 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models and Simple, Stupid Bugs
Mar 20, 2023With the advent of powerful neural language models, AI-based systems to assist developers in coding tasks are becoming widely available; Copilot is one such system. Copilot uses Codex, a large language model (LLM), to complete code conditioned on a preceding "prompt". Codex, however, is trained on public GitHub repositories, viz., on code that may include bugs and vulnerabilities. Previous studies [1], [2] show Codex reproduces vulnerabilities seen in training. In this study, we examine how prone Codex is to generate an interesting bug category, single statement bugs, commonly referred to as simple, stupid bugs or SStuBs in the MSR community. We find that Codex and similar LLMs do help avoid some SStuBs, but do produce known, verbatim SStuBs as much as 2x as likely than known, verbatim correct code. We explore the consequences of the Codex generated SStuBs and propose avoidance strategies that suggest the possibility of reducing the production of known, verbatim SStubs, and increase the possibility of producing known, verbatim fixes.
Gunrock: A Social Bot for Complex and Engaging Long Conversations
Oct 07, 2019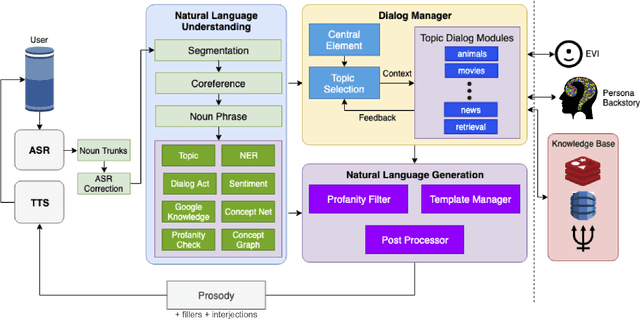
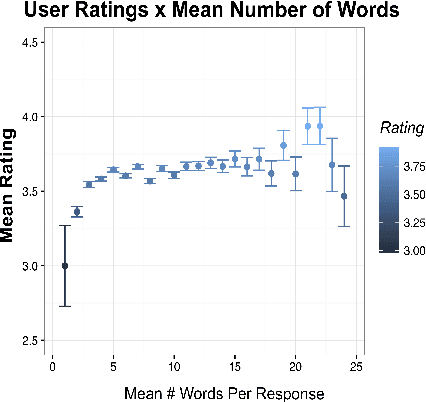
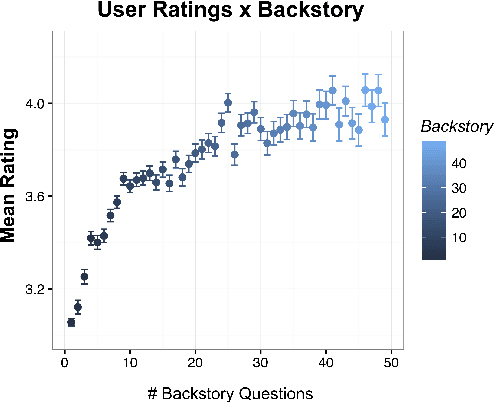
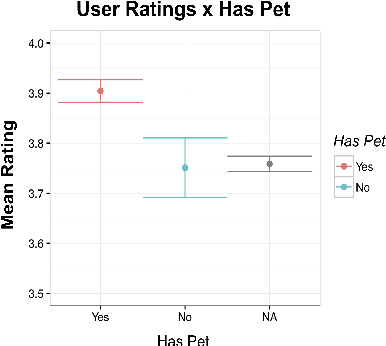
Gunrock is the winner of the 2018 Amazon Alexa Prize, as evaluated by coherence and engagement from both real users and Amazon-selected expert conversationalists. We focus on understanding complex sentences and having in-depth conversations in open domains. In this paper, we introduce some innovative system designs and related validation analysis. Overall, we found that users produce longer sentences to Gunrock, which are directly related to users' engagement (e.g., ratings, number of turns). Additionally, users' backstory queries about Gunrock are positively correlated to user satisfaction. Finally, we found dialog flows that interleave facts and personal opinions and stories lead to better user satisfaction.