 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Interpreting Conceptual Biases in Online Communities
Oct 27, 2020


Language carries implicit human biases, functioning both as a reflection and a perpetuation of stereotypes that people carry with them. Recently, ML-based NLP methods such as word embeddings have been shown to learn such language biases with striking accuracy. This capability of word embeddings has been successfully exploited as a tool to quantify and study human biases. However, previous studies only consider a predefined set of conceptual biases to attest (e.g., whether gender is more or less associated with particular jobs), or just discover biased words without helping to understand their meaning at the conceptual level. As such, these approaches are either unable to find conceptual biases that have not been defined in advance, or the biases they find are difficult to interpret and study. This makes existing approaches unsuitable to discover and interpret biases in online communities, as such communities may carry different biases than those in mainstream culture. This paper proposes a general, data-driven approach to automatically discover and help interpret conceptual biases encoded in word embeddings. We apply this approach to study the conceptual biases present in the language used in online communities and experimentally show the validity and stability of our method.
Discovering and Categorising Language Biases in Reddit
Aug 13, 2020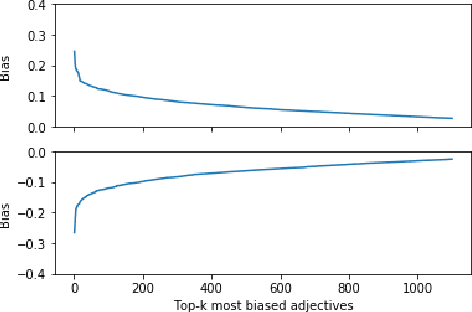


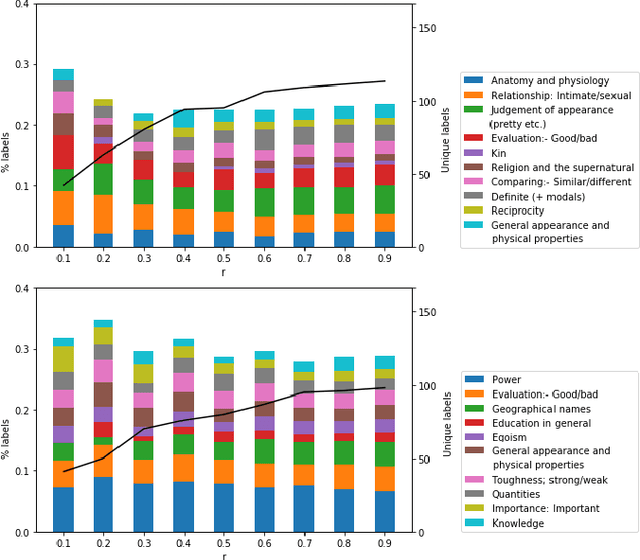
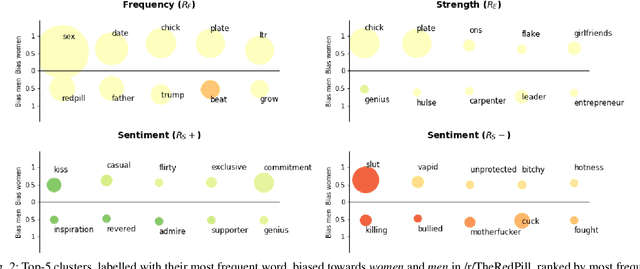
We present a data-driven approach using word embeddings to discover and categorise language biases on the discussion platform Reddit. As spaces for isolated user communities, platforms such as Reddit are increasingly connected to issues of racism, sexism and other forms of discrimination. Hence, there is a need to monitor the language of these groups. One of the most promising AI approaches to trace linguistic biases in large textual datasets involves word embeddings, which transform text into high-dimensional dense vectors and capture semantic relations between words. Yet, previous studies require predefined sets of potential biases to study, e.g., whether gender is more or less associated with particular types of jobs. This makes these approaches unfit to deal with smaller and community-centric datasets such as those on Reddit, which contain smaller vocabularies and slang, as well as biases that may be particular to that community. This paper proposes a data-driven approach to automatically discover language biases encoded in the vocabulary of online discourse communities on Reddit. In our approach, protected attributes are connected to evaluative words found in the data, which are then categorised through a semantic analysis system. We verify the effectiveness of our method by comparing the biases we discover in the Google News dataset with those found in previous literature. We then successfully discover gender bias, religion bias, and ethnic bias in different Reddit communities. We conclude by discussing potential application scenarios and limitations of this data-driven bias discovery method.
* Author's copy of the paper accepted at the International AAAI Conference on Web and Social Media (ICWSM 2021)
Bias and Discrimination in AI: a cross-disciplinary perspective
Aug 11, 2020With the widespread and pervasive use of Artificial Intelligence (AI) for automated decision-making systems, AI bias is becoming more apparent and problematic. One of its negative consequences is discrimination: the unfair, or unequal treatment of individuals based on certain characteristics. However, the relationship between bias and discrimination is not always clear. In this paper, we survey relevant literature about bias and discrimination in AI from an interdisciplinary perspective that embeds technical, legal, social and ethical dimensions. We show that finding solutions to bias and discrimination in AI requires robust cross-disciplinary collaborations.
A Normative approach to Attest Digital Discrimination
Aug 03, 2020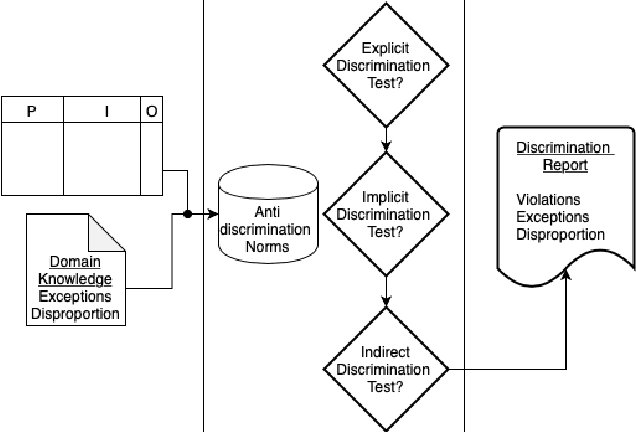
Digital discrimination is a form of discrimination whereby users are automatically treated unfairly, unethically or just differently based on their personal data by a machine learning (ML) system. Examples of digital discrimination include low-income neighbourhood's targeted with high-interest loans or low credit scores, and women being undervalued by 21% in online marketing. Recently, different techniques and tools have been proposed to detect biases that may lead to digital discrimination. These tools often require technical expertise to be executed and for their results to be interpreted. To allow non-technical users to benefit from ML, simpler notions and concepts to represent and reason about digital discrimination are needed. In this paper, we use norms as an abstraction to represent different situations that may lead to digital discrimination. In particular, we formalise non-discrimination norms in the context of ML systems and propose an algorithm to check whether ML systems violate these norms.
Attesting Biases and Discrimination using Language Semantics
Sep 10, 2019AI agents are increasingly deployed and used to make automated decisions that affect our lives on a daily basis. It is imperative to ensure that these systems embed ethical principles and respect human values. We focus on how we can attest to whether AI agents treat users fairly without discriminating against particular individuals or groups through biases in language. In particular, we discuss human unconscious biases, how they are embedded in language, and how AI systems inherit those biases by learning from and processing human language. Then, we outline a roadmap for future research to better understand and attest problematic AI biases derived from language.
Norm Monitoring under Partial Action Observability
Apr 21, 2016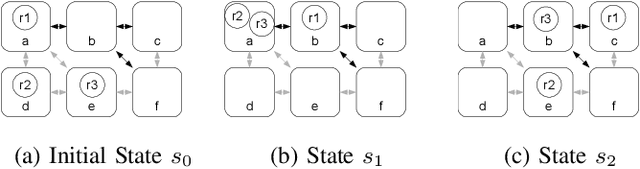

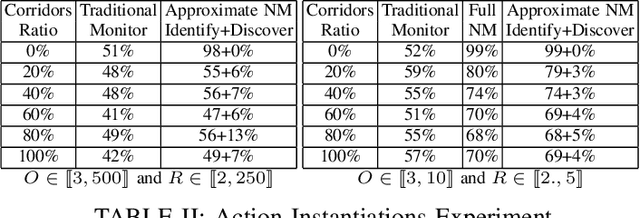
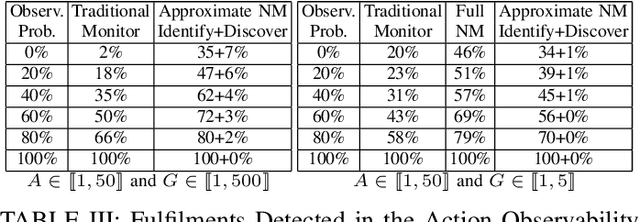
In the context of using norms for controlling multi-agent systems, a vitally important question that has not yet been addressed in the literature is the development of mechanisms for monitoring norm compliance under partial action observability. This paper proposes the reconstruction of unobserved actions to tackle this problem. In particular, we formalise the problem of reconstructing unobserved actions, and propose an information model and algorithms for monitoring norms under partial action observability using two different processes for reconstructing unobserved actions. Our evaluation shows that reconstructing unobserved actions increases significantly the number of norm violations and fulfilments detected.
Implicit Contextual Integrity in Online Social Networks
Jul 06, 2015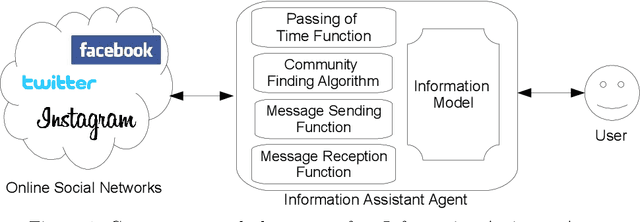

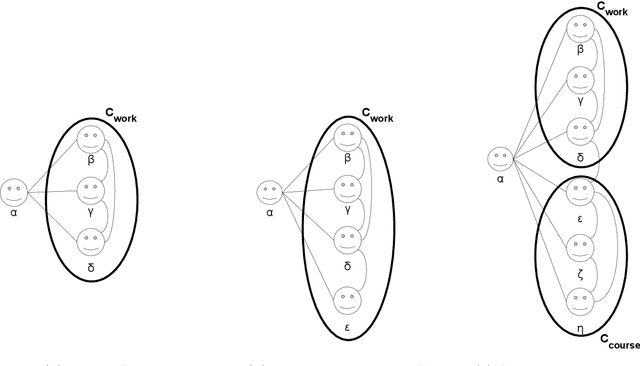

Many real incidents demonstrate that users of Online Social Networks need mechanisms that help them manage their interactions by increasing the awareness of the different contexts that coexist in Online Social Networks and preventing them from exchanging inappropriate information in those contexts or disseminating sensitive information from some contexts to others. Contextual integrity is a privacy theory that conceptualises the appropriateness of information sharing based on the contexts in which this information is to be shared. Computational models of Contextual Integrity assume the existence of well-defined contexts, in which individuals enact pre-defined roles and information sharing is governed by an explicit set of norms. However, contexts in Online Social Networks are known to be implicit, unknown a priori and ever changing; users relationships are constantly evolving; and the information sharing norms are implicit. This makes current Contextual Integrity models not suitable for Online Social Networks. In this paper, we propose the first computational model of Implicit Contextual Integrity, presenting an information model and an Information Assistant Agent that uses the information model to learn implicit contexts, relationships and the information sharing norms to help users avoid inappropriate information exchanges and undesired information disseminations. Through an experimental evaluation, we validate the properties of Information Assistant Agents, which are shown to: infer the information sharing norms even if a small proportion of the users follow the norms and in presence of malicious users; help reduce the exchange of inappropriate information and the dissemination of sensitive information with only a partial view of the system and the information received and sent by their users; and minimise the burden to the users in terms of raising unnecessary alerts.
* Authors Version of the paper accepted for publication in the Information Sciences journal (http://www.journals.elsevier.com/information-sciences/)