 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFormer: Automated Infrastructure-as-Code with LLMs Fine-Tuned via Policy-Guided Verifier Feedback
Jan 13, 2026Automating Infrastructure-as-Code (IaC) is challenging, and large language models (LLMs) often produce incorrect configurations from natural language (NL). We present TerraFormer, a neuro-symbolic framework for IaC generation and mutation that combines supervised fine-tuning with verifier-guided reinforcement learning, using formal verification tools to provide feedback on syntax, deployability, and policy compliance. We curate two large, high-quality NL-to-IaC datasets, TF-Gen (152k instances) and TF-Mutn (52k instances), via multi-stage verification and iterative LLM self-correction. Evaluations against 17 state-of-the-art LLMs, including ~50x larger models like Sonnet 3.7, DeepSeek-R1, and GPT-4.1, show that TerraFormer improves correctness over its base LLM by 15.94% on IaC-Eval, 11.65% on TF-Gen (Test), and 19.60% on TF-Mutn (Test). It outperforms larger models on both TF-Gen (Test) and TF-Mutn (Test), ranks third on IaC-Eval, and achieves top best-practices and security compliance.
User Simulation with Large Language Models for Evaluating Task-Oriented Dialogue
Sep 23, 2023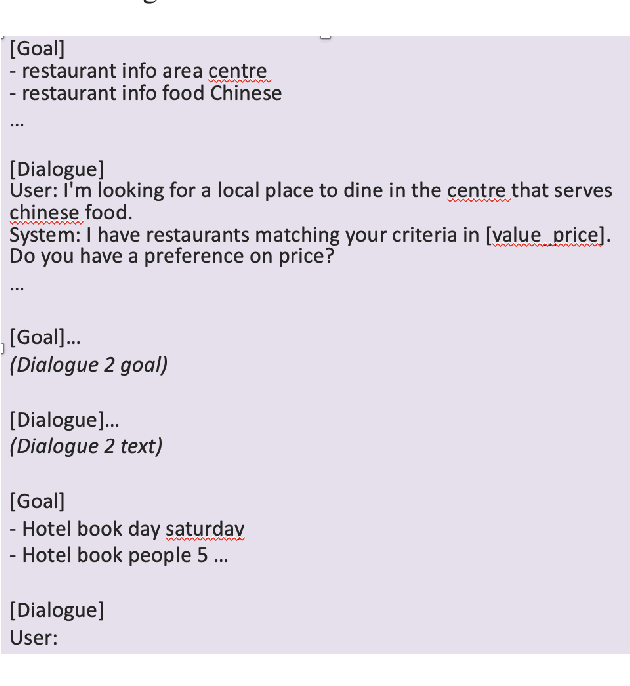
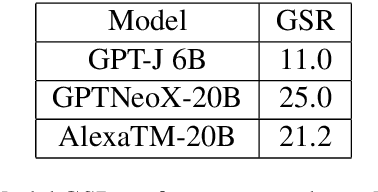
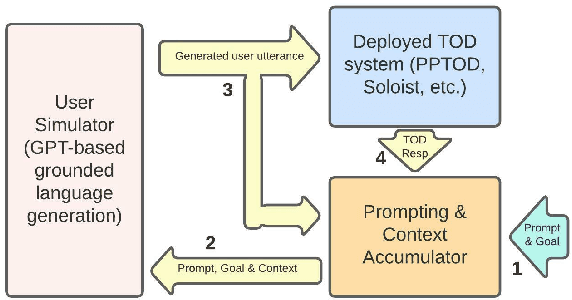
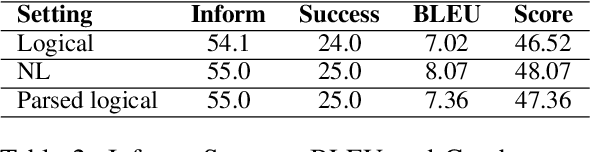
One of the major impediments to the development of new task-oriented dialogue (TOD) systems is the need for human evaluation at multiple stages and iterations of the development process. In an effort to move toward automated evaluation of TOD, we propose a novel user simulator built using recently developed large pretrained language models (LLMs). In order to increase the linguistic diversity of our system relative to the related previous work, we do not fine-tune the LLMs used by our system on existing TOD datasets; rather we use in-context learning to prompt the LLMs to generate robust and linguistically diverse output with the goal of simulating the behavior of human interlocutors. Unlike previous work, which sought to maximize goal success rate (GSR) as the primary metric of simulator performance, our goal is a system which achieves a GSR similar to that observed in human interactions with TOD systems. Using this approach, our current simulator is effectively able to interact with several TOD systems, especially on single-intent conversational goals, while generating lexically and syntactically diverse output relative to previous simulators that rely upon fine-tuned models. Finally, we collect a Human2Bot dataset of humans interacting with the same TOD systems with which we experimented in order to better quantify these achievements.
IdEALS: Idiomatic Expressions for Advancement of Language Skills
May 24, 2023
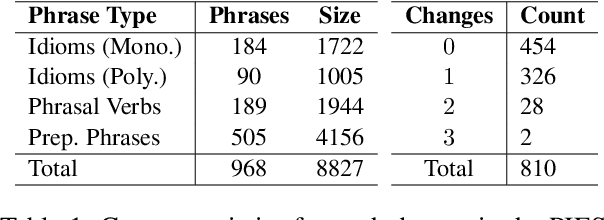
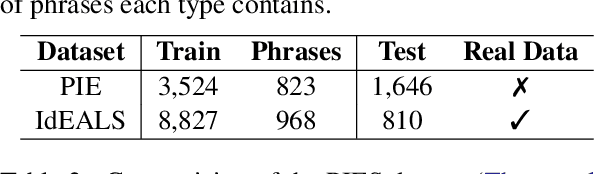

Although significant progress has been made in developing methods for Grammatical Error Correction (GEC), addressing word choice improvements has been notably lacking and enhancing sentence expressivity by replacing phrases with advanced expressions is an understudied aspect. In this paper, we focus on this area and present our investigation into the task of incorporating the usage of idiomatic expressions in student writing. To facilitate our study, we curate extensive training sets and expert-annotated testing sets using real-world data and evaluate various approaches and compare their performance against human experts.
Using Chatbots to Teach Languages
Jul 31, 2022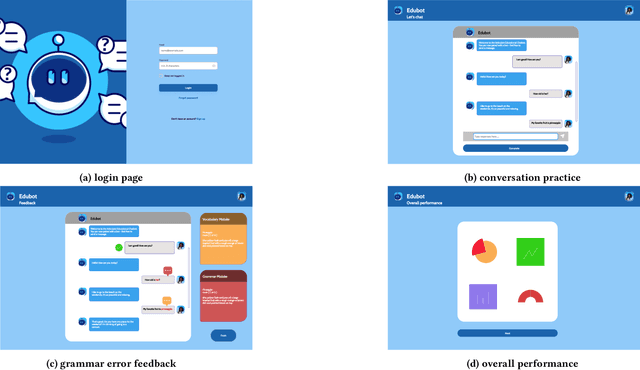

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
ErAConD : Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Dec 15, 2021


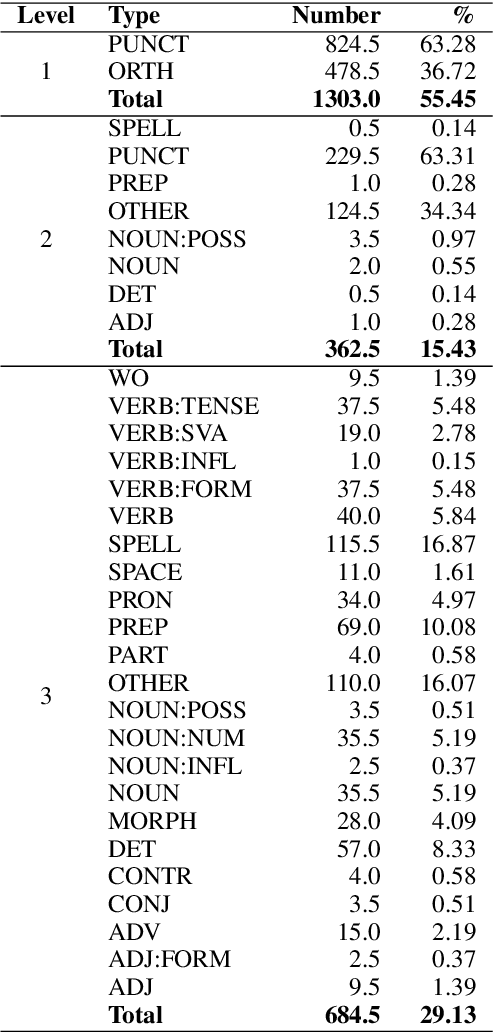
Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16 point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenario.
Gunrock 2.0: A User Adaptive Social Conversational System
Nov 30, 2020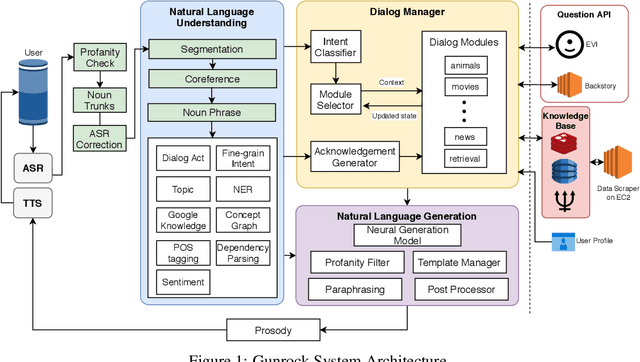
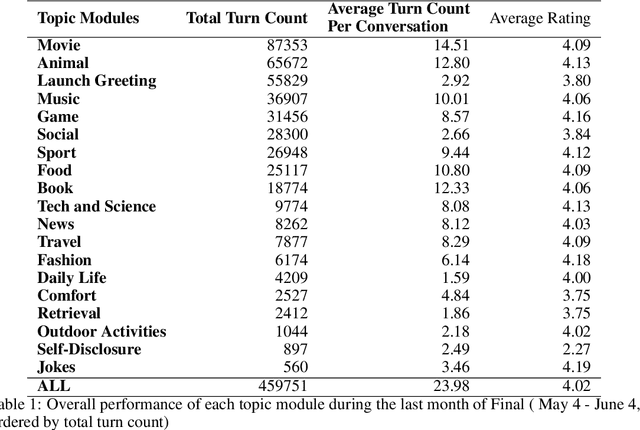
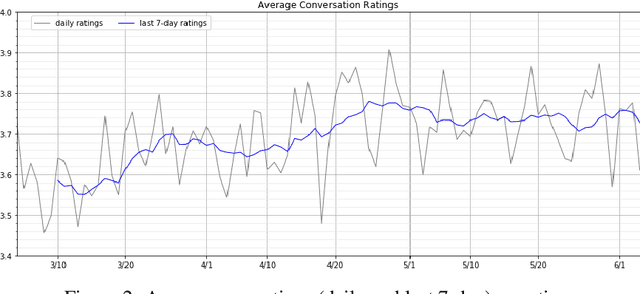
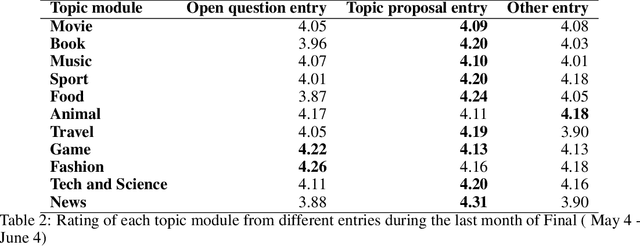
Gunrock 2.0 is built on top of Gunrock with an emphasis on user adaptation. Gunrock 2.0 combines various neural natural language understanding modules, including named entity detection, linking, and dialog act prediction, to improve user understanding. Its dialog management is a hierarchical model that handles various topics, such as movies, music, and sports. The system-level dialog manager can handle question detection, acknowledgment, error handling, and additional functions, making downstream modules much easier to design and implement. The dialog manager also adapts its topic selection to accommodate different users' profile information, such as inferred gender and personality. The generation model is a mix of templates and neural generation models. Gunrock 2.0 is able to achieve an average rating of 3.73 at its latest build from May 29th to June 4th.
Gunrock: A Social Bot for Complex and Engaging Long Conversations
Oct 07, 2019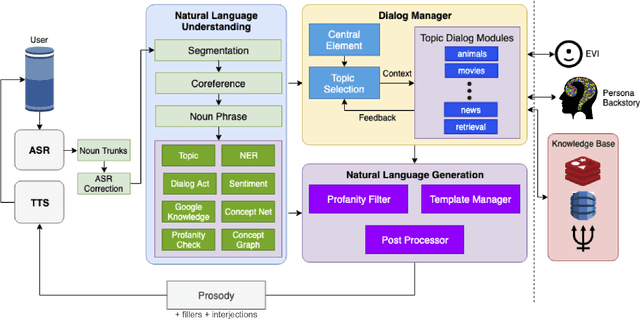
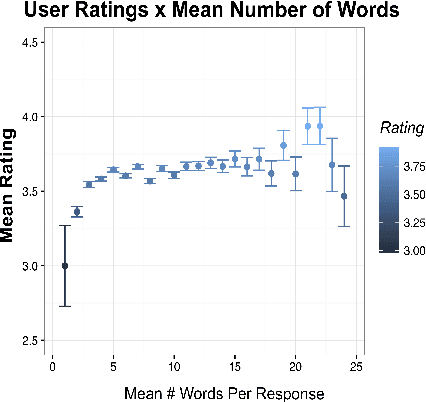
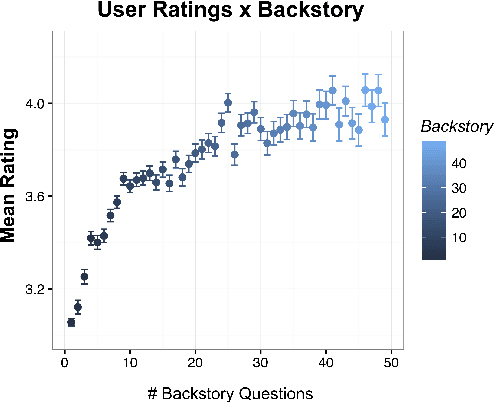
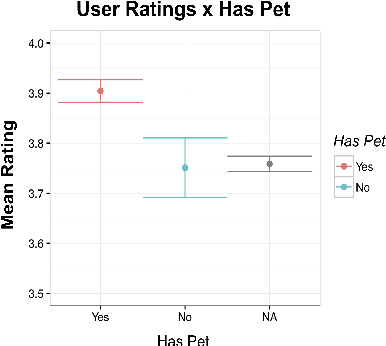
Gunrock is the winner of the 2018 Amazon Alexa Prize, as evaluated by coherence and engagement from both real users and Amazon-selected expert conversationalists. We focus on understanding complex sentences and having in-depth conversations in open domains. In this paper, we introduce some innovative system designs and related validation analysis. Overall, we found that users produce longer sentences to Gunrock, which are directly related to users' engagement (e.g., ratings, number of turns). Additionally, users' backstory queries about Gunrock are positively correlated to user satisfaction. Finally, we found dialog flows that interleave facts and personal opinions and stories lead to better user satisfaction.
Dependency Parsing for Spoken Dialog Systems
Sep 07, 2019
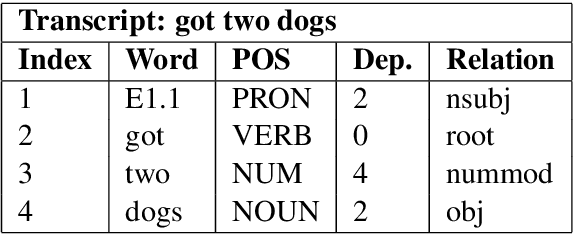
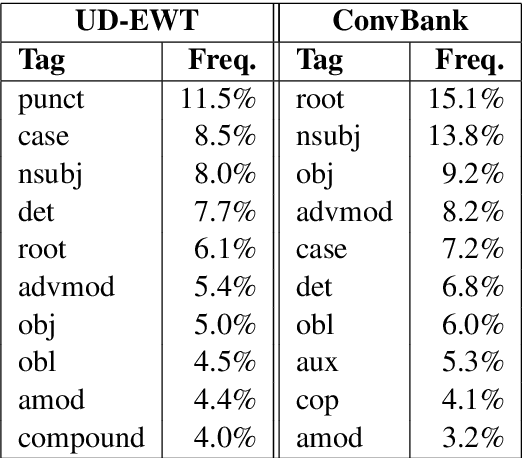
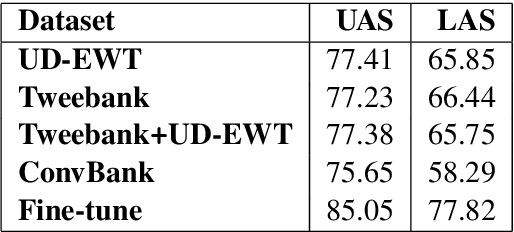
Dependency parsing of conversational input can play an important role in language understanding for dialog systems by identifying the relationships between entities extracted from user utterances. Additionally, effective dependency parsing can elucidate differences in language structure and usage for discourse analysis of human-human versus human-machine dialogs. However, models trained on datasets based on news articles and web data do not perform well on spoken human-machine dialog, and currently available annotation schemes do not adapt well to dialog data. Therefore, we propose the Spoken Conversation Universal Dependencies (SCUD) annotation scheme that extends the Universal Dependencies (UD) (Nivre et al., 2016) guidelines to spoken human-machine dialogs. We also provide ConvBank, a conversation dataset between humans and an open-domain conversational dialog system with SCUD annotation. Finally, to demonstrate the utility of the dataset, we train a dependency parser on the ConvBank dataset. We demonstrate that by pre-training a dependency parser on a set of larger public datasets and fine-tuning on ConvBank data, we achieved the best result, 85.05% unlabeled and 77.82% labeled attachment accuracy.