 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBXRL: Behavior-Explainable Reinforcement Learning
Mar 24, 2026A major challenge of Reinforcement Learning is that agents often learn undesired behaviors that seem to defy the reward structure they were given. Explainable Reinforcement Learning (XRL) methods can answer queries such as "explain this specific action", "explain this specific trajectory", and "explain the entire policy". However, XRL lacks a formal definition for behavior as a pattern of actions across many episodes. We provide such a definition, and use it to enable a new query: "Explain this behavior". We present Behavior-Explainable Reinforcement Learning (BXRL), a new problem formulation that treats behaviors as first-class objects. BXRL defines a behavior measure as any function $m : Π\to \mathbb{R}$, allowing users to precisely express the pattern of actions that they find interesting and measure how strongly the policy exhibits it. We define contrastive behaviors that reduce the question "why does the agent prefer $a$ to $a'$?" to "why is $m(π)$ high?" which can be explored with differentiation. We do not implement an explainability method; we instead analyze three existing methods and propose how they could be adapted to explain behavior. We present a port of the HighwayEnv driving environment to JAX, which provides an interface for defining, measuring, and differentiating behaviors with respect to the model parameters.
Gap the (Theory of) Mind: Sharing Beliefs About Teammates' Goals Boosts Collaboration Perception, Not Performance
May 06, 2025
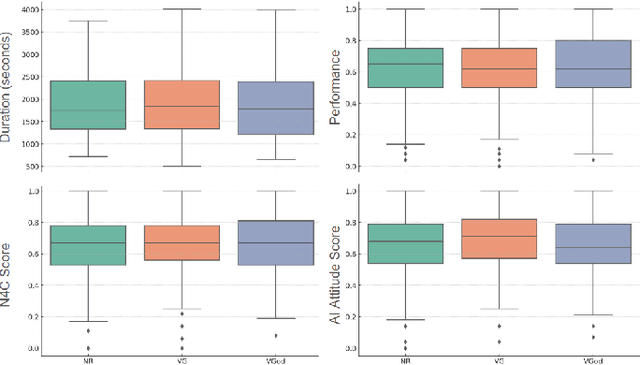
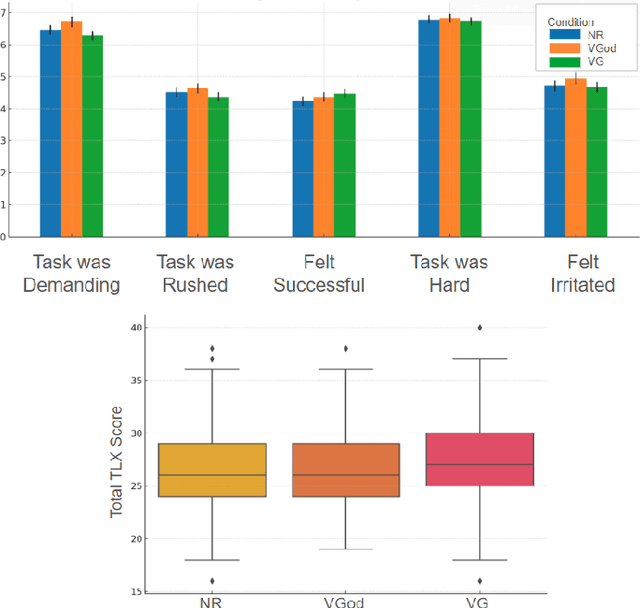
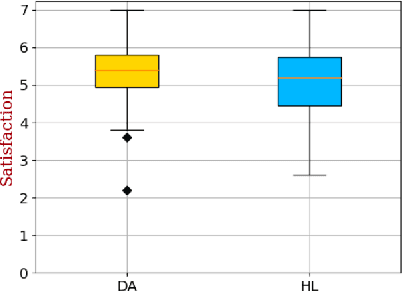
In human-agent teams, openly sharing goals is often assumed to enhance planning, collaboration, and effectiveness. However, direct communication of these goals is not always feasible, requiring teammates to infer their partner's intentions through actions. Building on this, we investigate whether an AI agent's ability to share its inferred understanding of a human teammate's goals can improve task performance and perceived collaboration. Through an experiment comparing three conditions-no recognition (NR), viable goals (VG), and viable goals on-demand (VGod) - we find that while goal-sharing information did not yield significant improvements in task performance or overall satisfaction scores, thematic analysis suggests that it supported strategic adaptations and subjective perceptions of collaboration. Cognitive load assessments revealed no additional burden across conditions, highlighting the challenge of balancing informativeness and simplicity in human-agent interactions. These findings highlight the nuanced trade-off of goal-sharing: while it fosters trust and enhances perceived collaboration, it can occasionally hinder objective performance gains.
Interactive Explanations for Reinforcement-Learning Agents
Apr 07, 2025As reinforcement learning methods increasingly amass accomplishments, the need for comprehending their solutions becomes more crucial. Most explainable reinforcement learning (XRL) methods generate a static explanation depicting their developers' intuition of what should be explained and how. In contrast, literature from the social sciences proposes that meaningful explanations are structured as a dialog between the explainer and the explainee, suggesting a more active role for the user and her communication with the agent. In this paper, we present ASQ-IT -- an interactive explanation system that presents video clips of the agent acting in its environment based on queries given by the user that describe temporal properties of behaviors of interest. Our approach is based on formal methods: queries in ASQ-IT's user interface map to a fragment of Linear Temporal Logic over finite traces (LTLf), which we developed, and our algorithm for query processing is based on automata theory. User studies show that end-users can understand and formulate queries in ASQ-IT and that using ASQ-IT assists users in identifying faulty agent behaviors.
Explaining Reinforcement Learning Agents Through Counterfactual Action Outcomes
Dec 18, 2023

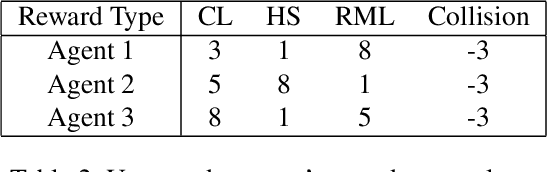
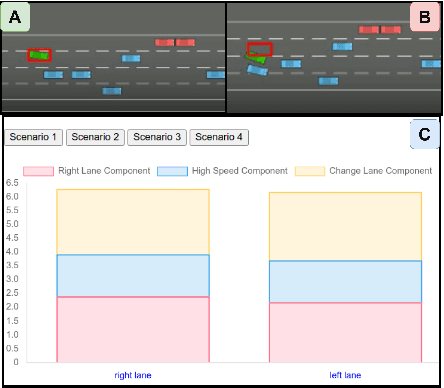
Explainable reinforcement learning (XRL) methods aim to help elucidate agent policies and decision-making processes. The majority of XRL approaches focus on local explanations, seeking to shed light on the reasons an agent acts the way it does at a specific world state. While such explanations are both useful and necessary, they typically do not portray the outcomes of the agent's selected choice of action. In this work, we propose ``COViz'', a new local explanation method that visually compares the outcome of an agent's chosen action to a counterfactual one. In contrast to most local explanations that provide state-limited observations of the agent's motivation, our method depicts alternative trajectories the agent could have taken from the given state and their outcomes. We evaluated the usefulness of COViz in supporting people's understanding of agents' preferences and compare it with reward decomposition, a local explanation method that describes an agent's expected utility for different actions by decomposing it into meaningful reward types. Furthermore, we examine the complementary benefits of integrating both methods. Our results show that such integration significantly improved participants' performance.
ASQ-IT: Interactive Explanations for Reinforcement-Learning Agents
Jan 24, 2023


As reinforcement learning methods increasingly amass accomplishments, the need for comprehending their solutions becomes more crucial. Most explainable reinforcement learning (XRL) methods generate a static explanation depicting their developers' intuition of what should be explained and how. In contrast, literature from the social sciences proposes that meaningful explanations are structured as a dialog between the explainer and the explainee, suggesting a more active role for the user and her communication with the agent. In this paper, we present ASQ-IT -- an interactive tool that presents video clips of the agent acting in its environment based on queries given by the user that describe temporal properties of behaviors of interest. Our approach is based on formal methods: queries in ASQ-IT's user interface map to a fragment of Linear Temporal Logic over finite traces (LTLf), which we developed, and our algorithm for query processing is based on automata theory. User studies show that end-users can understand and formulate queries in ASQ-IT, and that using ASQ-IT assists users in identifying faulty agent behaviors.
"I Don't Think So": Disagreement-Based Policy Summaries for Comparing Agents
Feb 05, 2021
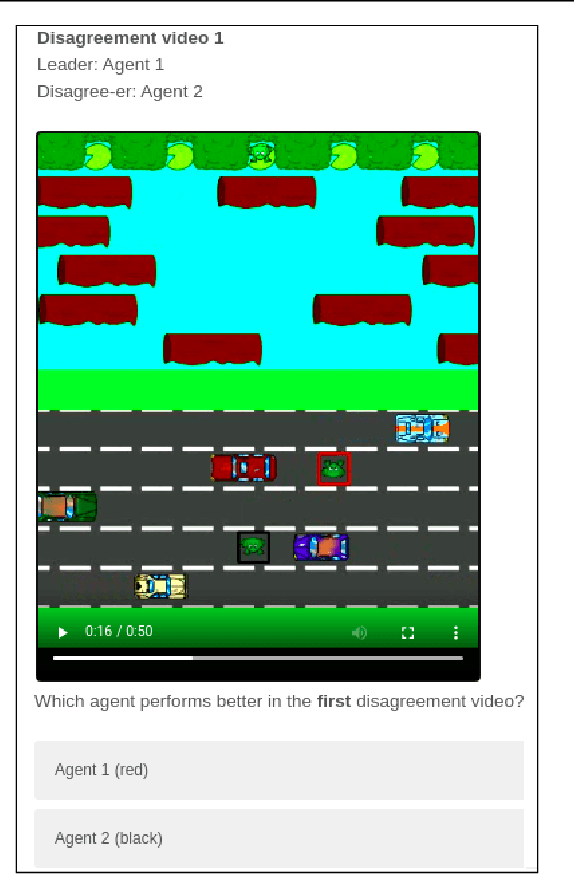
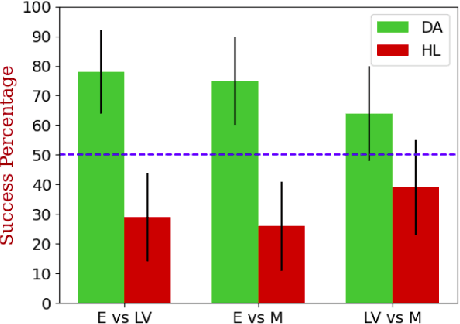
With Artificial Intelligence on the rise, human interaction with autonomous agents becomes more frequent. Effective human-agent collaboration requires that the human understands the agent's behavior, as failing to do so may lead to reduced productiveness, misuse, frustration and even danger. Agent strategy summarization methods are used to describe the strategy of an agent to its destined user through demonstration. The summary's purpose is to maximize the user's understanding of the agent's aptitude by showcasing its behaviour in a set of world states, chosen by some importance criteria. While shown to be useful, we show that these methods are limited in supporting the task of comparing agent behavior, as they independently generate a summary for each agent. In this paper, we propose a novel method for generating contrastive summaries that highlight the differences between agent's policies by identifying and ranking states in which the agents disagree on the best course of action. We conduct a user study in which participants face an agent selection task. Our results show that the novel disagreement-based summaries lead to improved user performance compared to summaries generated using HIGHLIGHTS, a previous strategy summarization algorithm.