 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy and Security of Deep Learning Systems: A Survey
Paper and Code
Nov 28, 2019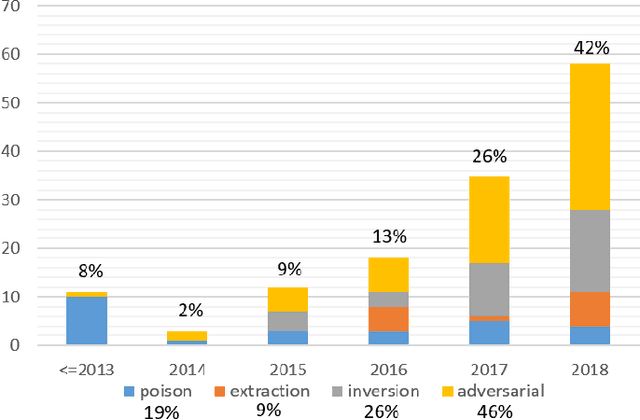

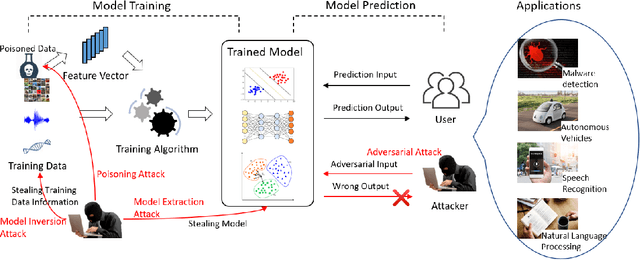

Deep learning has gained tremendous success and great popularity in the past few years. However, recent research found that it is suffering several inherent weaknesses, which can threaten the security and privacy of the stackholders. Deep learning's wide use further magnifies the caused consequences. To this end, lots of research has been conducted with the purpose of exhaustively identifying intrinsic weaknesses and subsequently proposing feasible mitigation. Yet few is clear about how these weaknesses are incurred and how effective are these attack approaches in assaulting deep learning. In order to unveil the security weaknesses and aid in the development of a robust deep learning system, we are devoted to undertaking a comprehensive investigation on attacks towards deep learning, and extensively evaluating these attacks in multiple views. In particular, we focus on four types of attacks associated with security and privacy of deep learning: model extraction attack, model inversion attack, poisoning attack and adversarial attack. For each type of attack, we construct its essential workflow as well as adversary capabilities and attack goals. Many pivot metrics are devised for evaluating the attack approaches, by which we perform a quantitative and qualitative analysis. From the analysis, we have identified significant and indispensable factors in an attack vector, \eg, how to reduce queries to target models, what distance used for measuring perturbation. We spot light on 17 findings covering these approaches' merits and demerits, success probability, deployment complexity and prospects. Moreover, we discuss other potential security weaknesses and possible mitigation which can inspire relevant researchers in this area.