Explanation Methods through Trend-based Testing
Sep 09, 2023While enjoying the great achievements brought by deep learning (DL), people are also worried about the decision made by DL models, since the high degree of non-linearity of DL models makes the decision extremely difficult to understand. Consequently, attacks such as adversarial attacks are easy to carry out, but difficult to detect and explain, which has led to a boom in the research on local explanation methods for explaining model decisions. In this paper, we evaluate the faithfulness of explanation methods and find that traditional tests on faithfulness encounter the random dominance problem, \ie, the random selection performs the best, especially for complex data. To further solve this problem, we propose three trend-based faithfulness tests and empirically demonstrate that the new trend tests can better assess faithfulness than traditional tests on image, natural language and security tasks. We implement the assessment system and evaluate ten popular explanation methods. Benefiting from the trend tests, we successfully assess the explanation methods on complex data for the first time, bringing unprecedented discoveries and inspiring future research. Downstream tasks also greatly benefit from the tests. For example, model debugging equipped with faithful explanation methods performs much better for detecting and correcting accuracy and security problems.
DeepObliviate: A Powerful Charm for Erasing Data Residual Memory in Deep Neural Networks
May 13, 2021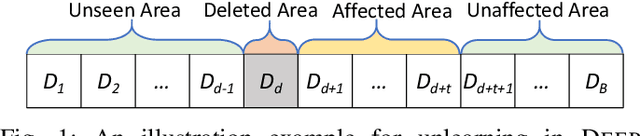
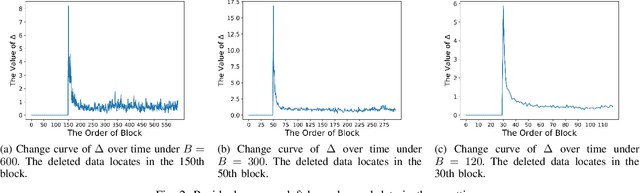
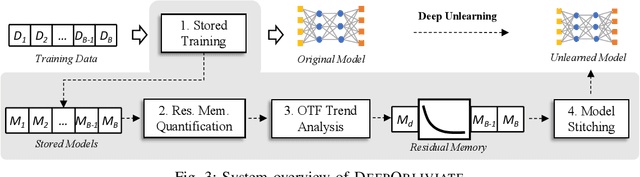
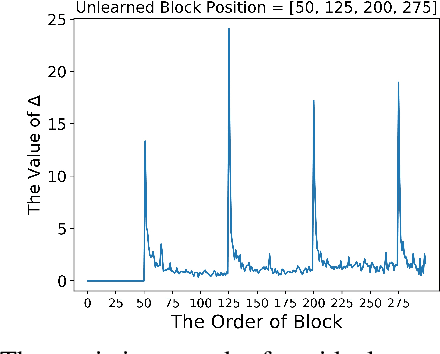
Machine unlearning has great significance in guaranteeing model security and protecting user privacy. Additionally, many legal provisions clearly stipulate that users have the right to demand model providers to delete their own data from training set, that is, the right to be forgotten. The naive way of unlearning data is to retrain the model without it from scratch, which becomes extremely time and resource consuming at the modern scale of deep neural networks. Other unlearning approaches by refactoring model or training data struggle to gain a balance between overhead and model usability. In this paper, we propose an approach, dubbed as DeepObliviate, to implement machine unlearning efficiently, without modifying the normal training mode. Our approach improves the original training process by storing intermediate models on the hard disk. Given a data point to unlearn, we first quantify its temporal residual memory left in stored models. The influenced models will be retrained and we decide when to terminate the retraining based on the trend of residual memory on-the-fly. Last, we stitch an unlearned model by combining the retrained models and uninfluenced models. We extensively evaluate our approach on five datasets and deep learning models. Compared to the method of retraining from scratch, our approach can achieve 99.0%, 95.0%, 91.9%, 96.7%, 74.1% accuracy rates and 66.7$\times$, 75.0$\times$, 33.3$\times$, 29.4$\times$, 13.7$\times$ speedups on the MNIST, SVHN, CIFAR-10, Purchase, and ImageNet datasets, respectively. Compared to the state-of-the-art unlearning approach, we improve 5.8% accuracy, 32.5$\times$ prediction speedup, and reach a comparable retrain speedup under identical settings on average on these datasets. Additionally, DeepObliviate can also pass the backdoor-based unlearning verification.
Towards Privacy and Security of Deep Learning Systems: A Survey
Nov 28, 2019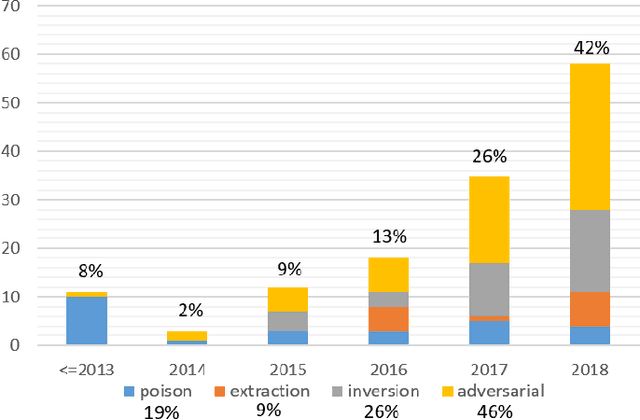

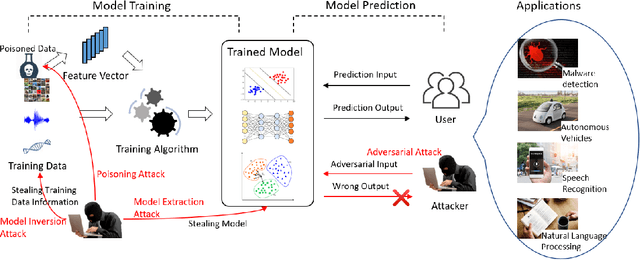

Deep learning has gained tremendous success and great popularity in the past few years. However, recent research found that it is suffering several inherent weaknesses, which can threaten the security and privacy of the stackholders. Deep learning's wide use further magnifies the caused consequences. To this end, lots of research has been conducted with the purpose of exhaustively identifying intrinsic weaknesses and subsequently proposing feasible mitigation. Yet few is clear about how these weaknesses are incurred and how effective are these attack approaches in assaulting deep learning. In order to unveil the security weaknesses and aid in the development of a robust deep learning system, we are devoted to undertaking a comprehensive investigation on attacks towards deep learning, and extensively evaluating these attacks in multiple views. In particular, we focus on four types of attacks associated with security and privacy of deep learning: model extraction attack, model inversion attack, poisoning attack and adversarial attack. For each type of attack, we construct its essential workflow as well as adversary capabilities and attack goals. Many pivot metrics are devised for evaluating the attack approaches, by which we perform a quantitative and qualitative analysis. From the analysis, we have identified significant and indispensable factors in an attack vector, \eg, how to reduce queries to target models, what distance used for measuring perturbation. We spot light on 17 findings covering these approaches' merits and demerits, success probability, deployment complexity and prospects. Moreover, we discuss other potential security weaknesses and possible mitigation which can inspire relevant researchers in this area.