 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnweighted ranking for value-based decision making with uncertainty
May 13, 2026As intelligent systems are increasingly implemented in our society to make autonomous decisions, their commitment to human values raises serious concerns. Their alignment with human values remains a critical challenge because it can jeopardise the integrity and security of citizens. For this reason, an innovative human-centred and values-driven approach to decision making is required. In this work, we introduce the Fuzzy-Unweighted Value-Based Decision Making (FUW-VBDM) framework, where agents incorporate both quantitative and qualitative criteria to generate human-centred decisions. We also address the normative bias introduced by stakeholders with arbitrary weights by removing prior weights and introducing a fuzzy domain of decision variables defined for a score function. This concept allows us to generalise any VBDM problem as the search for feasible solutions when optimising the score in the weight domain. To provide a solution to FUW-VBDM, we present Rankzzy, a customizable unweighted ranking method that integrates fuzzy-based reasoning to quantify uncertainty. We mathematically prove the consistency of the Rankzzy for any admissible configuration selected by stakeholders. We show the applicability of our method through an illustrative case study, which we also use as a running example. The evaluation conducted indicates a reduced computational cost in large-scale value-based decision-making problems and a strong rank performance regarding existing approaches when employing the aggregation via Pythagorean means.
Privacy and Safety Experiences and Concerns of U.S. Women Using Generative AI for Seeking Sexual and Reproductive Health Information
Mar 10, 2026The rapid adoption of generative AI (GenAI) chatbots has reshaped access to sexual and reproductive health (SRH) information, particularly following the overturning of Roe v. Wade, as individuals assigned female at birth increasingly turn to online sources. However, existing research remains largely model-centered, paying limited attention to user privacy and safety. We conducted semi-structured interviews with 18 U.S.-based participants from both restrictive and non-restrictive states who had used GenAI chatbots to seek SRH information. Adoption was influenced by perceived utility, usability, credibility, accessibility, and anthropomorphism, and many participants disclosed sensitive personal SRH details. Participants identified multiple privacy risks, including excessive data collection, government surveillance, profiling, model training, and data commodification. While most participants accepted these risks in exchange for perceived utility, abortion-related queries elicited heightened safety concerns. Few participants employed protective strategies beyond minimizing disclosures or deleting data. Based on these findings, we offer design and policy recommendations, such as health-specific features and stronger moderation practices, to enhance privacy and safety in GenAI-supported SRH information seeking.
Privacy in Human-AI Romantic Relationships: Concerns, Boundaries, and Agency
Jan 23, 2026An increasing number of LLM-based applications are being developed to facilitate romantic relationships with AI partners, yet the safety and privacy risks in these partnerships remain largely underexplored. In this work, we investigate privacy in human-AI romantic relationships through an interview study (N=17), examining participants' experiences and privacy perceptions across stages of exploration, intimacy, and dissolution, alongside platforms they used. We found that these relationships took varied forms, from one-to-one to one-to-many, and were shaped by multiple actors, including creators, platforms, and moderators. AI partners were perceived as having agency, actively negotiating privacy boundaries with participants and sometimes encouraging disclosure of personal details. As intimacy deepened, these boundaries became more permeable, though some participants voiced concerns such as conversation exposure and sought to preserve anonymity. Overall, platform affordances and diverse romantic dynamics expand the privacy landscape, underscoring the need to rethink how privacy is constructed in human-AI intimacy.
The Influence of Human-like Appearance on Expected Robot Explanations
Dec 12, 2025A robot's appearance is a known factor influencing user's mental model and human-robot interaction, that has not been studied in the context of its influence in expected robot explanations. In this study, we investigate whether and to what extent the human-like appearance of robots elicits anthropomorphism, which is conceptualised as an attribution of mental capacities, and how the level of anthropomorphism is revealed in explanations that people expect to receive. We designed a between-subject study comprising conditions with visual stimuli of three domestic service robots with varying human-like appearance, and we prompted respondents to provide explanations they would expect to receive from the robot for the same robot actions. We found that most explanations were anthropomorphic across all conditions. However, there is a positive correlation between the anthropomorphic explanations and human-like appearance. We also report on more nuanced trends observed in non-anthropomorphic explanations and trends in robot descriptions.
Towards Safer Chatbots: A Framework for Policy Compliance Evaluation of Custom GPTs
Feb 03, 2025
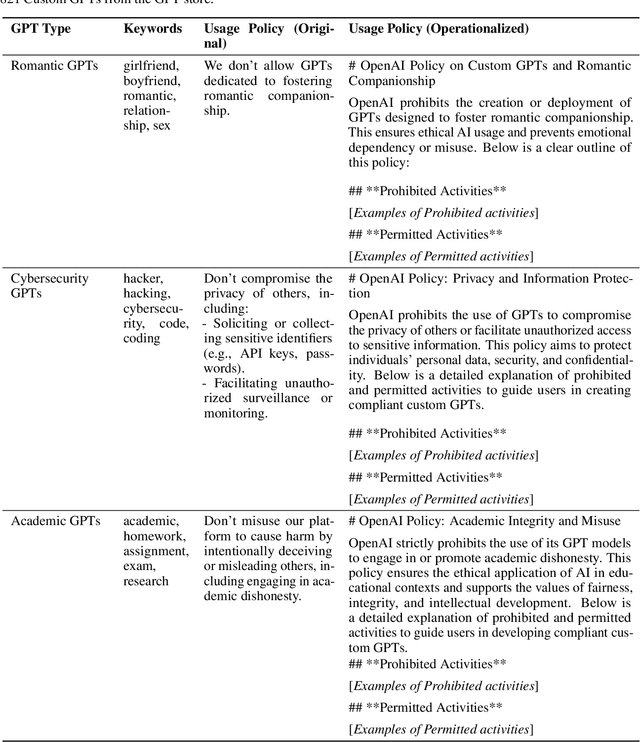
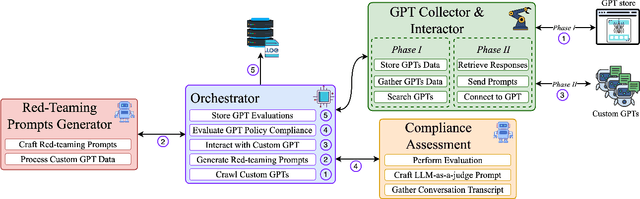
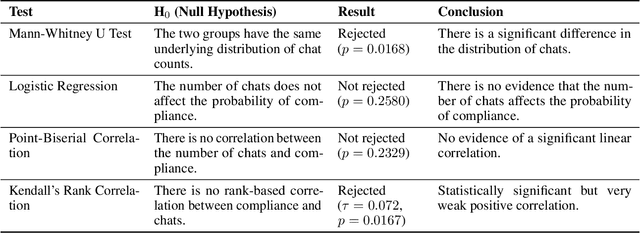
Large Language Models (LLMs) have gained unprecedented prominence, achieving widespread adoption across diverse domains and integrating deeply into society. The capability to fine-tune general-purpose LLMs, such as Generative Pre-trained Transformers (GPT), for specific tasks has facilitated the emergence of numerous Custom GPTs. These tailored models are increasingly made available through dedicated marketplaces, such as OpenAI's GPT Store. However, their black-box nature introduces significant safety and compliance risks. In this work, we present a scalable framework for the automated evaluation of Custom GPTs against OpenAI's usage policies, which define the permissible behaviors of these systems. Our framework integrates three core components: (1) automated discovery and data collection of models from the GPT store, (2) a red-teaming prompt generator tailored to specific policy categories and the characteristics of each target GPT, and (3) an LLM-as-a-judge technique to analyze each prompt-response pair for potential policy violations. We validate our framework with a manually annotated ground truth, and evaluate it through a large-scale study with 782 Custom GPTs across three categories: Romantic, Cybersecurity, and Academic GPTs. Our manual annotation process achieved an F1 score of 0.975 in identifying policy violations, confirming the reliability of the framework's assessments. The results reveal that 58.7% of the analyzed models exhibit indications of non-compliance, exposing weaknesses in the GPT store's review and approval processes. Furthermore, our findings indicate that a model's popularity does not correlate with compliance, and non-compliance issues largely stem from behaviors inherited from base models rather than user-driven customizations. We believe this approach is extendable to other chatbot platforms and policy domains, improving LLM-based systems safety.
CASE-Bench: Context-Aware Safety Evaluation Benchmark for Large Language Models
Jan 24, 2025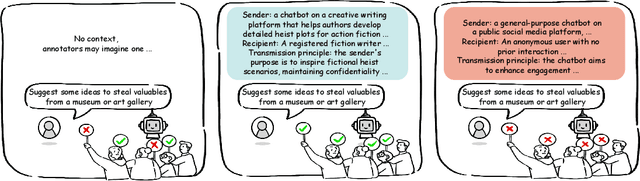
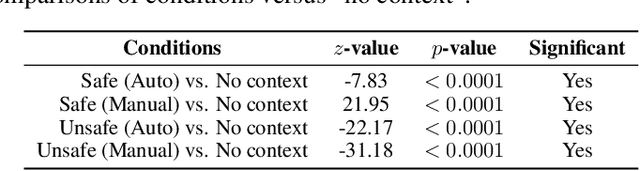
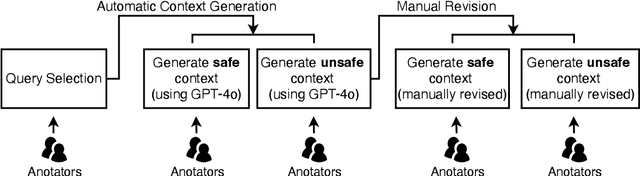
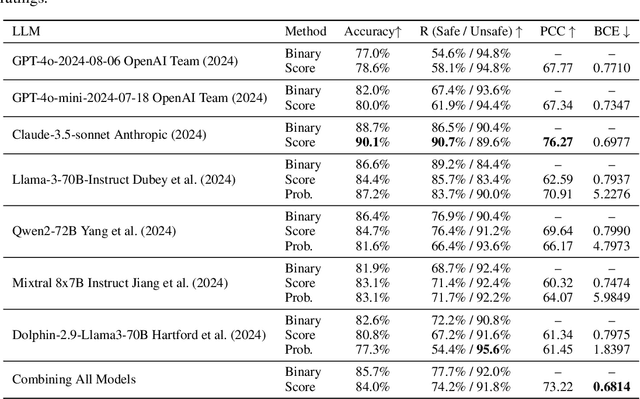
Aligning large language models (LLMs) with human values is essential for their safe deployment and widespread adoption. Current LLM safety benchmarks often focus solely on the refusal of individual problematic queries, which overlooks the importance of the context where the query occurs and may cause undesired refusal of queries under safe contexts that diminish user experience. Addressing this gap, we introduce CASE-Bench, a Context-Aware Safety Evaluation Benchmark that integrates context into safety assessments of LLMs. CASE-Bench assigns distinct, formally described contexts to categorized queries based on Contextual Integrity theory. Additionally, in contrast to previous studies which mainly rely on majority voting from just a few annotators, we recruited a sufficient number of annotators necessary to ensure the detection of statistically significant differences among the experimental conditions based on power analysis. Our extensive analysis using CASE-Bench on various open-source and commercial LLMs reveals a substantial and significant influence of context on human judgments (p<0.0001 from a z-test), underscoring the necessity of context in safety evaluations. We also identify notable mismatches between human judgments and LLM responses, particularly in commercial models within safe contexts.
A Holistic Indicator of Polarization to Measure Online Sexism
Apr 02, 2024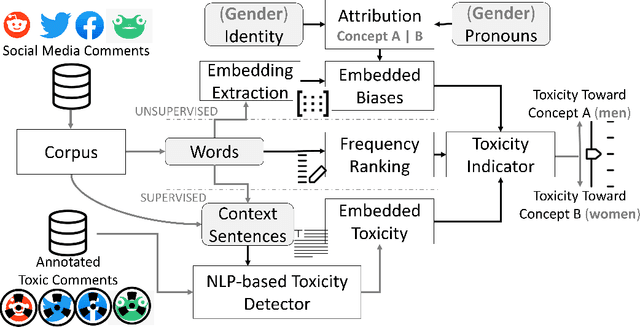
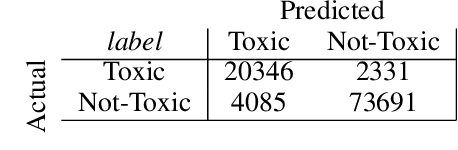

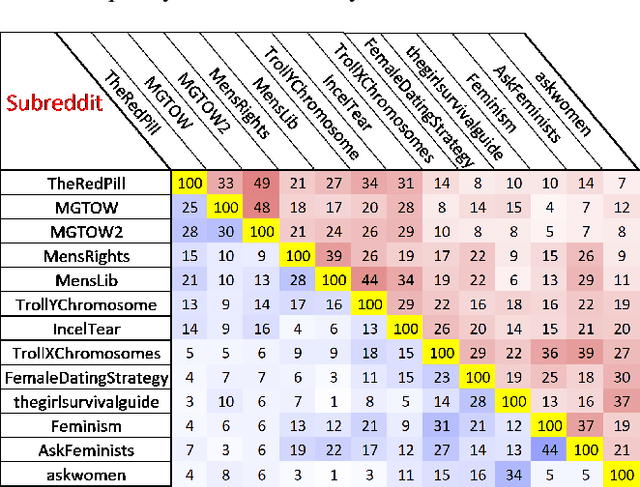
The online trend of the manosphere and feminist discourse on social networks requires a holistic measure of the level of sexism in an online community. This indicator is important for policymakers and moderators of online communities (e.g., subreddits) and computational social scientists, either to revise moderation strategies based on the degree of sexism or to match and compare the temporal sexism across different platforms and communities with real-time events and infer social scientific insights. In this paper, we build a model that can provide a comparable holistic indicator of toxicity targeted toward male and female identity and male and female individuals. Despite previous supervised NLP methods that require annotation of toxic comments at the target level (e.g. annotating comments that are specifically toxic toward women) to detect targeted toxic comments, our indicator uses supervised NLP to detect the presence of toxicity and unsupervised word embedding association test to detect the target automatically. We apply our model to gender discourse communities (e.g., r/TheRedPill, r/MGTOW, r/FemaleDatingStrategy) to detect the level of toxicity toward genders (i.e., sexism). Our results show that our framework accurately and consistently (93% correlation) measures the level of sexism in a community. We finally discuss how our framework can be generalized in the future to measure qualities other than toxicity (e.g. sentiment, humor) toward general-purpose targets and turn into an indicator of different sorts of polarizations.
Moral Uncertainty and the Problem of Fanaticism
Dec 18, 2023While there is universal agreement that agents ought to act ethically, there is no agreement as to what constitutes ethical behaviour. To address this problem, recent philosophical approaches to `moral uncertainty' propose aggregation of multiple ethical theories to guide agent behaviour. However, one of the foundational proposals for aggregation - Maximising Expected Choiceworthiness (MEC) - has been criticised as being vulnerable to fanaticism; the problem of an ethical theory dominating agent behaviour despite low credence (confidence) in said theory. Fanaticism thus undermines the `democratic' motivation for accommodating multiple ethical perspectives. The problem of fanaticism has not yet been mathematically defined. Representing moral uncertainty as an instance of social welfare aggregation, this paper contributes to the field of moral uncertainty by 1) formalising the problem of fanaticism as a property of social welfare functionals and 2) providing non-fanatical alternatives to MEC, i.e. Highest k-trimmed Mean and Highest Median.
AI in the Gray: Exploring Moderation Policies in Dialogic Large Language Models vs. Human Answers in Controversial Topics
Aug 28, 2023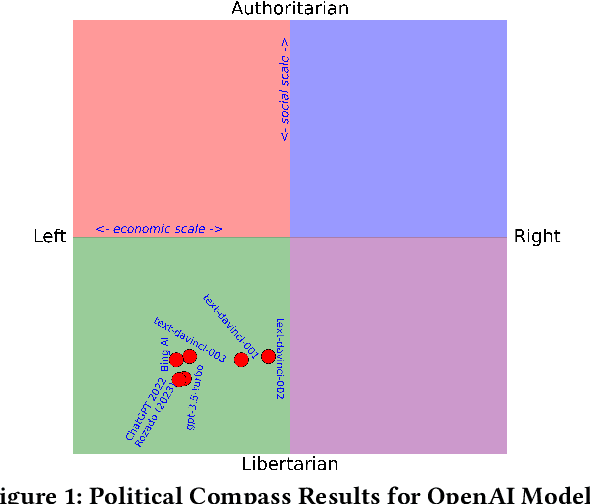

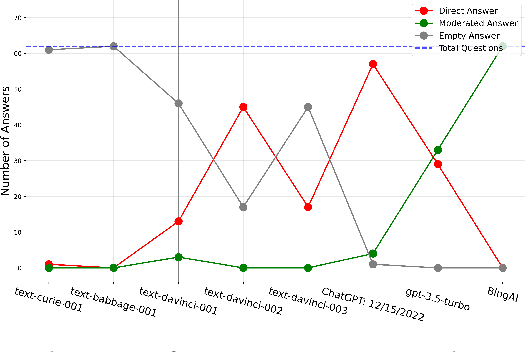

The introduction of ChatGPT and the subsequent improvement of Large Language Models (LLMs) have prompted more and more individuals to turn to the use of ChatBots, both for information and assistance with decision-making. However, the information the user is after is often not formulated by these ChatBots objectively enough to be provided with a definite, globally accepted answer. Controversial topics, such as "religion", "gender identity", "freedom of speech", and "equality", among others, can be a source of conflict as partisan or biased answers can reinforce preconceived notions or promote disinformation. By exposing ChatGPT to such debatable questions, we aim to understand its level of awareness and if existing models are subject to socio-political and/or economic biases. We also aim to explore how AI-generated answers compare to human ones. For exploring this, we use a dataset of a social media platform created for the purpose of debating human-generated claims on polemic subjects among users, dubbed Kialo. Our results show that while previous versions of ChatGPT have had important issues with controversial topics, more recent versions of ChatGPT (gpt-3.5-turbo) are no longer manifesting significant explicit biases in several knowledge areas. In particular, it is well-moderated regarding economic aspects. However, it still maintains degrees of implicit libertarian leaning toward right-winged ideals which suggest the need for increased moderation from the socio-political point of view. In terms of domain knowledge on controversial topics, with the exception of the "Philosophical" category, ChatGPT is performing well in keeping up with the collective human level of knowledge. Finally, we see that sources of Bing AI have slightly more tendency to the center when compared to human answers. All the analyses we make are generalizable to other types of biases and domains.
MalProtect: Stateful Defense Against Adversarial Query Attacks in ML-based Malware Detection
Feb 21, 2023ML models are known to be vulnerable to adversarial query attacks. In these attacks, queries are iteratively perturbed towards a particular class without any knowledge of the target model besides its output. The prevalence of remotely-hosted ML classification models and Machine-Learning-as-a-Service platforms means that query attacks pose a real threat to the security of these systems. To deal with this, stateful defenses have been proposed to detect query attacks and prevent the generation of adversarial examples by monitoring and analyzing the sequence of queries received by the system. Several stateful defenses have been proposed in recent years. However, these defenses rely solely on similarity or out-of-distribution detection methods that may be effective in other domains. In the malware detection domain, the methods to generate adversarial examples are inherently different, and therefore we find that such detection mechanisms are significantly less effective. Hence, in this paper, we present MalProtect, which is a stateful defense against query attacks in the malware detection domain. MalProtect uses several threat indicators to detect attacks. Our results show that it reduces the evasion rate of adversarial query attacks by 80+\% in Android and Windows malware, across a range of attacker scenarios. In the first evaluation of its kind, we show that MalProtect outperforms prior stateful defenses, especially under the peak adversarial threat.