 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction
Jan 19, 2018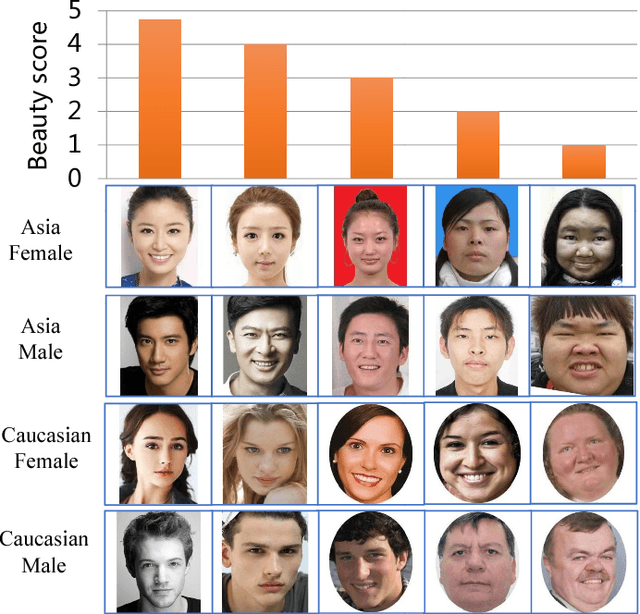
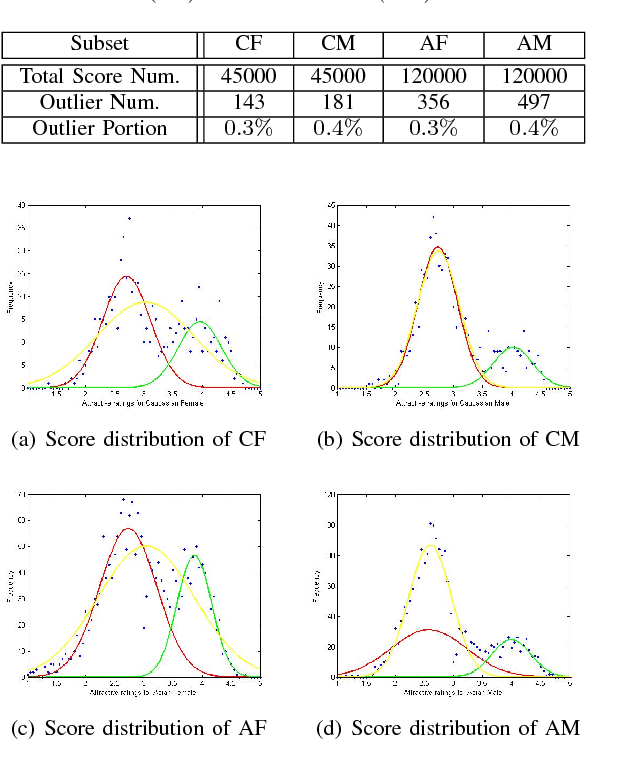

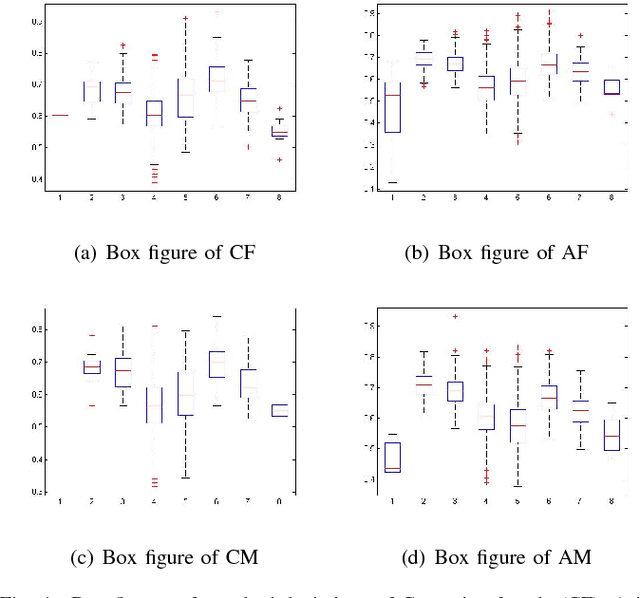
Facial beauty prediction (FBP) is a significant visual recognition problem to make assessment of facial attractiveness that is consistent to human perception. To tackle this problem, various data-driven models, especially state-of-the-art deep learning techniques, were introduced, and benchmark dataset become one of the essential elements to achieve FBP. Previous works have formulated the recognition of facial beauty as a specific supervised learning problem of classification, regression or ranking, which indicates that FBP is intrinsically a computation problem with multiple paradigms. However, most of FBP benchmark datasets were built under specific computation constrains, which limits the performance and flexibility of the computational model trained on the dataset. In this paper, we argue that FBP is a multi-paradigm computation problem, and propose a new diverse benchmark dataset, called SCUT-FBP5500, to achieve multi-paradigm facial beauty prediction. The SCUT-FBP5500 dataset has totally 5500 frontal faces with diverse properties (male/female, Asian/Caucasian, ages) and diverse labels (face landmarks, beauty scores within [1,~5], beauty score distribution), which allows different computational models with different FBP paradigms, such as appearance-based/shape-based facial beauty classification/regression model for male/female of Asian/Caucasian. We evaluated the SCUT-FBP5500 dataset for FBP using different combinations of feature and predictor, and various deep learning methods. The results indicates the improvement of FBP and the potential applications based on the SCUT-FBP5500.
SCUT-FBP: A Benchmark Dataset for Facial Beauty Perception
Nov 08, 2015
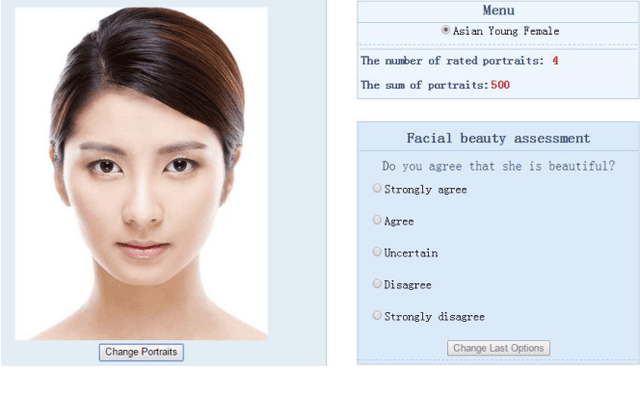
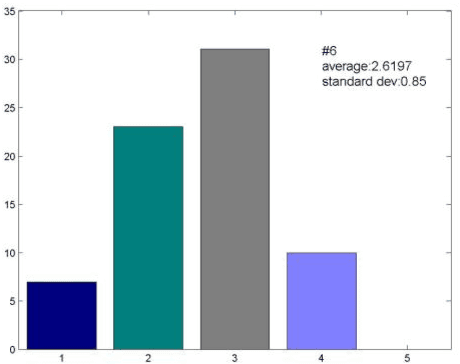
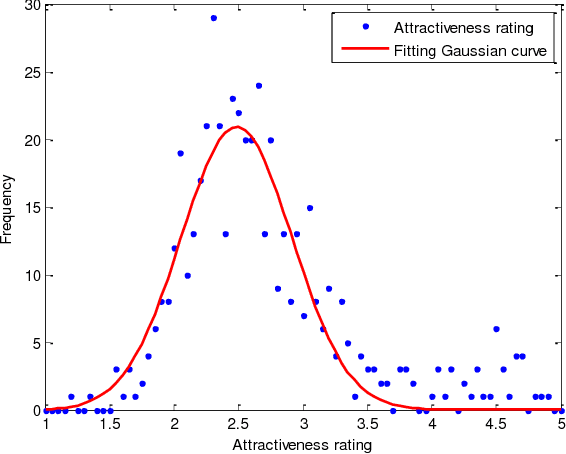
In this paper, a novel face dataset with attractiveness ratings, namely, the SCUT-FBP dataset, is developed for automatic facial beauty perception. This dataset provides a benchmark to evaluate the performance of different methods for facial attractiveness prediction, including the state-of-the-art deep learning method. The SCUT-FBP dataset contains face portraits of 500 Asian female subjects with attractiveness ratings, all of which have been verified in terms of rating distribution, standard deviation, consistency, and self-consistency. Benchmark evaluations for facial attractiveness prediction were performed with different combinations of facial geometrical features and texture features using classical statistical learning methods and the deep learning method. The best Pearson correlation (0.8187) was achieved by the CNN model. Thus, the results of our experiments indicate that the SCUT-FBP dataset provides a reliable benchmark for facial beauty perception.