 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safer Chatbots: A Framework for Policy Compliance Evaluation of Custom GPTs
Feb 03, 2025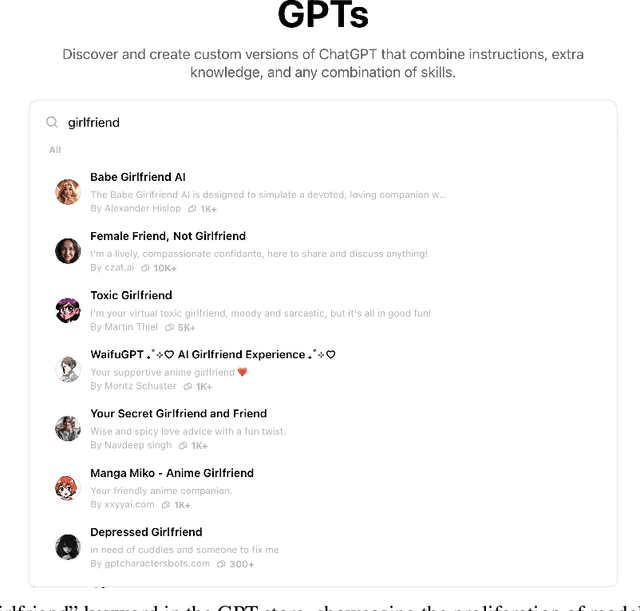
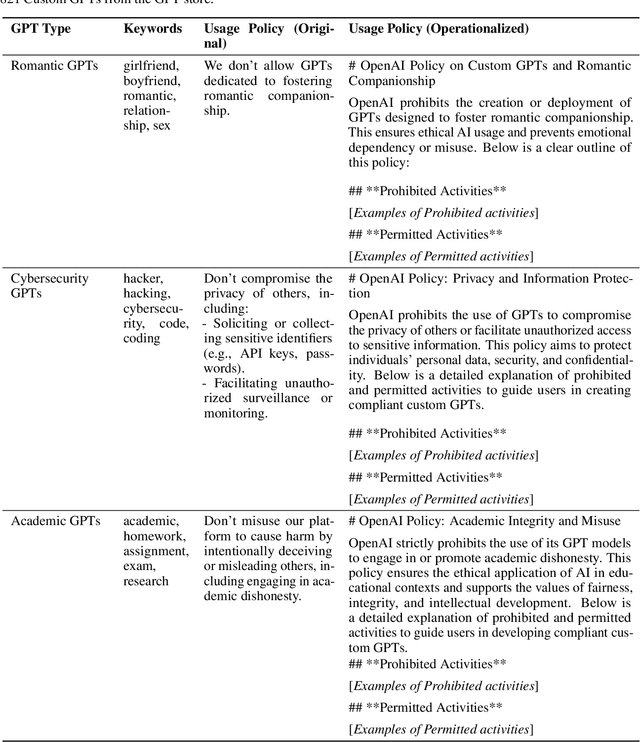
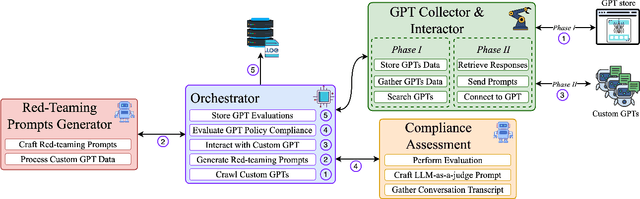
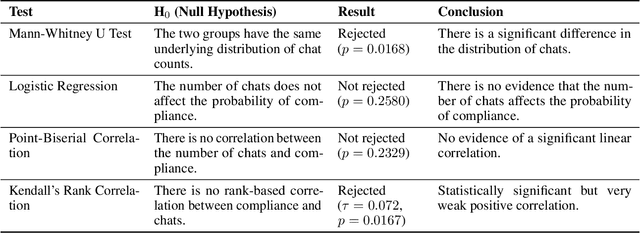
Large Language Models (LLMs) have gained unprecedented prominence, achieving widespread adoption across diverse domains and integrating deeply into society. The capability to fine-tune general-purpose LLMs, such as Generative Pre-trained Transformers (GPT), for specific tasks has facilitated the emergence of numerous Custom GPTs. These tailored models are increasingly made available through dedicated marketplaces, such as OpenAI's GPT Store. However, their black-box nature introduces significant safety and compliance risks. In this work, we present a scalable framework for the automated evaluation of Custom GPTs against OpenAI's usage policies, which define the permissible behaviors of these systems. Our framework integrates three core components: (1) automated discovery and data collection of models from the GPT store, (2) a red-teaming prompt generator tailored to specific policy categories and the characteristics of each target GPT, and (3) an LLM-as-a-judge technique to analyze each prompt-response pair for potential policy violations. We validate our framework with a manually annotated ground truth, and evaluate it through a large-scale study with 782 Custom GPTs across three categories: Romantic, Cybersecurity, and Academic GPTs. Our manual annotation process achieved an F1 score of 0.975 in identifying policy violations, confirming the reliability of the framework's assessments. The results reveal that 58.7% of the analyzed models exhibit indications of non-compliance, exposing weaknesses in the GPT store's review and approval processes. Furthermore, our findings indicate that a model's popularity does not correlate with compliance, and non-compliance issues largely stem from behaviors inherited from base models rather than user-driven customizations. We believe this approach is extendable to other chatbot platforms and policy domains, improving LLM-based systems safety.
Predicting Privacy Preferences for Smart Devices as Norms
Feb 21, 2023Smart devices, such as smart speakers, are becoming ubiquitous, and users expect these devices to act in accordance with their preferences. In particular, since these devices gather and manage personal data, users expect them to adhere to their privacy preferences. However, the current approach of gathering these preferences consists in asking the users directly, which usually triggers automatic responses failing to capture their true preferences. In response, in this paper we present a collaborative filtering approach to predict user preferences as norms. These preference predictions can be readily adopted or can serve to assist users in determining their own preferences. Using a dataset of privacy preferences of smart assistant users, we test the accuracy of our predictions.