 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Translation Models for Grammatical Error Correction
Jun 01, 2016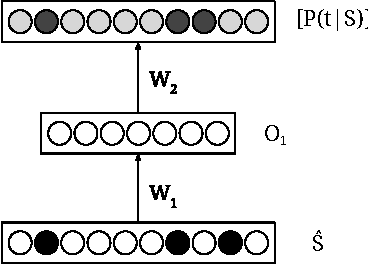
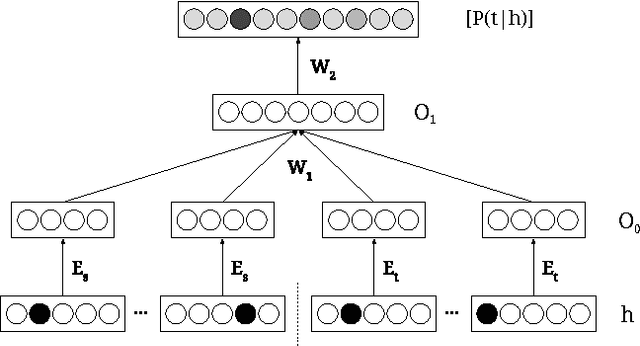

Phrase-based statistical machine translation (SMT) systems have previously been used for the task of grammatical error correction (GEC) to achieve state-of-the-art accuracy. The superiority of SMT systems comes from their ability to learn text transformations from erroneous to corrected text, without explicitly modeling error types. However, phrase-based SMT systems suffer from limitations of discrete word representation, linear mapping, and lack of global context. In this paper, we address these limitations by using two different yet complementary neural network models, namely a neural network global lexicon model and a neural network joint model. These neural networks can generalize better by using continuous space representation of words and learn non-linear mappings. Moreover, they can leverage contextual information from the source sentence more effectively. By adding these two components, we achieve statistically significant improvement in accuracy for grammatical error correction over a state-of-the-art GEC system.