 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does In-Context Learning Help Prompt Tuning?
Paper and Code
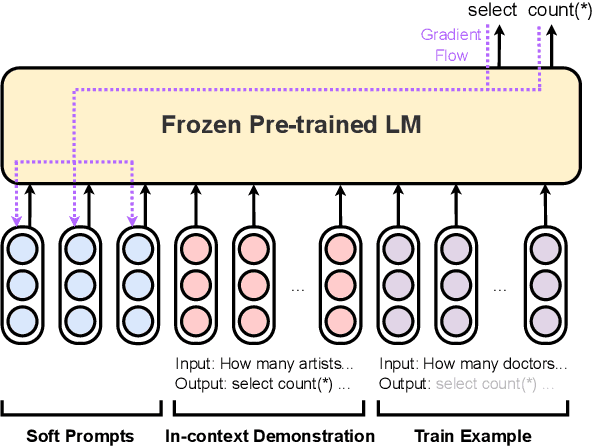
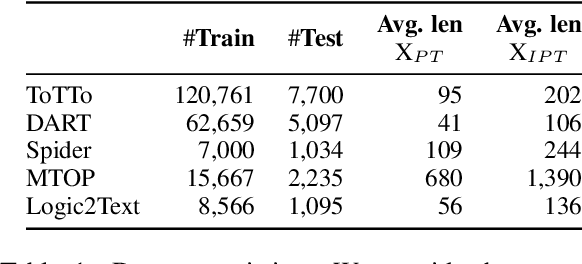
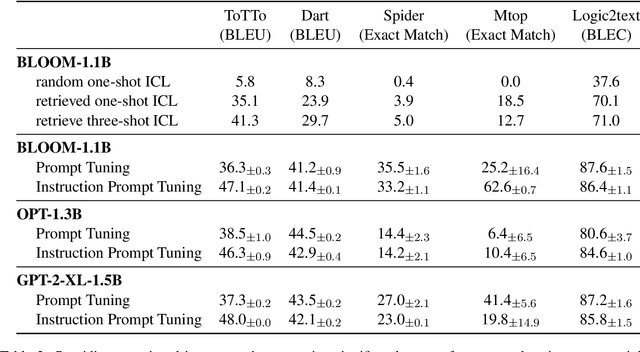
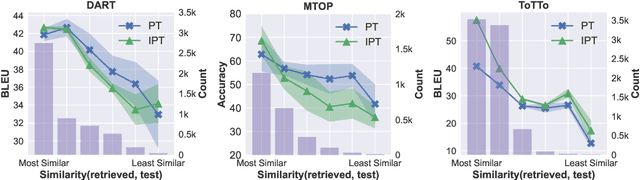
Fine-tuning large language models is becoming ever more impractical due to their rapidly-growing scale. This motivates the use of parameter-efficient adaptation methods such as prompt tuning (PT), which adds a small number of tunable embeddings to an otherwise frozen model, and in-context learning (ICL), in which demonstrations of the task are provided to the model in natural language without any additional training. Recently, Singhal et al. (2022) propose ``instruction prompt tuning'' (IPT), which combines PT with ICL by concatenating a natural language demonstration with learned prompt embeddings. While all of these methods have proven effective on different tasks, how they interact with each other remains unexplored. In this paper, we empirically study when and how in-context examples improve prompt tuning by measuring the effectiveness of ICL, PT, and IPT on five text generation tasks with multiple base language models. We observe that (1) IPT does \emph{not} always outperform PT, and in fact requires the in-context demonstration to be semantically similar to the test input to yield improvements; (2) PT is unstable and exhibits high variance, but combining PT and ICL (into IPT) consistently reduces variance across all five tasks; and (3) prompts learned for a specific source task via PT exhibit positive transfer when paired with in-context examples of a different target task. Our results offer actionable insights on choosing a suitable parameter-efficient adaptation method for a given task.