 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the GDPR Compliance Assessment for Cross-border Personal Data Transfers in Android Applications
Mar 12, 2021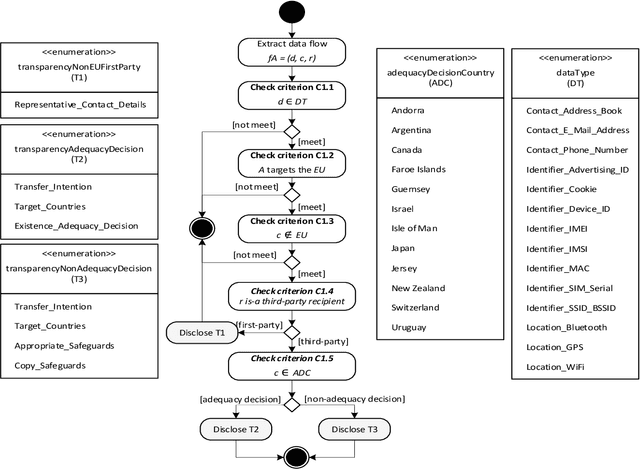
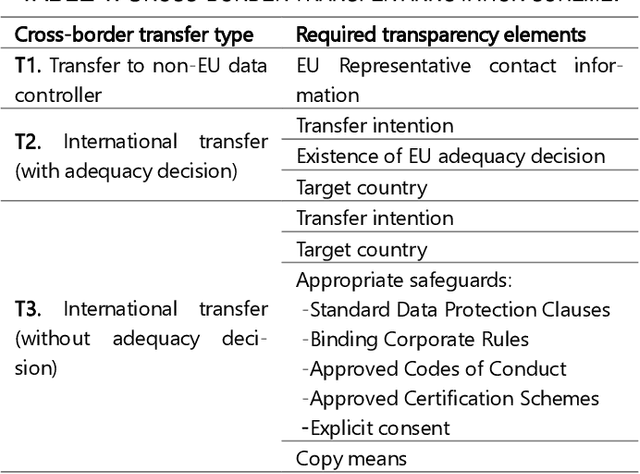
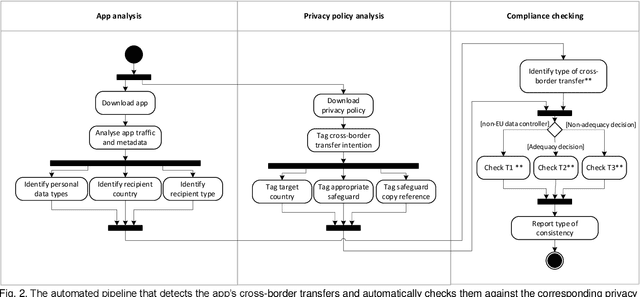
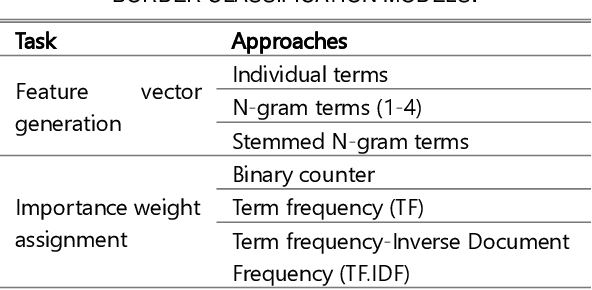
The General Data Protection Regulation (GDPR) aims to ensure that all personal data processing activities are fair and transparent for the European Union (EU) citizens, regardless of whether these are carried out within the EU or anywhere else. To this end, it sets strict requirements to transfer personal data outside the EU. However, checking these requirements is a daunting task for supervisory authorities, particularly in the mobile app domain due to the huge number of apps available and their dynamic nature. In this paper, we propose a fully automated method to assess the compliance of mobile apps with the GDPR requirements for cross-border personal data transfers. We have applied the method to the top-free 10,080 apps from the Google Play Store. The results reveal that there is still a very significant gap between what app providers and third-party recipients do in practice and what is intended by the GDPR. A substantial 56% of analysed apps are potentially non-compliant with the GDPR cross-border transfer requirements.
Discovering and Categorising Language Biases in Reddit
Aug 13, 2020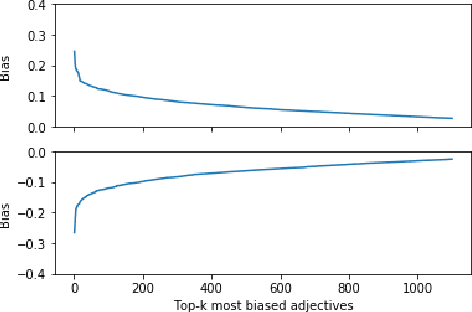


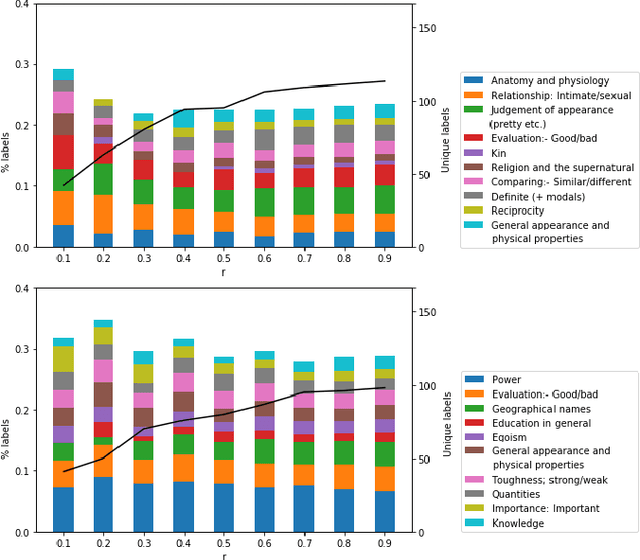
We present a data-driven approach using word embeddings to discover and categorise language biases on the discussion platform Reddit. As spaces for isolated user communities, platforms such as Reddit are increasingly connected to issues of racism, sexism and other forms of discrimination. Hence, there is a need to monitor the language of these groups. One of the most promising AI approaches to trace linguistic biases in large textual datasets involves word embeddings, which transform text into high-dimensional dense vectors and capture semantic relations between words. Yet, previous studies require predefined sets of potential biases to study, e.g., whether gender is more or less associated with particular types of jobs. This makes these approaches unfit to deal with smaller and community-centric datasets such as those on Reddit, which contain smaller vocabularies and slang, as well as biases that may be particular to that community. This paper proposes a data-driven approach to automatically discover language biases encoded in the vocabulary of online discourse communities on Reddit. In our approach, protected attributes are connected to evaluative words found in the data, which are then categorised through a semantic analysis system. We verify the effectiveness of our method by comparing the biases we discover in the Google News dataset with those found in previous literature. We then successfully discover gender bias, religion bias, and ethnic bias in different Reddit communities. We conclude by discussing potential application scenarios and limitations of this data-driven bias discovery method.
* Author's copy of the paper accepted at the International AAAI Conference on Web and Social Media (ICWSM 2021)
Bias and Discrimination in AI: a cross-disciplinary perspective
Aug 11, 2020With the widespread and pervasive use of Artificial Intelligence (AI) for automated decision-making systems, AI bias is becoming more apparent and problematic. One of its negative consequences is discrimination: the unfair, or unequal treatment of individuals based on certain characteristics. However, the relationship between bias and discrimination is not always clear. In this paper, we survey relevant literature about bias and discrimination in AI from an interdisciplinary perspective that embeds technical, legal, social and ethical dimensions. We show that finding solutions to bias and discrimination in AI requires robust cross-disciplinary collaborations.
A Normative approach to Attest Digital Discrimination
Aug 03, 2020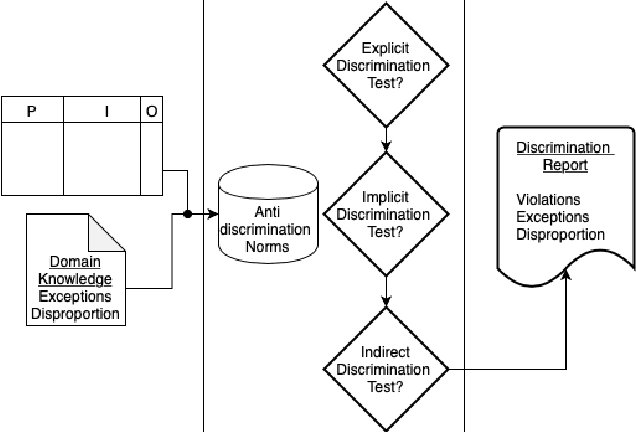
Digital discrimination is a form of discrimination whereby users are automatically treated unfairly, unethically or just differently based on their personal data by a machine learning (ML) system. Examples of digital discrimination include low-income neighbourhood's targeted with high-interest loans or low credit scores, and women being undervalued by 21% in online marketing. Recently, different techniques and tools have been proposed to detect biases that may lead to digital discrimination. These tools often require technical expertise to be executed and for their results to be interpreted. To allow non-technical users to benefit from ML, simpler notions and concepts to represent and reason about digital discrimination are needed. In this paper, we use norms as an abstraction to represent different situations that may lead to digital discrimination. In particular, we formalise non-discrimination norms in the context of ML systems and propose an algorithm to check whether ML systems violate these norms.