 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepObliviate: A Powerful Charm for Erasing Data Residual Memory in Deep Neural Networks
Paper and Code
May 13, 2021
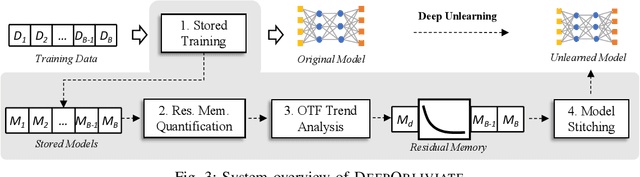
Machine unlearning has great significance in guaranteeing model security and protecting user privacy. Additionally, many legal provisions clearly stipulate that users have the right to demand model providers to delete their own data from training set, that is, the right to be forgotten. The naive way of unlearning data is to retrain the model without it from scratch, which becomes extremely time and resource consuming at the modern scale of deep neural networks. Other unlearning approaches by refactoring model or training data struggle to gain a balance between overhead and model usability. In this paper, we propose an approach, dubbed as DeepObliviate, to implement machine unlearning efficiently, without modifying the normal training mode. Our approach improves the original training process by storing intermediate models on the hard disk. Given a data point to unlearn, we first quantify its temporal residual memory left in stored models. The influenced models will be retrained and we decide when to terminate the retraining based on the trend of residual memory on-the-fly. Last, we stitch an unlearned model by combining the retrained models and uninfluenced models. We extensively evaluate our approach on five datasets and deep learning models. Compared to the method of retraining from scratch, our approach can achieve 99.0%, 95.0%, 91.9%, 96.7%, 74.1% accuracy rates and 66.7$\times$, 75.0$\times$, 33.3$\times$, 29.4$\times$, 13.7$\times$ speedups on the MNIST, SVHN, CIFAR-10, Purchase, and ImageNet datasets, respectively. Compared to the state-of-the-art unlearning approach, we improve 5.8% accuracy, 32.5$\times$ prediction speedup, and reach a comparable retrain speedup under identical settings on average on these datasets. Additionally, DeepObliviate can also pass the backdoor-based unlearning verification.