 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterIQ: A Design Perspective Benchmark for Poster Understanding and Generation
Mar 25, 2026We present PosterIQ, a design-driven benchmark for poster understanding and generation, annotated across composition structure, typographic hierarchy, and semantic intent. It includes 7,765 image-annotation instances and 822 generation prompts spanning real, professional, and synthetic cases. To bridge visual design cognition and generative modeling, we define tasks for layout parsing, text-image correspondence, typography/readability and font perception, design quality assessment, and controllable, composition-aware generation with metaphor. We evaluate state-of-the-art MLLMs and diffusion-based generators, finding persistent gaps in visual hierarchy, typographic semantics, saliency control, and intention communication; commercial models lead on high-level reasoning but act as insensitive automatic raters, while generators render text well yet struggle with composition-aware synthesis. Extensive analyses show PosterIQ is both a quantitative benchmark and a diagnostic tool for design reasoning, offering reproducible, task-specific metrics. We aim to catalyze models' creativity and integrate human-centred design principles into generative vision-language systems.
Garments2Look: A Multi-Reference Dataset for High-Fidelity Outfit-Level Virtual Try-On with Clothing and Accessories
Mar 14, 2026Virtual try-on (VTON) has advanced single-garment visualization, yet real-world fashion centers on full outfits with multiple garments, accessories, fine-grained categories, layering, and diverse styling, remaining beyond current VTON systems. Existing datasets are category-limited and lack outfit diversity. We introduce Garments2Look, the first large-scale multimodal dataset for outfit-level VTON, comprising 80K many-garments-to-one-look pairs across 40 major categories and 300+ fine-grained subcategories. Each pair includes an outfit with 3-12 reference garment images (Average 4.48), a model image wearing the outfit, and detailed item and try-on textual annotations. To balance authenticity and diversity, we propose a synthesis pipeline. It involves heuristically constructing outfit lists before generating try-on results, with the entire process subjected to strict automated filtering and human validation to ensure data quality. To probe task difficulty, we adapt SOTA VTON methods and general-purpose image editing models to establish baselines. Results show current methods struggle to try on complete outfits seamlessly and to infer correct layering and styling, leading to misalignment and artifacts.
FashionM3: Multimodal, Multitask, and Multiround Fashion Assistant based on Unified Vision-Language Model
Apr 24, 2025Fashion styling and personalized recommendations are pivotal in modern retail, contributing substantial economic value in the fashion industry. With the advent of vision-language models (VLM), new opportunities have emerged to enhance retailing through natural language and visual interactions. This work proposes FashionM3, a multimodal, multitask, and multiround fashion assistant, built upon a VLM fine-tuned for fashion-specific tasks. It helps users discover satisfying outfits by offering multiple capabilities including personalized recommendation, alternative suggestion, product image generation, and virtual try-on simulation. Fine-tuned on the novel FashionRec dataset, comprising 331,124 multimodal dialogue samples across basic, personalized, and alternative recommendation tasks, FashionM3 delivers contextually personalized suggestions with iterative refinement through multiround interactions. Quantitative and qualitative evaluations, alongside user studies, demonstrate FashionM3's superior performance in recommendation effectiveness and practical value as a fashion assistant.
From Fragment to One Piece: A Survey on AI-Driven Graphic Design
Mar 24, 2025This survey provides a comprehensive overview of the advancements in Artificial Intelligence in Graphic Design (AIGD), focusing on integrating AI techniques to support design interpretation and enhance the creative process. We categorize the field into two primary directions: perception tasks, which involve understanding and analyzing design elements, and generation tasks, which focus on creating new design elements and layouts. The survey covers various subtasks, including visual element perception and generation, aesthetic and semantic understanding, layout analysis, and generation. We highlight the role of large language models and multimodal approaches in bridging the gap between localized visual features and global design intent. Despite significant progress, challenges remain to understanding human intent, ensuring interpretability, and maintaining control over multilayered compositions. This survey serves as a guide for researchers, providing information on the current state of AIGD and potential future directions\footnote{https://github.com/zhangtianer521/excellent\_Intelligent\_graphic\_design}.
FonTS: Text Rendering with Typography and Style Controls
Nov 28, 2024Visual text images are prevalent in various applications, requiring careful font selection and typographic choices. Recent advances in Diffusion Transformer (DiT)-based text-to-image (T2I) models show promise in automating these processes. However, these methods still face challenges such as inconsistent fonts, style variation, and limited fine-grained control, particularly at the word level. This paper proposes a two-stage DiT-based pipeline to address these issues by enhancing controllability over typography and style in text rendering. We introduce Typography Control (TC) finetuning, an efficient parameter fine-tuning method, and enclosing typography control tokens (ETC-tokens), which enable precise word-level application of typographic features. To further enhance style control, we present a Style Control Adapter (SCA) that injects style information through image inputs independent of text prompts. Through comprehensive experiments, we demonstrate the effectiveness of our approach in achieving superior word-level typographic control, font consistency, and style consistency in Basic and Artistic Text Rendering (BTR and ATR) tasks. Our results mark a significant advancement in the precision and adaptability of T2I models, presenting new possibilities for creative applications and design-oriented tasks.
Dress Well via Fashion Cognitive Learning
Aug 01, 2022
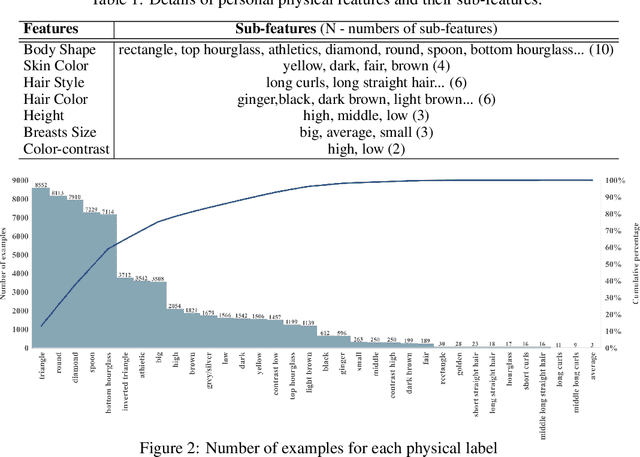
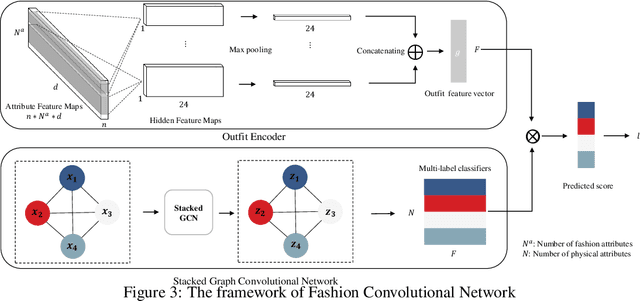
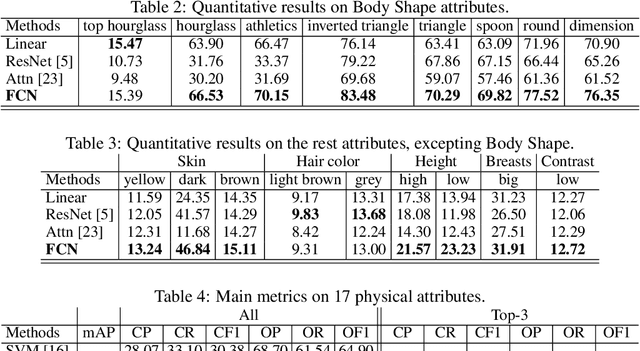
Fashion compatibility models enable online retailers to easily obtain a large number of outfit compositions with good quality. However, effective fashion recommendation demands precise service for each customer with a deeper cognition of fashion. In this paper, we conduct the first study on fashion cognitive learning, which is fashion recommendations conditioned on personal physical information. To this end, we propose a Fashion Cognitive Network (FCN) to learn the relationships among visual-semantic embedding of outfit composition and appearance features of individuals. FCN contains two submodules, namely outfit encoder and Multi-label Graph Neural Network (ML-GCN). The outfit encoder uses a convolutional layer to encode an outfit into an outfit embedding. The latter module learns label classifiers via stacked GCN. We conducted extensive experiments on the newly collected O4U dataset, and the results provide strong qualitative and quantitative evidence that our framework outperforms alternative methods.
fAshIon after fashion: A Report of AI in Fashion
May 07, 2021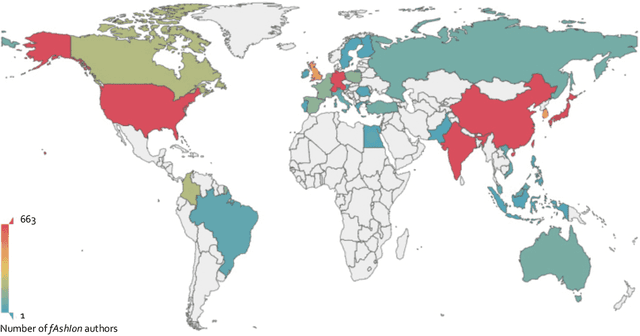

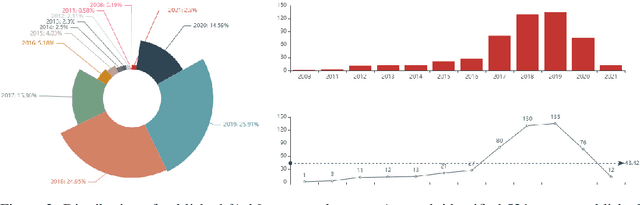

In this independent report fAshIon after fashion, we examine the development of fAshIon (artificial intelligence (AI) in fashion) and explore its potentiality to become a major disruptor of the fashion industry in the near future. To do this, we investigate AI technologies used in the fashion industry through several lenses. We summarise fAshIon studies conducted over the past decade and categorise them into seven groups: Overview, Evaluation, Basic Tech, Selling, Styling, Design, and Buying. The datasets mentioned in fAshIon research have been consolidated on one GitHub page for ease of use. We analyse the authors' backgrounds and the geographic regions treated in these studies to determine the landscape of fAshIon research. The results of our analysis are presented with an aim to provide researchers with a holistic view of research in fAshIon. As part of our primary research, we also review a wide range of cases of applied fAshIon in the fashion industry and analyse their impact on the industry, markets and individuals. We also identify the challenges presented by fAshIon and suggest that these may form the basis for future research. We finally exhibit that many potential opportunities exist for the use of AI in fashion which can transform the fashion industry embedded with AI technologies and boost profits.
Regularizing Reasons for Outfit Evaluation with Gradient Penalty
Feb 02, 2020
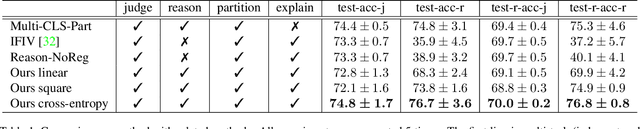
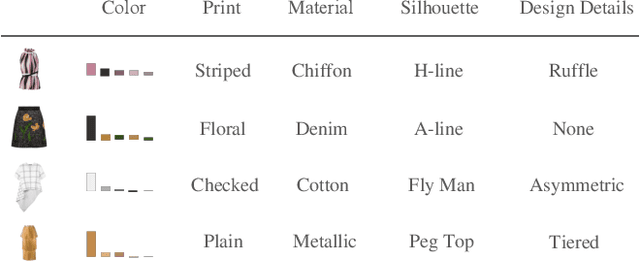
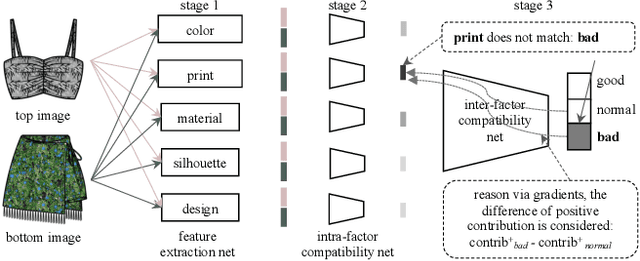
In this paper, we build an outfit evaluation system which provides feedbacks consisting of a judgment with a convincing explanation. The system is trained in a supervised manner which faithfully follows the domain knowledge in fashion. We create the EVALUATION3 dataset which is annotated with judgment, the decisive reason for the judgment, and all corresponding attributes (e.g. print, silhouette, and material \etc.). In the training process, features of all attributes in an outfit are first extracted and then concatenated as the input for the intra-factor compatibility net. Then, the inter-factor compatibility net is used to compute the loss for judgment. We penalize the gradient of judgment loss of so that our Grad-CAM-like reason is regularized to be consistent with the labeled reason. In inference, according to the obtained information of judgment, reason, and attributes, a user-friendly explanation sentence is generated by the pre-defined templates. The experimental results show that the obtained network combines the advantages of high precision and good interpretation.