Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Contract Element Extraction Revisited
Paper and Code
Jan 12, 2021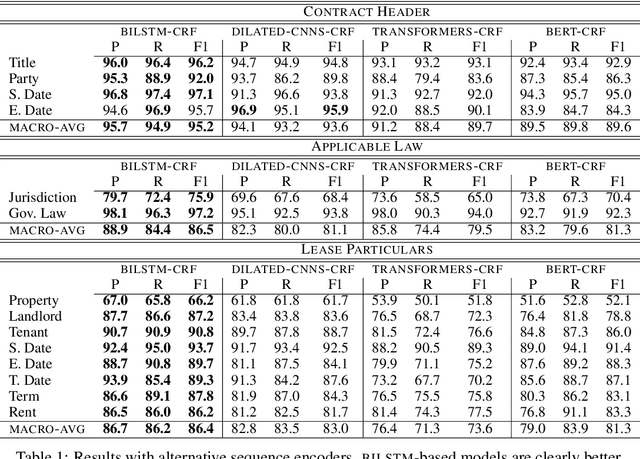

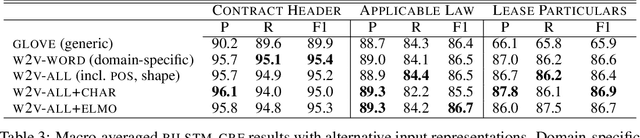
We investigate contract element extraction. We show that LSTM-based encoders perform better than dilated CNNs, Transformers, and BERT in this task. We also find that domain-specific WORD2VEC embeddings outperform generic pre-trained GLOVE embeddings. Morpho-syntactic features in the form of POS tag and token shape embeddings, as well as context-aware ELMO embeddings, do not improve performance. Several of these observations contradict choices or findings of previous work on contract element extraction and generic sequence labeling tasks, indicating that contract element extraction requires careful task-specific choices.
* short paper at Document Intelligence Workshop (NeurIPS 2019
Workshop) * 4 pages
View paper on
 OpenReview
OpenReview