 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Black-box Robustness with In-Context Rewriting
Feb 15, 2024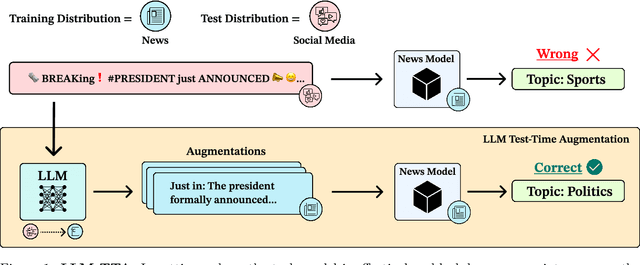
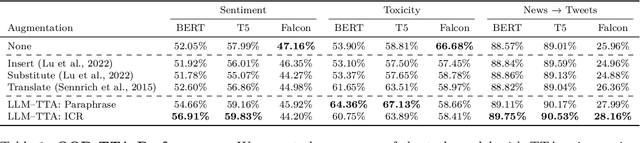
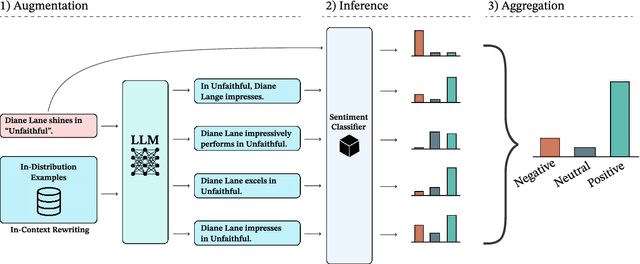
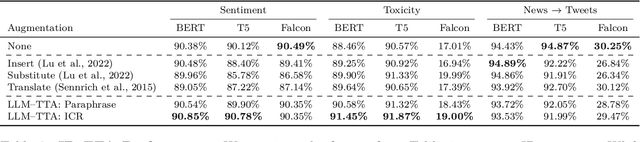
Machine learning models often excel on in-distribution (ID) data but struggle with unseen out-of-distribution (OOD) inputs. Most techniques for improving OOD robustness are not applicable to settings where the model is effectively a black box, such as when the weights are frozen, retraining is costly, or the model is leveraged via an API. Test-time augmentation (TTA) is a simple post-hoc technique for improving robustness that sidesteps black-box constraints by aggregating predictions across multiple augmentations of the test input. TTA has seen limited use in NLP due to the challenge of generating effective natural language augmentations. In this work, we propose LLM-TTA, which uses LLM-generated augmentations as TTA's augmentation function. LLM-TTA outperforms conventional augmentation functions across sentiment, toxicity, and news classification tasks for BERT and T5 models, with BERT's OOD robustness improving by an average of 4.30 percentage points without regressing average ID performance. We explore selectively augmenting inputs based on prediction entropy to reduce the rate of expensive LLM augmentations, allowing us to maintain performance gains while reducing the average number of generated augmentations by 57.76%. LLM-TTA is agnostic to the task model architecture, does not require OOD labels, and is effective across low and high-resource settings. We share our data, models, and code for reproducibility.
Gap Minimization for Knowledge Sharing and Transfer
Jan 26, 2022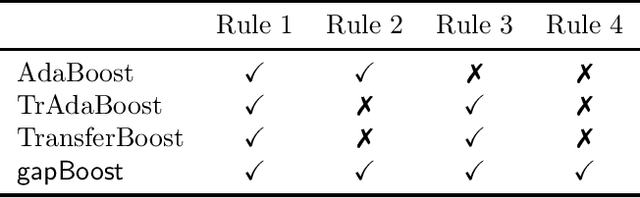
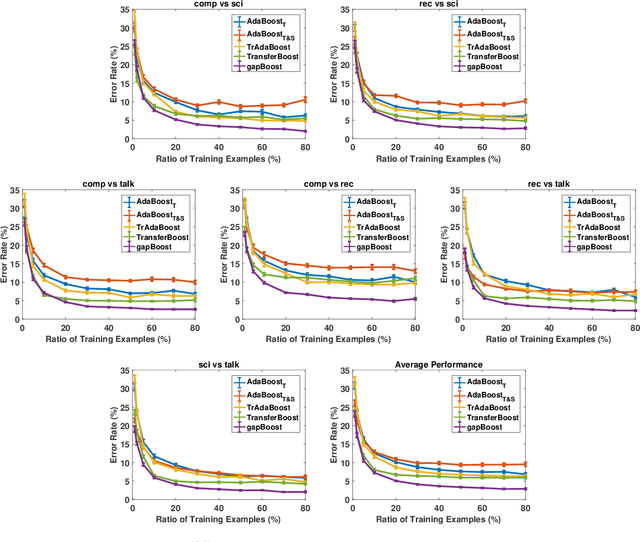
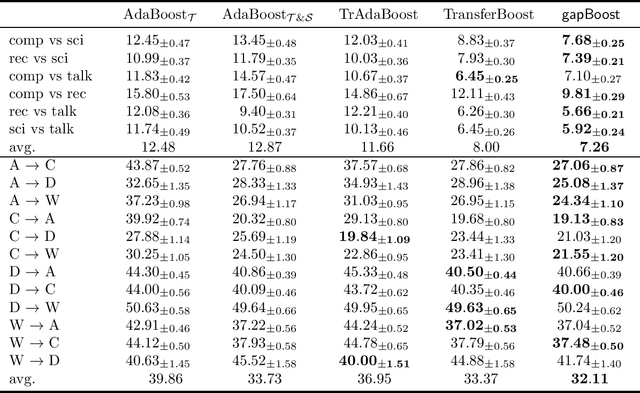
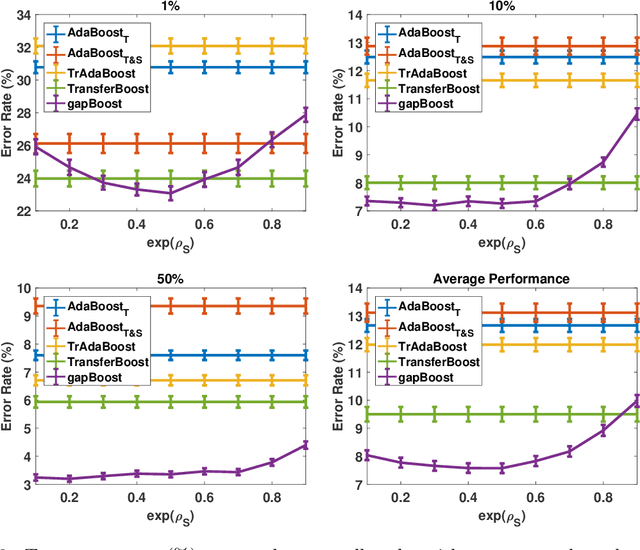
Learning from multiple related tasks by knowledge sharing and transfer has become increasingly relevant over the last two decades. In order to successfully transfer information from one task to another, it is critical to understand the similarities and differences between the domains. In this paper, we introduce the notion of \emph{performance gap}, an intuitive and novel measure of the distance between learning tasks. Unlike existing measures which are used as tools to bound the difference of expected risks between tasks (e.g., $\mathcal{H}$-divergence or discrepancy distance), we theoretically show that the performance gap can be viewed as a data- and algorithm-dependent regularizer, which controls the model complexity and leads to finer guarantees. More importantly, it also provides new insights and motivates a novel principle for designing strategies for knowledge sharing and transfer: gap minimization. We instantiate this principle with two algorithms: 1. {gapBoost}, a novel and principled boosting algorithm that explicitly minimizes the performance gap between source and target domains for transfer learning; and 2. {gapMTNN}, a representation learning algorithm that reformulates gap minimization as semantic conditional matching for multitask learning. Our extensive evaluation on both transfer learning and multitask learning benchmark data sets shows that our methods outperform existing baselines.