 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIFT: A RubrIc Failure Mode Taxonomy and Automated Diagnostics
Apr 01, 2026Rubric-based evaluation is widely used in LLM benchmarks and training pipelines for open-ended, less verifiable tasks. While prior work has demonstrated the effectiveness of rubrics using downstream signals such as reinforcement learning outcomes, there remains no principled way to diagnose rubric quality issues from such aggregated or downstream signals alone. To address this gap, we introduce RIFT: RubrIc Failure mode Taxonomy, a taxonomy for systematically characterizing failure modes in rubric composition and design. RIFT consists of eight failure modes organized into three high-level categories: Reliability Failures, Content Validity Failures, and Consequential Validity Failures. RIFT is developed using grounded theory by iteratively annotating rubrics drawn from five diverse benchmarks spanning general instruction following, code generation, creative writing, and expert-level deep research, until no new failure modes are identified. We evaluate the consistency of the taxonomy by measuring agreement among independent human annotators, observing fair agreement overall (87% pairwise agreement and 0.64 average Cohen's kappa). Finally, to support scalable diagnosis, we propose automated rubric quality metrics and show that they align with human failure-mode annotations, achieving up to 0.86 F1.
Using Chatbots to Teach Languages
Jul 31, 2022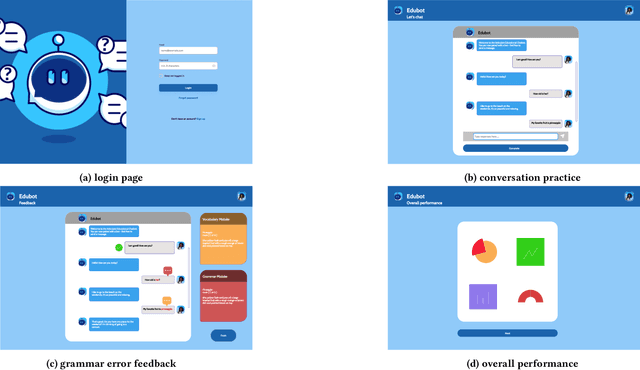

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
ErAConD : Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Dec 15, 2021


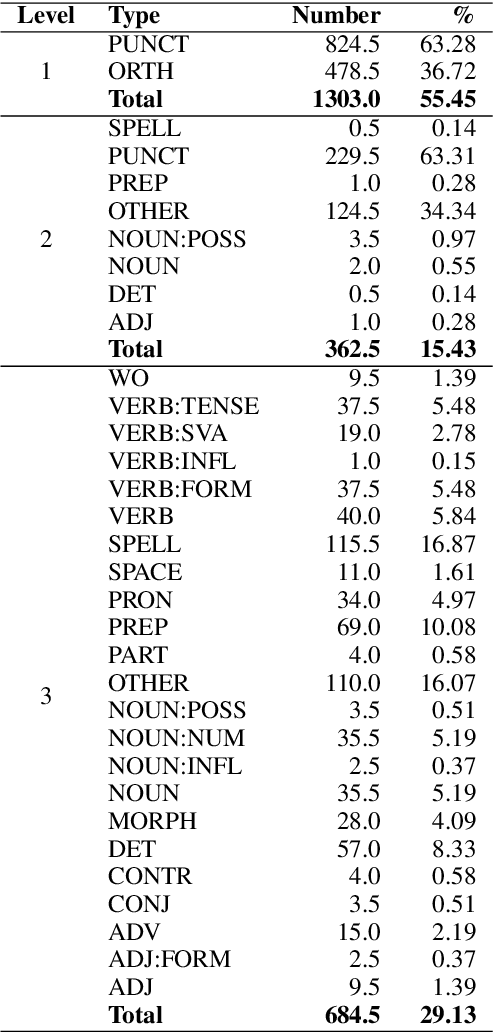
Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16 point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenario.