 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition Without Authorization: LLMs and the Moral Order of Online Advice
Apr 24, 2026Large language models are increasingly used to mediate everyday interpersonal dilemmas, yet how their advisory defaults interact with the concentrated moral orders of specific communities remains poorly understood. This article compares four assistant-style LLMs with community-endorsed advice on 11,565 posts from r/relationship_advice, using the subreddit as a concentrated, vote-ratified moral formation whose prescriptive clarity makes divergence measurable. Across models, LLMs identify many of the same dynamics as human commenters, but are markedly less likely to convert that recognition into directive authorization for action. The gap is sharpest where community consensus is strongest: on high-consensus posts involving abuse or safety threats, models recommend exit at roughly half the human rate while maintaining elevated levels of hedging, validation, and therapeutic framing. The article describes this pattern as recognition without authorization: the capacity to register harm while withholding socially ratified permission for consequential action. This divergence is not incidental but structural: a portable advisory style that remains validating, risk-averse, and weakly directive across contexts. Safety alignment is one plausible contributor to this pattern, alongside training-data averaging and broader assistant design. The article argues that model divergence can be reframed from a technical error to a way of seeing what standardized assistant norms flatten when they encounter situated moral worlds.
Voice Under Revision: Large Language Models and the Normalization of Personal Narrative
Apr 24, 2026This study examines how large language model rewriting alters the style and narrative texture of personal narratives. It analyzes 300 personal narratives rewritten by three frontier LLMs under three prompt conditions: generic improvement, rewrite-only, and voice-preserving revision. Change is measured across 13 linguistic markers drawn from computational stylistics, including function words, vocabulary diversity, word length, punctuation, contractions, first-person pronouns, and emotion words. Across models and prompt conditions, LLM rewriting produces a consistent pattern of stylistic normalization. Function words, contractions, and first-person pronouns decrease, while vocabulary diversity, word length, and punctuation elaboration increase. These shifts occur whether the prompt asks the model to "improve" the text or simply to "rewrite" it. Voice-preserving prompts reduce the magnitude of the changes but do not eliminate their direction. Stylometric analysis shows that rewritten texts converge in feature space and become harder to match back to their source texts. Additional narrative markers indicate a shift from embedded to distanced narration, and from explicit causal reasoning to compressed abstraction. The findings suggest that contemporary LLMs exert a directional pull toward a more polished, less situated register. This has consequences for digital humanities and computational text analysis, where features such as function words, pronouns, contractions, and punctuation often serve as evidence for style, voice, authorship, and corpus integrity. LLM revision should therefore be understood not merely as surface-level editing, but as a consequential form of textual mediation.
Normative Evaluation of Large Language Models with Everyday Moral Dilemmas
Jan 30, 2025The rapid adoption of large language models (LLMs) has spurred extensive research into their encoded moral norms and decision-making processes. Much of this research relies on prompting LLMs with survey-style questions to assess how well models are aligned with certain demographic groups, moral beliefs, or political ideologies. While informative, the adherence of these approaches to relatively superficial constructs tends to oversimplify the complexity and nuance underlying everyday moral dilemmas. We argue that auditing LLMs along more detailed axes of human interaction is of paramount importance to better assess the degree to which they may impact human beliefs and actions. To this end, we evaluate LLMs on complex, everyday moral dilemmas sourced from the "Am I the Asshole" (AITA) community on Reddit, where users seek moral judgments on everyday conflicts from other community members. We prompted seven LLMs to assign blame and provide explanations for over 10,000 AITA moral dilemmas. We then compared the LLMs' judgments and explanations to those of Redditors and to each other, aiming to uncover patterns in their moral reasoning. Our results demonstrate that large language models exhibit distinct patterns of moral judgment, varying substantially from human evaluations on the AITA subreddit. LLMs demonstrate moderate to high self-consistency but low inter-model agreement. Further analysis of model explanations reveals distinct patterns in how models invoke various moral principles. These findings highlight the complexity of implementing consistent moral reasoning in artificial systems and the need for careful evaluation of how different models approach ethical judgment. As LLMs continue to be used in roles requiring ethical decision-making such as therapists and companions, careful evaluation is crucial to mitigate potential biases and limitations.
Discovering and Interpreting Conceptual Biases in Online Communities
Oct 27, 2020

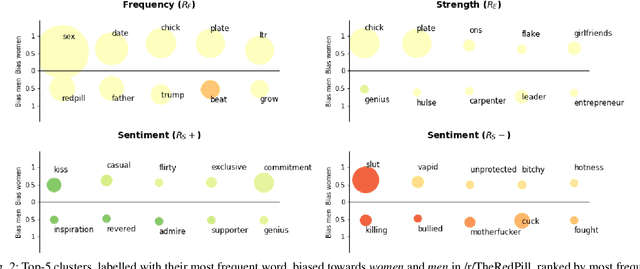

Language carries implicit human biases, functioning both as a reflection and a perpetuation of stereotypes that people carry with them. Recently, ML-based NLP methods such as word embeddings have been shown to learn such language biases with striking accuracy. This capability of word embeddings has been successfully exploited as a tool to quantify and study human biases. However, previous studies only consider a predefined set of conceptual biases to attest (e.g., whether gender is more or less associated with particular jobs), or just discover biased words without helping to understand their meaning at the conceptual level. As such, these approaches are either unable to find conceptual biases that have not been defined in advance, or the biases they find are difficult to interpret and study. This makes existing approaches unsuitable to discover and interpret biases in online communities, as such communities may carry different biases than those in mainstream culture. This paper proposes a general, data-driven approach to automatically discover and help interpret conceptual biases encoded in word embeddings. We apply this approach to study the conceptual biases present in the language used in online communities and experimentally show the validity and stability of our method.
Discovering and Categorising Language Biases in Reddit
Aug 13, 2020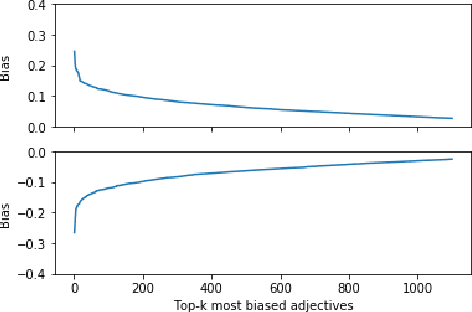


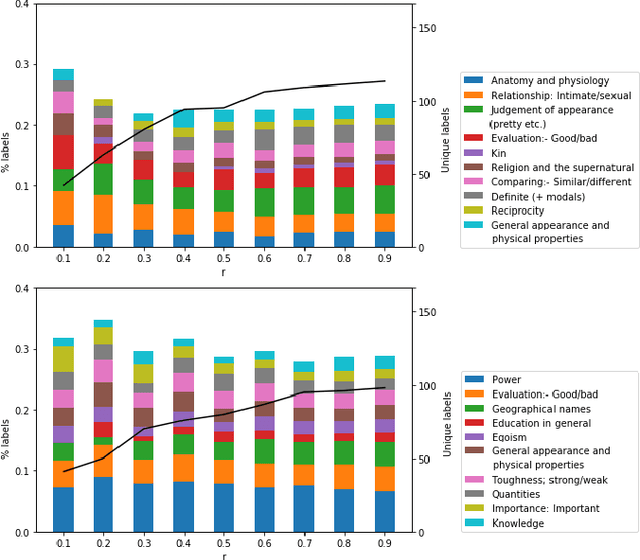
We present a data-driven approach using word embeddings to discover and categorise language biases on the discussion platform Reddit. As spaces for isolated user communities, platforms such as Reddit are increasingly connected to issues of racism, sexism and other forms of discrimination. Hence, there is a need to monitor the language of these groups. One of the most promising AI approaches to trace linguistic biases in large textual datasets involves word embeddings, which transform text into high-dimensional dense vectors and capture semantic relations between words. Yet, previous studies require predefined sets of potential biases to study, e.g., whether gender is more or less associated with particular types of jobs. This makes these approaches unfit to deal with smaller and community-centric datasets such as those on Reddit, which contain smaller vocabularies and slang, as well as biases that may be particular to that community. This paper proposes a data-driven approach to automatically discover language biases encoded in the vocabulary of online discourse communities on Reddit. In our approach, protected attributes are connected to evaluative words found in the data, which are then categorised through a semantic analysis system. We verify the effectiveness of our method by comparing the biases we discover in the Google News dataset with those found in previous literature. We then successfully discover gender bias, religion bias, and ethnic bias in different Reddit communities. We conclude by discussing potential application scenarios and limitations of this data-driven bias discovery method.
* Author's copy of the paper accepted at the International AAAI Conference on Web and Social Media (ICWSM 2021)
Bias and Discrimination in AI: a cross-disciplinary perspective
Aug 11, 2020With the widespread and pervasive use of Artificial Intelligence (AI) for automated decision-making systems, AI bias is becoming more apparent and problematic. One of its negative consequences is discrimination: the unfair, or unequal treatment of individuals based on certain characteristics. However, the relationship between bias and discrimination is not always clear. In this paper, we survey relevant literature about bias and discrimination in AI from an interdisciplinary perspective that embeds technical, legal, social and ethical dimensions. We show that finding solutions to bias and discrimination in AI requires robust cross-disciplinary collaborations.