 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Interpreting Conceptual Biases in Online Communities
Oct 27, 2020

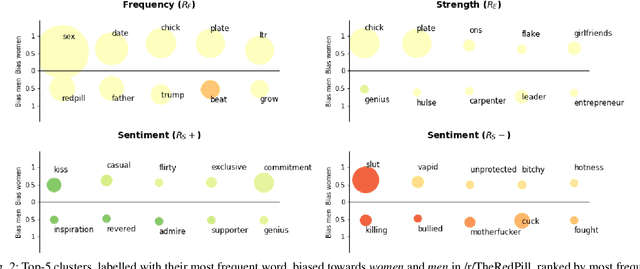

Language carries implicit human biases, functioning both as a reflection and a perpetuation of stereotypes that people carry with them. Recently, ML-based NLP methods such as word embeddings have been shown to learn such language biases with striking accuracy. This capability of word embeddings has been successfully exploited as a tool to quantify and study human biases. However, previous studies only consider a predefined set of conceptual biases to attest (e.g., whether gender is more or less associated with particular jobs), or just discover biased words without helping to understand their meaning at the conceptual level. As such, these approaches are either unable to find conceptual biases that have not been defined in advance, or the biases they find are difficult to interpret and study. This makes existing approaches unsuitable to discover and interpret biases in online communities, as such communities may carry different biases than those in mainstream culture. This paper proposes a general, data-driven approach to automatically discover and help interpret conceptual biases encoded in word embeddings. We apply this approach to study the conceptual biases present in the language used in online communities and experimentally show the validity and stability of our method.