 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Analytics for Fine-grained Text Classification Models and Datasets
Mar 21, 2024In natural language processing (NLP), text classification tasks are increasingly fine-grained, as datasets are fragmented into a larger number of classes that are more difficult to differentiate from one another. As a consequence, the semantic structures of datasets have become more complex, and model decisions more difficult to explain. Existing tools, suited for coarse-grained classification, falter under these additional challenges. In response to this gap, we worked closely with NLP domain experts in an iterative design-and-evaluation process to characterize and tackle the growing requirements in their workflow of developing fine-grained text classification models. The result of this collaboration is the development of SemLa, a novel visual analytics system tailored for 1) dissecting complex semantic structures in a dataset when it is spatialized in model embedding space, and 2) visualizing fine-grained nuances in the meaning of text samples to faithfully explain model reasoning. This paper details the iterative design study and the resulting innovations featured in SemLa. The final design allows contrastive analysis at different levels by unearthing lexical and conceptual patterns including biases and artifacts in data. Expert feedback on our final design and case studies confirm that SemLa is a useful tool for supporting model validation and debugging as well as data annotation.
A Bounded Measure for Estimating the Benefit of Visualization
Feb 12, 2020


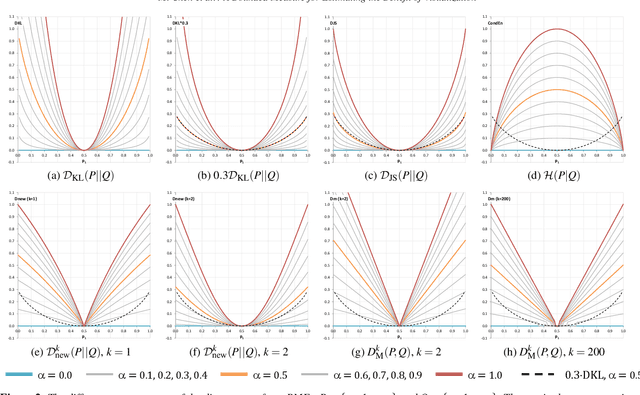
Information theory can be used to analyze the cost-benefit of visualization processes. However, the current measure of benefit contains an unbounded term that is neither easy to estimate nor intuitive to interpret. In this work, we propose to revise the existing cost-benefit measure by replacing the unbounded term with a bounded one. We examine a number of bounded measures that include the Jenson-Shannon divergence and a new divergence measure formulated as part of this work. We use visual analysis to support the multi-criteria comparison, enabling the selection of the most logical and intuitive option. We applied the revised cost-benefit measure to two case studies, demonstrating its uses in practical scenarios, while the collected real world data further informs the selection of a bounded measure.