 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndirectRequests: Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Paper and Code
Jun 12, 2024
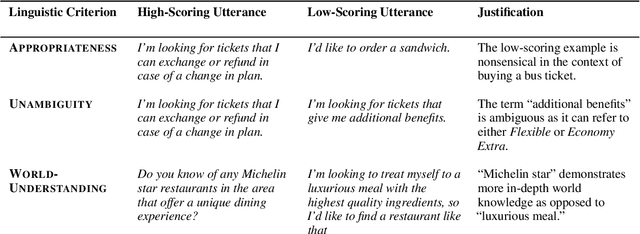
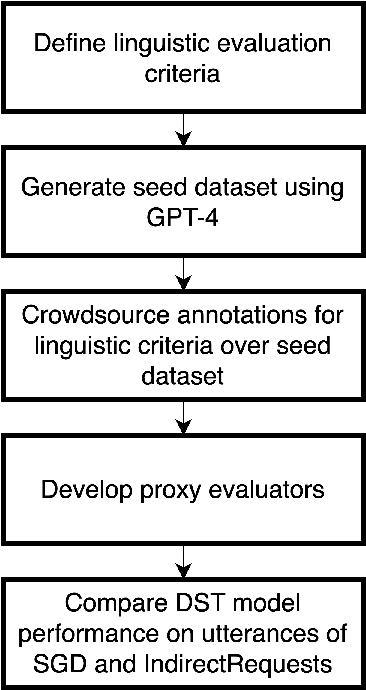

Existing benchmark corpora of task-oriented dialogue are collected either using a "machines talking to machines" approach or by giving template-based goal descriptions to crowdworkers. These methods, however, often produce utterances that are markedly different from natural human conversations in which people often convey their preferences in indirect ways, such as through small talk. We term such utterances as Indirect User Requests (IURs). Understanding such utterances demands considerable world knowledge and reasoning capabilities on the listener's part. Our study introduces an LLM-based pipeline to automatically generate realistic, high-quality IURs for a given domain, with the ultimate goal of supporting research in natural language understanding (NLU) and dialogue state tracking (DST) for task-oriented dialogue systems. Our findings show that while large LLMs such as GPT-3.5 and GPT-4 generate high-quality IURs, achieving similar quality with smaller models is more challenging. We release IndirectRequests, a dataset of IURs that advances beyond the initial Schema-Guided Dialog (SGD) dataset in that it provides a challenging testbed for testing the "in the wild" performance of NLU and DST models.