 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safer Chatbots: A Framework for Policy Compliance Evaluation of Custom GPTs
Feb 03, 2025
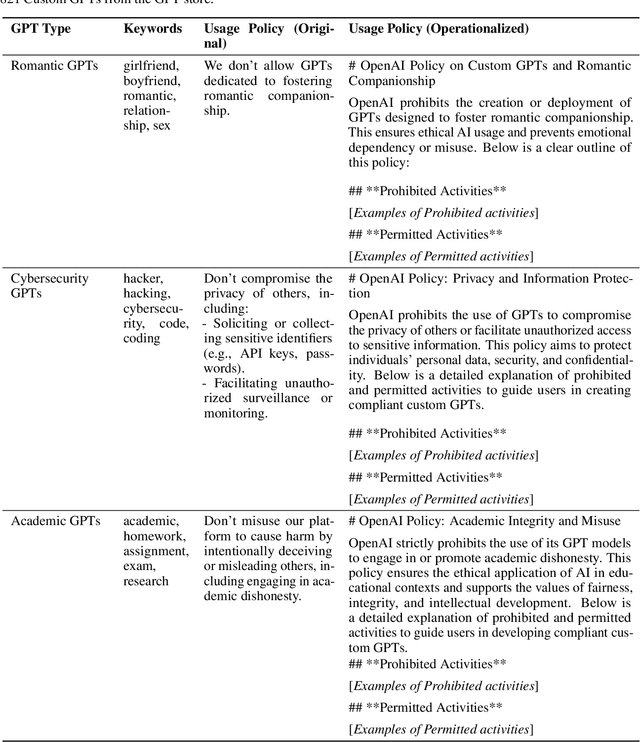
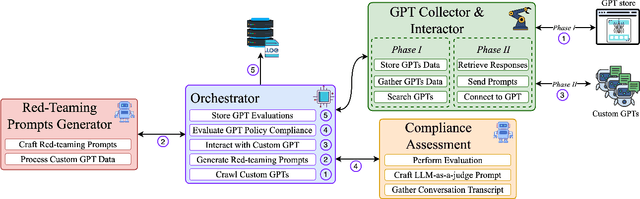
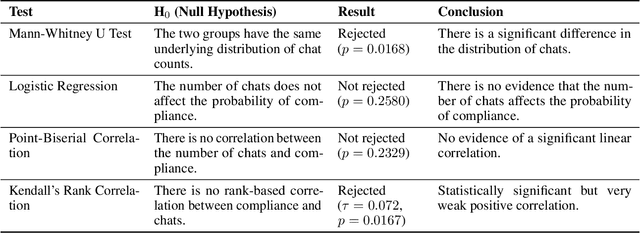
Large Language Models (LLMs) have gained unprecedented prominence, achieving widespread adoption across diverse domains and integrating deeply into society. The capability to fine-tune general-purpose LLMs, such as Generative Pre-trained Transformers (GPT), for specific tasks has facilitated the emergence of numerous Custom GPTs. These tailored models are increasingly made available through dedicated marketplaces, such as OpenAI's GPT Store. However, their black-box nature introduces significant safety and compliance risks. In this work, we present a scalable framework for the automated evaluation of Custom GPTs against OpenAI's usage policies, which define the permissible behaviors of these systems. Our framework integrates three core components: (1) automated discovery and data collection of models from the GPT store, (2) a red-teaming prompt generator tailored to specific policy categories and the characteristics of each target GPT, and (3) an LLM-as-a-judge technique to analyze each prompt-response pair for potential policy violations. We validate our framework with a manually annotated ground truth, and evaluate it through a large-scale study with 782 Custom GPTs across three categories: Romantic, Cybersecurity, and Academic GPTs. Our manual annotation process achieved an F1 score of 0.975 in identifying policy violations, confirming the reliability of the framework's assessments. The results reveal that 58.7% of the analyzed models exhibit indications of non-compliance, exposing weaknesses in the GPT store's review and approval processes. Furthermore, our findings indicate that a model's popularity does not correlate with compliance, and non-compliance issues largely stem from behaviors inherited from base models rather than user-driven customizations. We believe this approach is extendable to other chatbot platforms and policy domains, improving LLM-based systems safety.
Large Language Models: A New Approach for Privacy Policy Analysis at Scale
May 31, 2024
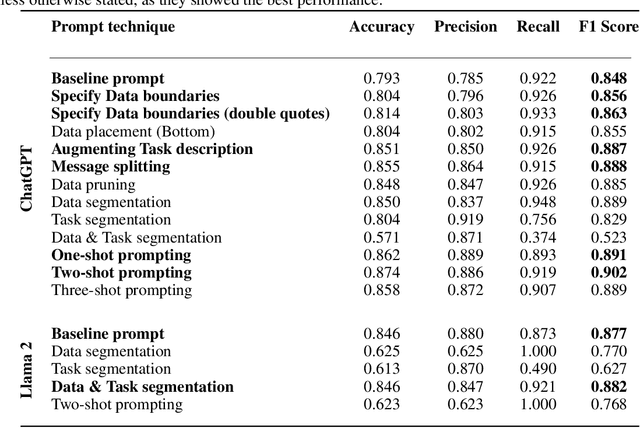
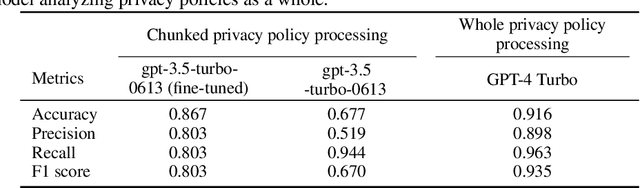
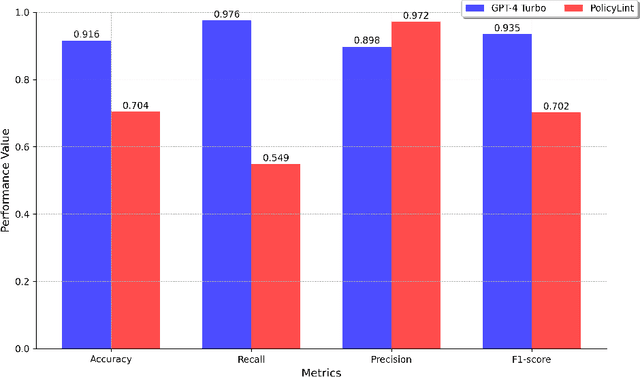
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
Automated Detection of Gait Events and Travel Distance Using Waist-worn Accelerometers Across a Typical Range of Walking and Running Speeds
Jul 10, 2023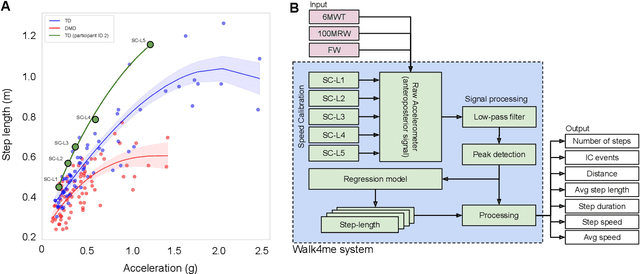
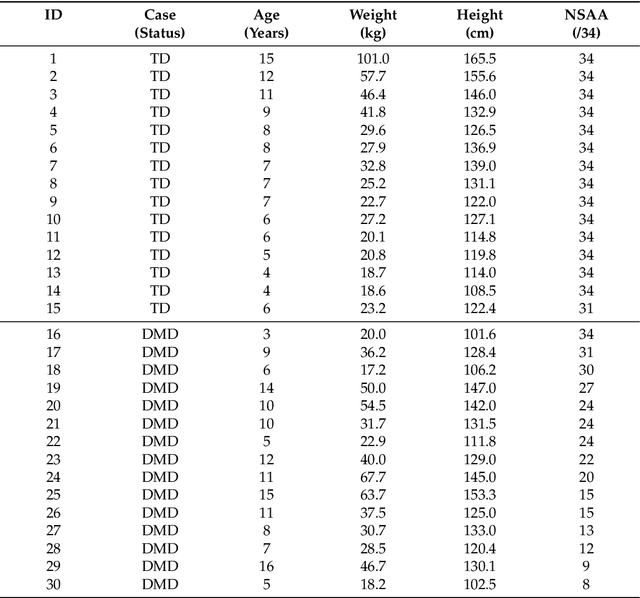
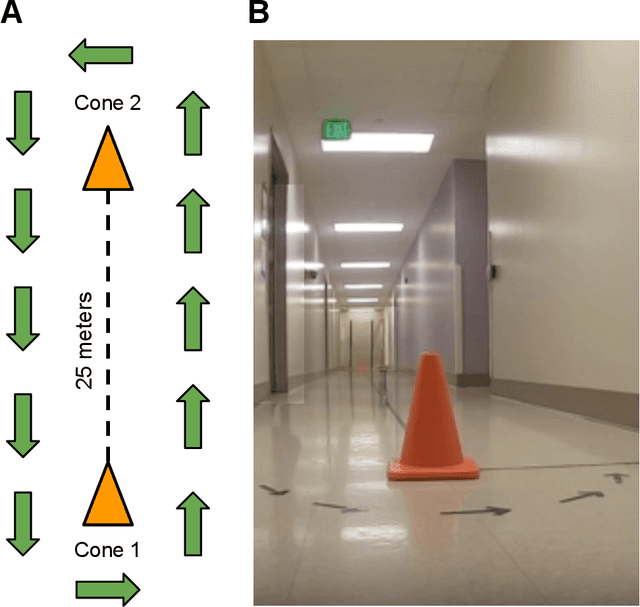
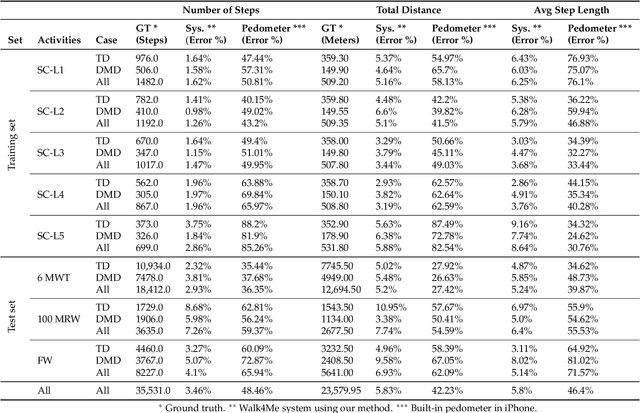
Background: Estimation of temporospatial clinical features of gait (CFs), such as step count and length, step duration, step frequency, gait speed and distance traveled is an important component of community-based mobility evaluation using wearable accelerometers. However, challenges arising from device complexity and availability, cost and analytical methodology have limited widespread application of such tools. Research Question: Can accelerometer data from commercially-available smartphones be used to extract gait CFs across a broad range of attainable gait velocities in children with Duchenne muscular dystrophy (DMD) and typically developing controls (TDs) using machine learning (ML)-based methods Methods: Fifteen children with DMD and 15 TDs underwent supervised clinical testing across a range of gait speeds using 10 or 25m run/walk (10MRW, 25MRW), 100m run/walk (100MRW), 6-minute walk (6MWT) and free-walk (FW) evaluations while wearing a mobile phone-based accelerometer at the waist near the body's center of mass. Gait CFs were extracted from the accelerometer data using a multi-step machine learning-based process and results were compared to ground-truth observation data. Results: Model predictions vs. observed values for step counts, distance traveled, and step length showed a strong correlation (Pearson's r = -0.9929 to 0.9986, p<0.0001). The estimates demonstrated a mean (SD) percentage error of 1.49% (7.04%) for step counts, 1.18% (9.91%) for distance traveled, and 0.37% (7.52%) for step length compared to ground truth observations for the combined 6MWT, 100MRW, and FW tasks. Significance: The study findings indicate that a single accelerometer placed near the body's center of mass can accurately measure CFs across different gait speeds in both TD and DMD peers, suggesting that there is potential for accurately measuring CFs in the community with consumer-level smartphones.
Valuation of Public Bus Electrification with Open Data
Sep 25, 2022
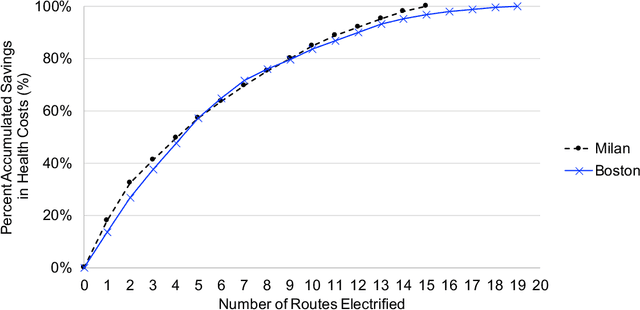
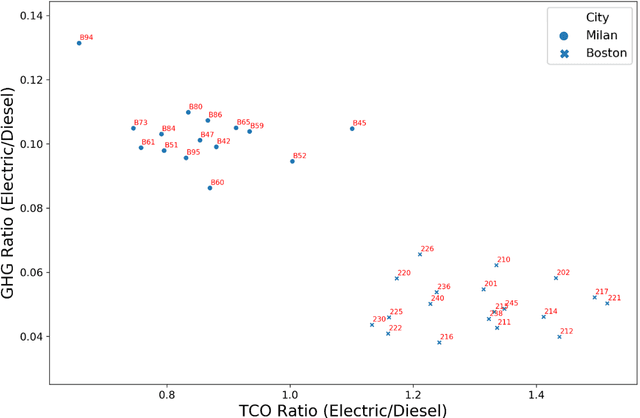

This research provides a novel framework to estimate the economic, environmental, and social values of electrifying public transit buses, for cities across the world, based on open-source data. Electric buses are a compelling candidate to replace diesel buses for the environmental and social benefits. However, the state-of-art models to evaluate the value of bus electrification are limited in applicability because they require granular and bespoke data on bus operation that can be difficult to procure. Our valuation tool uses General Transit Feed Specification, a standard data format used by transit agencies worldwide, to provide high-level guidance on developing a prioritization strategy for electrifying a bus fleet. We develop physics-informed machine learning models to evaluate the energy consumption, the carbon emissions, the health impacts, and the total cost of ownership for each transit route. We demonstrate the scalability of our tool with a case study of the bus lines in the Greater Boston and Milan metropolitan areas.
Identifying organizations receiving personal data in Android Apps
Apr 19, 2022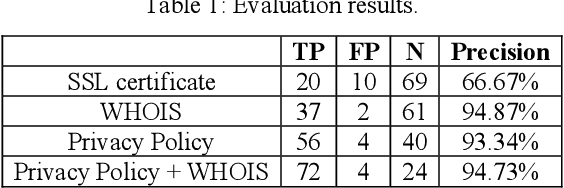
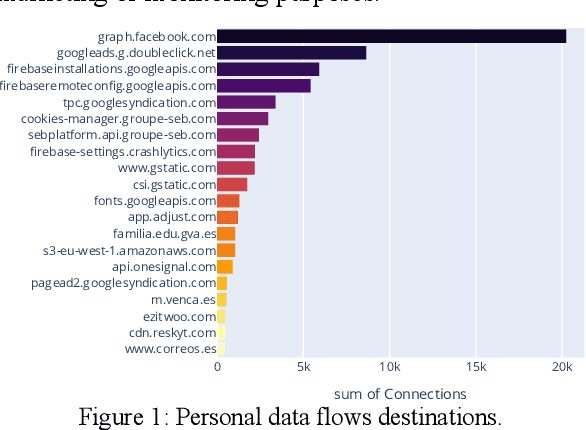
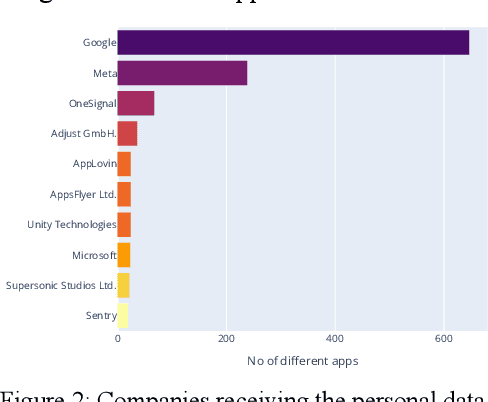
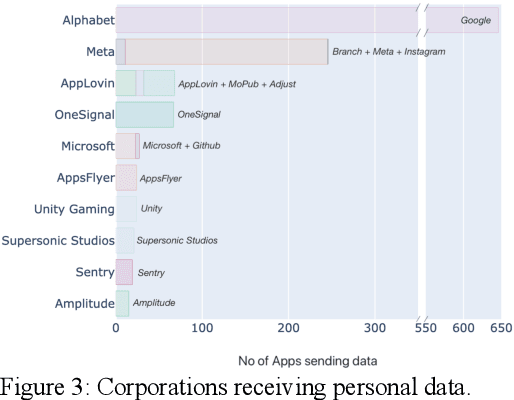
Many studies have demonstrated that mobile applications are common means to collect massive amounts of personal data. This goes unnoticed by most users, who are also unaware that many different organizations are receiving this data, even from multiple apps in parallel. This paper assesses different techniques to identify the organizations that are receiving personal data flows in the Android ecosystem, namely the WHOIS service, SSL certificates inspection, and privacy policy textual analysis. Based on our findings, we propose a fully automated method that combines the most successful techniques, achieving a 94.73% precision score in identifying the recipient organization. We further demonstrate our method by evaluating 1,000 Android apps and exposing the corporations that collect the users' personal data.