 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Collatz Dynamics with Human-LLM Collaboration
Mar 10, 2026We investigate structural properties of the Collatz iteration through two phenomena observed in large computational exploration: modular scrambling of residue classes and a burst--gap decomposition of trajectories. We prove several structural results, including a modular scrambling lemma showing that the gap-return map acts as an exact bijection on high bits, a persistent exit lemma characterizing gap structure after persistent states, and a decay property for known portions of binary representations under gap-return dynamics. We further prove that, in the modular model, gap lengths and $2$-adic valuations follow geometric distributions, while persistent run lengths are geometric with expected burst length $E[B]=2$; together these predict strict orbit contraction. These results suggest a conditional framework in which convergence would follow from suitable orbitwise hypotheses on burst and gap lengths, which in turn are suggested by an orbit equidistribution conjecture. However, the key hypotheses remain open, and the framework is exploratory rather than a complete reduction. The paper also documents the human-LLM collaboration through which these observations were developed.
Right for the Wrong Reasons: Epistemic Regret Minimization for Causal Rung Collapse in LLMs
Feb 12, 2026Machine learning systems that are "right for the wrong reasons" achieve high performance through shortcuts that collapse under distributional shift. We show this pathology has a precise causal origin: autoregressive training provides no gradient signal to distinguish association P(Y|X) from intervention P(Y|do(X)), a failure we formalize as Rung Collapse. When outcome-based learning reinforces correct answers obtained through incorrect causal models, the agent becomes entrenched in flawed reasoning, a phenomenon we term Aleatoric Entrenchment. We propose Epistemic Regret Minimization (ERM), a belief revision objective that penalizes errors in causal reasoning independently of task success, and embed it within a three-layer architecture with three contributions grounded in knowledge representation: (1) a Physical Grounding Theorem proving that actions satisfying actuator independence implement valid do-operations, bridging action languages and do-calculus; (2) ERM as a causal belief revision operator satisfying AGM postulates, preventing entrenchment even when the agent succeeds for the wrong reasons; and (3) a failure mode taxonomy that classifies recurring reasoning errors and injects domain-independent guards, enabling cross-domain transfer. We prove asymptotic recovery of the true interventional distribution with finite-sample bounds. Experiments on 1,360 causal trap scenarios across six frontier LLMs reveal that Rung Collapse persists even in reasoning-enhanced models (3.7% for GPT-5.2), that steerability exhibits inverse scaling where advanced models resist generic correction, and that targeted ERM feedback recovers 53-59% of entrenched errors where outcome-level feedback fails.
CausalT5K: Diagnosing and Informing Refusal for Trustworthy Causal Reasoning of Skepticism, Sycophancy, Detection-Correction, and Rung Collapse
Feb 09, 2026LLM failures in causal reasoning, including sycophancy, rung collapse, and miscalibrated refusal, are well-documented, yet progress on remediation is slow because no benchmark enables systematic diagnosis. We introduce CausalT5K, a diagnostic benchmark of over 5,000 cases across 10 domains that tests three critical capabilities: (1) detecting rung collapse, where models answer interventional queries with associational evidence; (2) resisting sycophantic drift under adversarial pressure; and (3) generating Wise Refusals that specify missing information when evidence is underdetermined. Unlike synthetic benchmarks, CausalT5K embeds causal traps in realistic narratives and decomposes performance into Utility (sensitivity) and Safety (specificity), revealing failure modes invisible to aggregate accuracy. Developed through a rigorous human-machine collaborative pipeline involving 40 domain experts, iterative cross-validation cycles, and composite verification via rule-based, LLM, and human scoring, CausalT5K implements Pearl's Ladder of Causation as research infrastructure. Preliminary experiments reveal a Four-Quadrant Control Landscape where static audit policies universally fail, a finding that demonstrates CausalT5K's value for advancing trustworthy reasoning systems. Repository: https://github.com/genglongling/CausalT5kBench
RAudit: A Blind Auditing Protocol for Large Language Model Reasoning
Jan 30, 2026Inference-time scaling can amplify reasoning pathologies: sycophancy, rung collapse, and premature certainty. We present RAudit, a diagnostic protocol for auditing LLM reasoning without ground truth access. The key constraint is blindness: the auditor evaluates only whether derivation steps support conclusions, enabling detection of trace-output inconsistency and, when latent competence exists, its recovery. RAudit measures process quality via CRIT-based reasonableness scores and varies critique formulation to study how social framing affects model response. We prove bounded correction and $O(\log(1/ε))$ termination. Experiments on mathematical reasoning (CAP-GSM8K) and causal judgment (CausalL2) reveal four mechanisms explaining model unreliability: (1) Latent Competence Suppression, where models derive correct answers then overwrite them under social pressure; (2) The False Competence Trap, where weaker judges mask sycophancy that stronger judges expose; (3) The Complexity-Vulnerability Tradeoff, where causal tasks induce more than 10 times higher sycophancy than mathematical tasks; and (4) Iatrogenic Critique, where authoritative correction harms weaker models. These findings challenge assumptions that capability implies robustness and that stronger feedback yields better outputs.
T3: Benchmarking Sycophancy and Skepticism in Causal Judgment
Jan 13, 2026We introduce T3 (Testing Trustworthy Thinking), a diagnostic benchmark designed to rigorously evaluate LLM causal judgment across Pearl's Ladder of Causality. Comprising 454 expert-curated vignettes, T3 prioritizes high-resolution failure analysis, decomposing performance into Utility (sensitivity), Safety (specificity), and Wise Refusal on underdetermined cases. By applying T3 to frontier models, we diagnose two distinct pathologies: a "Skepticism Trap" at L1 (where safety-tuned models like Claude Haiku reject 60% of valid links) and a non-monotonic Scaling Paradox at L3. In the latter, the larger GPT-5.2 underperforms GPT-4-Turbo by 55 points on ambiguous counterfactuals, driven by a collapse into paralysis (excessive hedging) rather than hallucination. Finally, we use the benchmark to validate a process-verified protocol (RCA), showing that T3 successfully captures the restoration of decisive causal judgment under structured verification.
Multi-Agent Collaborative Intelligence: Dual-Dial Control for Reliable LLM Reasoning
Oct 06, 2025Multi-agent debate often wastes compute by using a fixed adversarial stance, aggregating without deliberation, or stopping on heuristics. We introduce MACI, an active controller with two independent dials that decouple information from behavior: an information dial that gates evidence by quality, and a behavior dial that schedules contentiousness from exploration to consolidation. A moderator tracks disagreement, overlap, evidence quality, and argument quality, and halts when gains plateau. We provide theory-lite guarantees for nonincreasing dispersion and provable termination, with a budget-feasible scheduler. Across clinical diagnosis and news-bias tasks, MACI improves accuracy and calibration while reducing tokens, and converts residual uncertainty into precision RAG plans that specify what to retrieve next. We use a cross-family LLM judge (CRIT) as a conservative soft weight and stop signal, validated for order invariance and judge-swap stability; stability depends on using high-capability judges. MACI turns debate into a budget-aware, measurable, and provably terminating controller.
ALAS: A Stateful Multi-LLM Agent Framework for Disruption-Aware Planning
May 18, 2025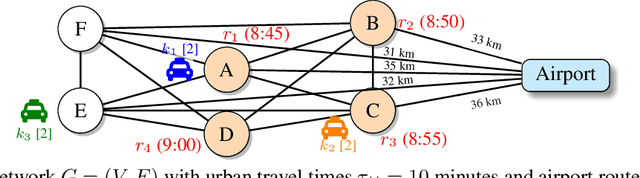


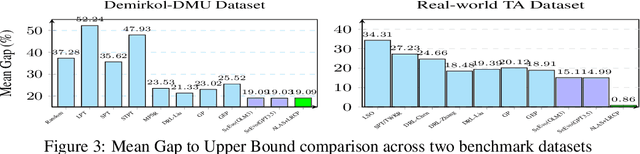
Large language models (LLMs) excel at rapid generation of text and multimodal content, yet they falter on transaction-style planning that demands ACID-like guarantees and real-time disruption recovery. We present Adaptive LLM Agent System (ALAS), a framework that tackles four fundamental LLM deficits: (i) absence of self-verification, (ii) context erosion, (iii) next-token myopia, and (iv) lack of persistent state. ALAS decomposes each plan into role-specialized agents, equips them with automatic state tracking, and coordinates them through a lightweight protocol. When disruptions arise, agents apply history-aware local compensation, avoiding costly global replanning and containing cascade effects. On real-world, large-scale job-shop scheduling benchmarks, ALAS sets new best results for static sequential planning and excels in dynamic reactive scenarios with unexpected disruptions. These gains show that principled modularization plus targeted compensation can unlock scalable and resilient planning with LLMs.
SagaLLM: Context Management, Validation, and Transaction Guarantees for Multi-Agent LLM Planning
Mar 15, 2025



Recent LLM-based agent frameworks have demonstrated impressive capabilities in task delegation and workflow orchestration, but face significant challenges in maintaining context awareness and ensuring planning consistency. This paper presents SagaLLM, a structured multi-agent framework that addresses four fundamental limitations in current LLM approaches: inadequate self-validation, context narrowing, lacking transaction properties, and insufficient inter-agent coordination. By implementing specialized context management agents and validation protocols, SagaLLM preserves critical constraints and state information throughout complex planning processes, enabling robust and consistent decision-making even during disruptions. We evaluate our approach using selected problems from the REALM benchmark, focusing on sequential and reactive planning scenarios that challenge both context retention and adaptive reasoning. Our experiments with state-of-the-art LLMs, Claude 3.7, DeepSeek R1, GPT-4o, and GPT-o1, demonstrate that while these models exhibit impressive reasoning capabilities, they struggle with maintaining global constraint awareness during complex planning tasks, particularly when adapting to unexpected changes. In contrast, the distributed cognitive architecture of SagaLLM shows significant improvements in planning consistency, constraint enforcement, and adaptation to disruptions in various scenarios.
REALM-Bench: A Real-World Planning Benchmark for LLMs and Multi-Agent Systems
Feb 26, 2025This benchmark suite provides a comprehensive evaluation framework for assessing both individual LLMs and multi-agent systems in real-world planning scenarios. The suite encompasses eleven designed problems that progress from basic to highly complex, incorporating key aspects such as multi-agent coordination, inter-agent dependencies, and dynamic environmental disruptions. Each problem can be scaled along three dimensions: the number of parallel planning threads, the complexity of inter-dependencies, and the frequency of unexpected disruptions requiring real-time adaptation. The benchmark includes detailed specifications, evaluation metrics, and baseline implementations using contemporary frameworks like LangGraph, enabling rigorous testing of both single-agent and multi-agent planning capabilities. Through standardized evaluation criteria and scalable complexity, this benchmark aims to drive progress in developing more robust and adaptable AI planning systems for real-world applications.
MACI: Multi-Agent Collaborative Intelligence for Adaptive Reasoning and Temporal Planning
Jan 29, 2025Artificial intelligence requires deliberate reasoning, temporal awareness, and effective constraint management, capabilities traditional LLMs often lack due to their reliance on pattern matching, limited self-verification, and inconsistent constraint handling. We introduce Multi-Agent Collaborative Intelligence (MACI), a framework comprising three key components: 1) a meta-planner (MP) that identifies, formulates, and refines all roles and constraints of a task (e.g., wedding planning) while generating a dependency graph, with common-sense augmentation to ensure realistic and practical constraints; 2) a collection of agents to facilitate planning and address task-specific requirements; and 3) a run-time monitor that manages plan adjustments as needed. By decoupling planning from validation, maintaining minimal agent context, and integrating common-sense reasoning, MACI overcomes the aforementioned limitations and demonstrates robust performance in two scheduling problems.
* 21 pages, 19 tables