 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Chatbots to Teach Languages
Jul 31, 2022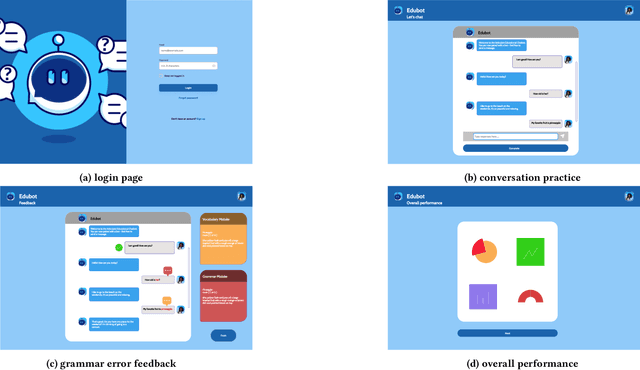

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
Gunrock: A Social Bot for Complex and Engaging Long Conversations
Oct 07, 2019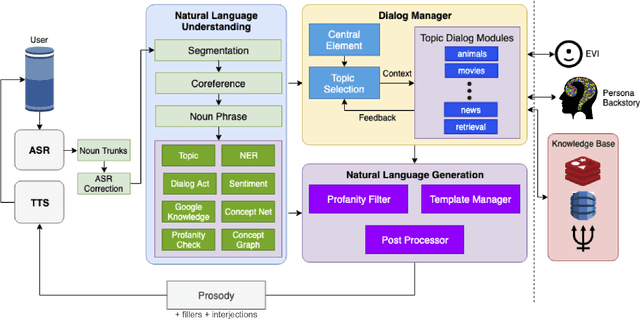
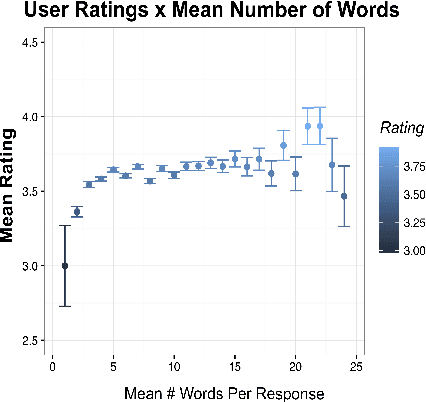
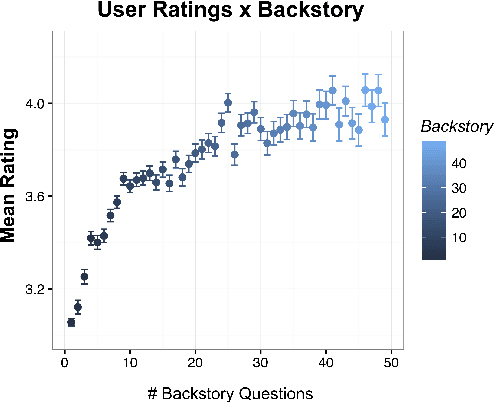
Gunrock is the winner of the 2018 Amazon Alexa Prize, as evaluated by coherence and engagement from both real users and Amazon-selected expert conversationalists. We focus on understanding complex sentences and having in-depth conversations in open domains. In this paper, we introduce some innovative system designs and related validation analysis. Overall, we found that users produce longer sentences to Gunrock, which are directly related to users' engagement (e.g., ratings, number of turns). Additionally, users' backstory queries about Gunrock are positively correlated to user satisfaction. Finally, we found dialog flows that interleave facts and personal opinions and stories lead to better user satisfaction.
Distributed Training Large-Scale Deep Architectures
Aug 10, 2017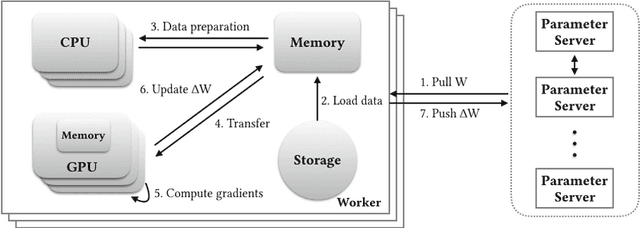
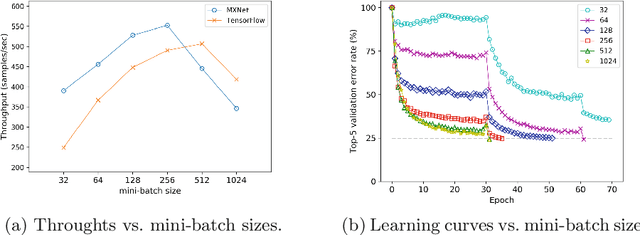
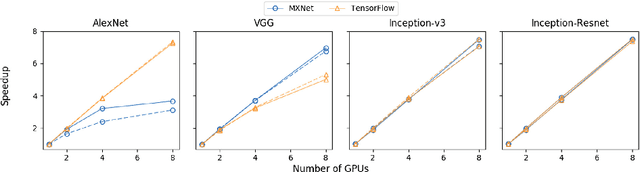
Scale of data and scale of computation infrastructures together enable the current deep learning renaissance. However, training large-scale deep architectures demands both algorithmic improvement and careful system configuration. In this paper, we focus on employing the system approach to speed up large-scale training. Via lessons learned from our routine benchmarking effort, we first identify bottlenecks and overheads that hinter data parallelism. We then devise guidelines that help practitioners to configure an effective system and fine-tune parameters to achieve desired speedup. Specifically, we develop a procedure for setting minibatch size and choosing computation algorithms. We also derive lemmas for determining the quantity of key components such as the number of GPUs and parameter servers. Experiments and examples show that these guidelines help effectively speed up large-scale deep learning training.