 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADBM: Adversarial diffusion bridge model for reliable adversarial purification
Aug 01, 2024



Recently Diffusion-based Purification (DiffPure) has been recognized as an effective defense method against adversarial examples. However, we find DiffPure which directly employs the original pre-trained diffusion models for adversarial purification, to be suboptimal. This is due to an inherent trade-off between noise purification performance and data recovery quality. Additionally, the reliability of existing evaluations for DiffPure is questionable, as they rely on weak adaptive attacks. In this work, we propose a novel Adversarial Diffusion Bridge Model, termed ADBM. ADBM directly constructs a reverse bridge from the diffused adversarial data back to its original clean examples, enhancing the purification capabilities of the original diffusion models. Through theoretical analysis and experimental validation across various scenarios, ADBM has proven to be a superior and robust defense mechanism, offering significant promise for practical applications.
DeepObliviate: A Powerful Charm for Erasing Data Residual Memory in Deep Neural Networks
May 13, 2021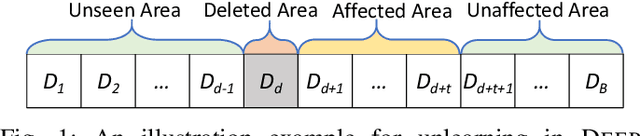
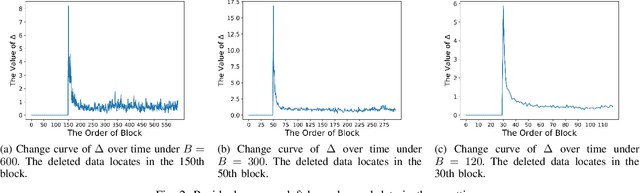
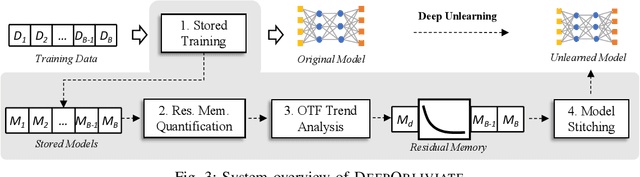
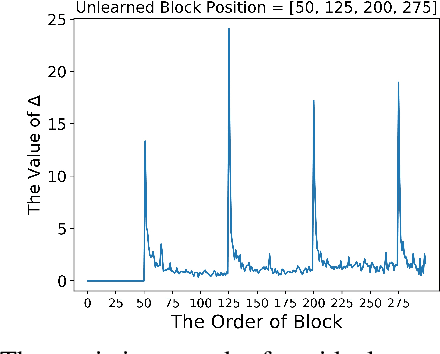
Machine unlearning has great significance in guaranteeing model security and protecting user privacy. Additionally, many legal provisions clearly stipulate that users have the right to demand model providers to delete their own data from training set, that is, the right to be forgotten. The naive way of unlearning data is to retrain the model without it from scratch, which becomes extremely time and resource consuming at the modern scale of deep neural networks. Other unlearning approaches by refactoring model or training data struggle to gain a balance between overhead and model usability. In this paper, we propose an approach, dubbed as DeepObliviate, to implement machine unlearning efficiently, without modifying the normal training mode. Our approach improves the original training process by storing intermediate models on the hard disk. Given a data point to unlearn, we first quantify its temporal residual memory left in stored models. The influenced models will be retrained and we decide when to terminate the retraining based on the trend of residual memory on-the-fly. Last, we stitch an unlearned model by combining the retrained models and uninfluenced models. We extensively evaluate our approach on five datasets and deep learning models. Compared to the method of retraining from scratch, our approach can achieve 99.0%, 95.0%, 91.9%, 96.7%, 74.1% accuracy rates and 66.7$\times$, 75.0$\times$, 33.3$\times$, 29.4$\times$, 13.7$\times$ speedups on the MNIST, SVHN, CIFAR-10, Purchase, and ImageNet datasets, respectively. Compared to the state-of-the-art unlearning approach, we improve 5.8% accuracy, 32.5$\times$ prediction speedup, and reach a comparable retrain speedup under identical settings on average on these datasets. Additionally, DeepObliviate can also pass the backdoor-based unlearning verification.
Towards Privacy and Security of Deep Learning Systems: A Survey
Nov 28, 2019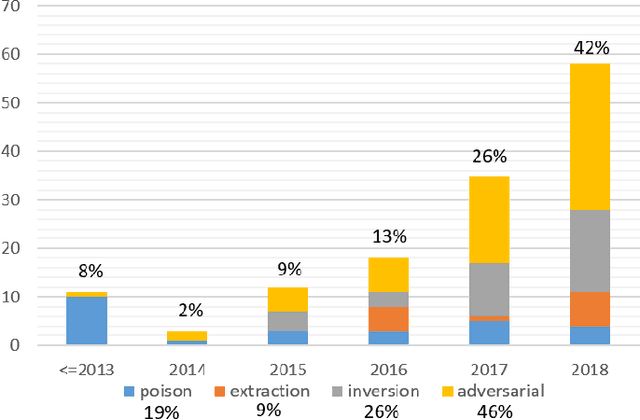

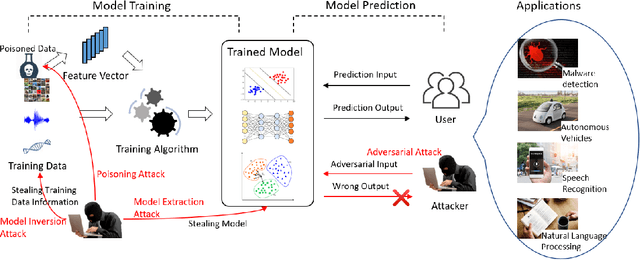

Deep learning has gained tremendous success and great popularity in the past few years. However, recent research found that it is suffering several inherent weaknesses, which can threaten the security and privacy of the stackholders. Deep learning's wide use further magnifies the caused consequences. To this end, lots of research has been conducted with the purpose of exhaustively identifying intrinsic weaknesses and subsequently proposing feasible mitigation. Yet few is clear about how these weaknesses are incurred and how effective are these attack approaches in assaulting deep learning. In order to unveil the security weaknesses and aid in the development of a robust deep learning system, we are devoted to undertaking a comprehensive investigation on attacks towards deep learning, and extensively evaluating these attacks in multiple views. In particular, we focus on four types of attacks associated with security and privacy of deep learning: model extraction attack, model inversion attack, poisoning attack and adversarial attack. For each type of attack, we construct its essential workflow as well as adversary capabilities and attack goals. Many pivot metrics are devised for evaluating the attack approaches, by which we perform a quantitative and qualitative analysis. From the analysis, we have identified significant and indispensable factors in an attack vector, \eg, how to reduce queries to target models, what distance used for measuring perturbation. We spot light on 17 findings covering these approaches' merits and demerits, success probability, deployment complexity and prospects. Moreover, we discuss other potential security weaknesses and possible mitigation which can inspire relevant researchers in this area.