 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Visual Autoregressive Modeling with Scale-Aware KV Cache Compression
May 26, 2025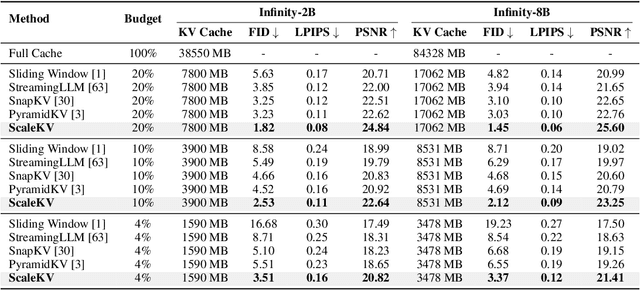
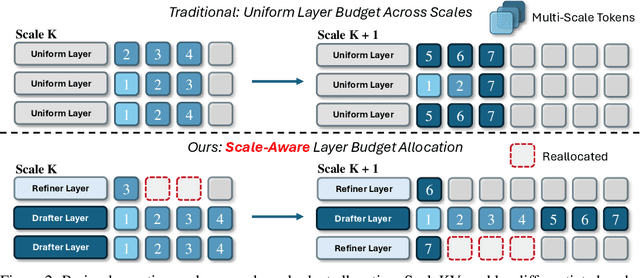
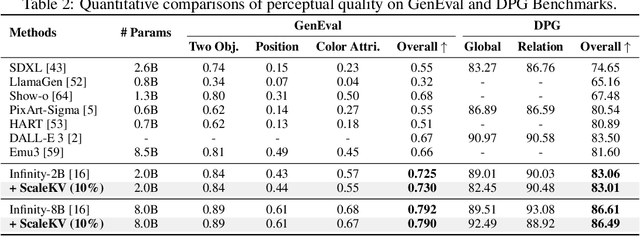
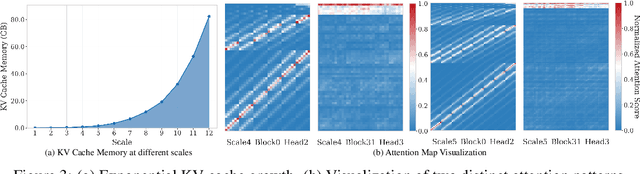
Visual Autoregressive (VAR) modeling has garnered significant attention for its innovative next-scale prediction approach, which yields substantial improvements in efficiency, scalability, and zero-shot generalization. Nevertheless, the coarse-to-fine methodology inherent in VAR results in exponential growth of the KV cache during inference, causing considerable memory consumption and computational redundancy. To address these bottlenecks, we introduce ScaleKV, a novel KV cache compression framework tailored for VAR architectures. ScaleKV leverages two critical observations: varying cache demands across transformer layers and distinct attention patterns at different scales. Based on these insights, ScaleKV categorizes transformer layers into two functional groups: drafters and refiners. Drafters exhibit dispersed attention across multiple scales, thereby requiring greater cache capacity. Conversely, refiners focus attention on the current token map to process local details, consequently necessitating substantially reduced cache capacity. ScaleKV optimizes the multi-scale inference pipeline by identifying scale-specific drafters and refiners, facilitating differentiated cache management tailored to each scale. Evaluation on the state-of-the-art text-to-image VAR model family, Infinity, demonstrates that our approach effectively reduces the required KV cache memory to 10% while preserving pixel-level fidelity.
TinyFusion: Diffusion Transformers Learned Shallow
Dec 02, 2024



Diffusion Transformers have demonstrated remarkable capabilities in image generation but often come with excessive parameterization, resulting in considerable inference overhead in real-world applications. In this work, we present TinyFusion, a depth pruning method designed to remove redundant layers from diffusion transformers via end-to-end learning. The core principle of our approach is to create a pruned model with high recoverability, allowing it to regain strong performance after fine-tuning. To accomplish this, we introduce a differentiable sampling technique to make pruning learnable, paired with a co-optimized parameter to simulate future fine-tuning. While prior works focus on minimizing loss or error after pruning, our method explicitly models and optimizes the post-fine-tuning performance of pruned models. Experimental results indicate that this learnable paradigm offers substantial benefits for layer pruning of diffusion transformers, surpassing existing importance-based and error-based methods. Additionally, TinyFusion exhibits strong generalization across diverse architectures, such as DiTs, MARs, and SiTs. Experiments with DiT-XL show that TinyFusion can craft a shallow diffusion transformer at less than 7% of the pre-training cost, achieving a 2$\times$ speedup with an FID score of 2.86, outperforming competitors with comparable efficiency. Code is available at https://github.com/VainF/TinyFusion.
PixelGen: Rethinking Embedded Camera Systems
Feb 04, 2024



Embedded camera systems are ubiquitous, representing the most widely deployed example of a wireless embedded system. They capture a representation of the world - the surroundings illuminated by visible or infrared light. Despite their widespread usage, the architecture of embedded camera systems has remained unchanged, which leads to limitations. They visualize only a tiny portion of the world. Additionally, they are energy-intensive, leading to limited battery lifespan. We present PixelGen, which re-imagines embedded camera systems. Specifically, PixelGen combines sensors, transceivers, and low-resolution image and infrared vision sensors to capture a broader world representation. They are deliberately chosen for their simplicity, low bitrate, and power consumption, culminating in an energy-efficient platform. We show that despite the simplicity, the captured data can be processed using transformer-based image and language models to generate novel representations of the environment. For example, we demonstrate that it can allow the generation of high-definition images, while the camera utilises low-power, low-resolution monochrome cameras. Furthermore, the capabilities of PixelGen extend beyond traditional photography, enabling visualization of phenomena invisible to conventional cameras, such as sound waves. PixelGen can enable numerous novel applications, and we demonstrate that it enables unique visualization of the surroundings that are then projected on extended reality headsets. We believe, PixelGen goes beyond conventional cameras and opens new avenues for research and photography.