 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-NLP-TOOLKIT: An Open-Source NLP Toolkit for Modern Greek
Dec 11, 2024

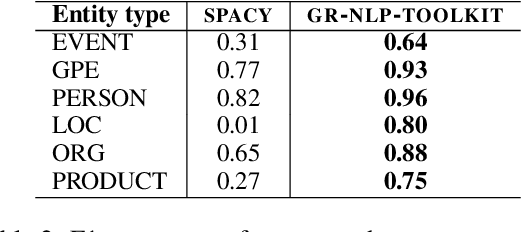
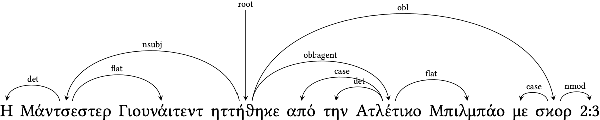
We present GR-NLP-TOOLKIT, an open-source natural language processing (NLP) toolkit developed specifically for modern Greek. The toolkit provides state-of-the-art performance in five core NLP tasks, namely part-of-speech tagging, morphological tagging, dependency parsing, named entity recognition, and Greeklishto-Greek transliteration. The toolkit is based on pre-trained Transformers, it is freely available, and can be easily installed in Python (pip install gr-nlp-toolkit). It is also accessible through a demonstration platform on HuggingFace, along with a publicly available API for non-commercial use. We discuss the functionality provided for each task, the underlying methods, experiments against comparable open-source toolkits, and future possible enhancements. The toolkit is available at: https://github.com/nlpaueb/gr-nlp-toolkit
Making LLMs Worth Every Penny: Resource-Limited Text Classification in Banking
Nov 10, 2023
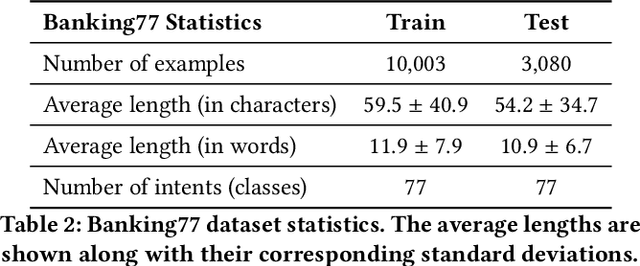

Standard Full-Data classifiers in NLP demand thousands of labeled examples, which is impractical in data-limited domains. Few-shot methods offer an alternative, utilizing contrastive learning techniques that can be effective with as little as 20 examples per class. Similarly, Large Language Models (LLMs) like GPT-4 can perform effectively with just 1-5 examples per class. However, the performance-cost trade-offs of these methods remain underexplored, a critical concern for budget-limited organizations. Our work addresses this gap by studying the aforementioned approaches over the Banking77 financial intent detection dataset, including the evaluation of cutting-edge LLMs by OpenAI, Cohere, and Anthropic in a comprehensive set of few-shot scenarios. We complete the picture with two additional methods: first, a cost-effective querying method for LLMs based on retrieval-augmented generation (RAG), able to reduce operational costs multiple times compared to classic few-shot approaches, and second, a data augmentation method using GPT-4, able to improve performance in data-limited scenarios. Finally, to inspire future research, we provide a human expert's curated subset of Banking77, along with extensive error analysis.
Cache me if you Can: an Online Cost-aware Teacher-Student framework to Reduce the Calls to Large Language Models
Oct 20, 2023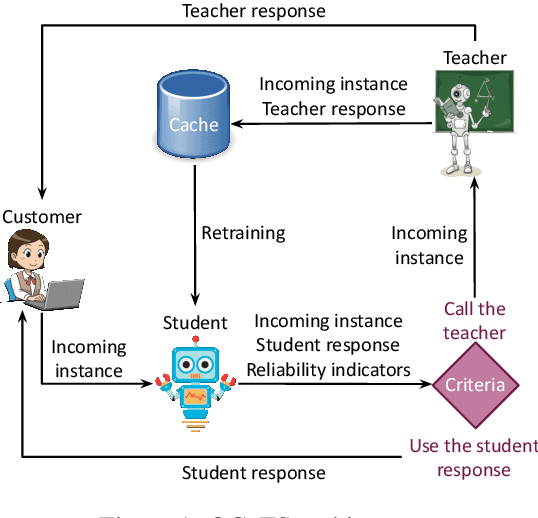
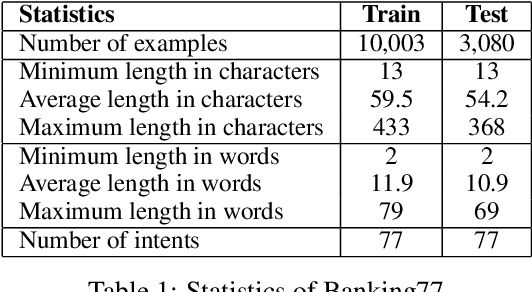
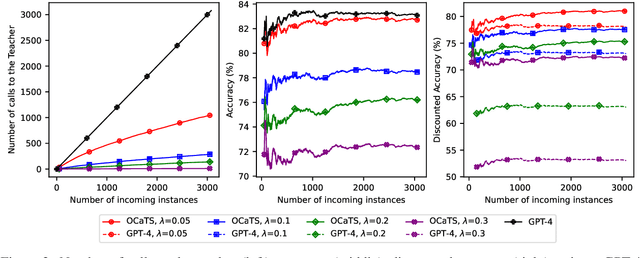
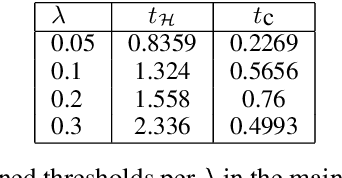
Prompting Large Language Models (LLMs) performs impressively in zero- and few-shot settings. Hence, small and medium-sized enterprises (SMEs) that cannot afford the cost of creating large task-specific training datasets, but also the cost of pretraining their own LLMs, are increasingly turning to third-party services that allow them to prompt LLMs. However, such services currently require a payment per call, which becomes a significant operating expense (OpEx). Furthermore, customer inputs are often very similar over time, hence SMEs end-up prompting LLMs with very similar instances. We propose a framework that allows reducing the calls to LLMs by caching previous LLM responses and using them to train a local inexpensive model on the SME side. The framework includes criteria for deciding when to trust the local model or call the LLM, and a methodology to tune the criteria and measure the tradeoff between performance and cost. For experimental purposes, we instantiate our framework with two LLMs, GPT-3.5 or GPT-4, and two inexpensive students, a k-NN classifier or a Multi-Layer Perceptron, using two common business tasks, intent recognition and sentiment analysis. Experimental results indicate that significant OpEx savings can be obtained with only slightly lower performance.
Breaking the Bank with ChatGPT: Few-Shot Text Classification for Finance
Aug 28, 2023
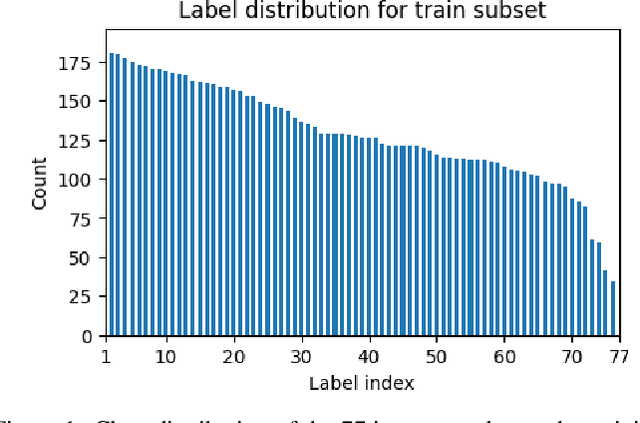
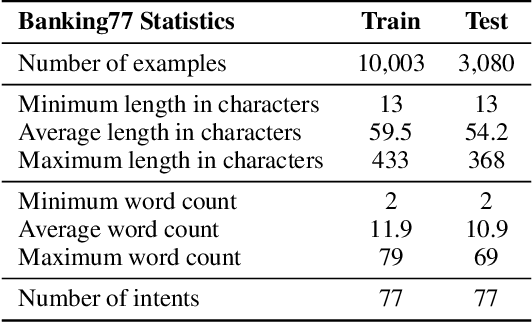

We propose the use of conversational GPT models for easy and quick few-shot text classification in the financial domain using the Banking77 dataset. Our approach involves in-context learning with GPT-3.5 and GPT-4, which minimizes the technical expertise required and eliminates the need for expensive GPU computing while yielding quick and accurate results. Additionally, we fine-tune other pre-trained, masked language models with SetFit, a recent contrastive learning technique, to achieve state-of-the-art results both in full-data and few-shot settings. Our findings show that querying GPT-3.5 and GPT-4 can outperform fine-tuned, non-generative models even with fewer examples. However, subscription fees associated with these solutions may be considered costly for small organizations. Lastly, we find that generative models perform better on the given task when shown representative samples selected by a human expert rather than when shown random ones. We conclude that a) our proposed methods offer a practical solution for few-shot tasks in datasets with limited label availability, and b) our state-of-the-art results can inspire future work in the area.
Path planning with Inventory-driven Jump-Point-Search
Jul 04, 2016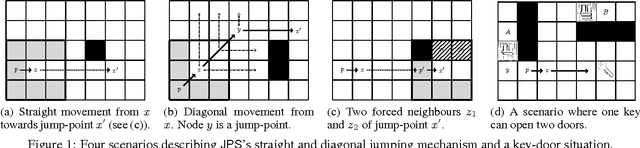
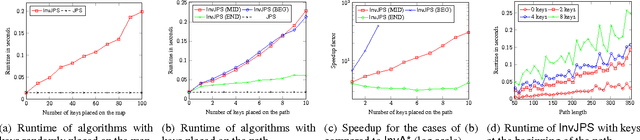
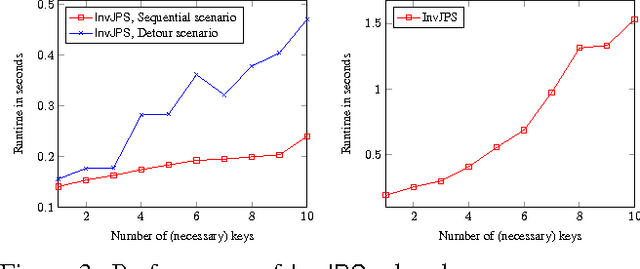
In many navigational domains the traversability of cells is conditioned on the path taken. This is often the case in video-games, in which a character may need to acquire a certain object (i.e., a key or a flying suit) to be able to traverse specific locations (e.g., doors or high walls). In order for non-player characters to handle such scenarios we present invJPS, an "inventory-driven" pathfinding approach based on the highly successful grid-based Jump-Point-Search (JPS) algorithm. We show, formally and experimentally, that the invJPS preserves JPS's optimality guarantees and its symmetry breaking advantages in inventory-based variants of game maps.
Action-based Character AI in Video-games with CogBots Architecture: A Preliminary Report
Jul 11, 2013In this paper we propose an architecture for specifying the interaction of non-player characters (NPCs) in the game-world in a way that abstracts common tasks in four main conceptual components, namely perception, deliberation, control, action. We argue that this architecture, inspired by AI research on autonomous agents and robots, can offer a number of benefits in the form of abstraction, modularity, re-usability and higher degrees of personalization for the behavior of each NPC. We also show how this architecture can be used to tackle a simple scenario related to the navigation of NPCs under incomplete information about the obstacles that may obstruct the various way-points in the game, in a simple and effective way.