 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-NLP-TOOLKIT: An Open-Source NLP Toolkit for Modern Greek
Dec 11, 2024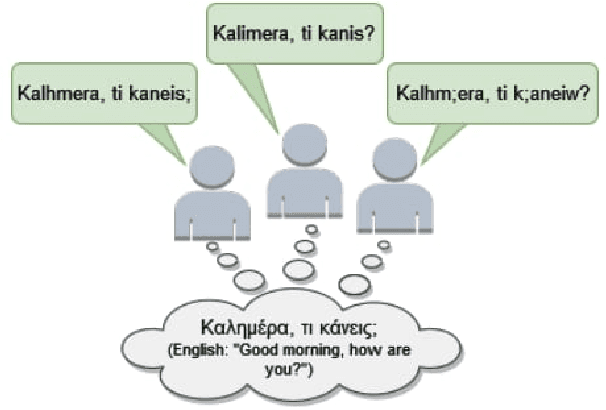

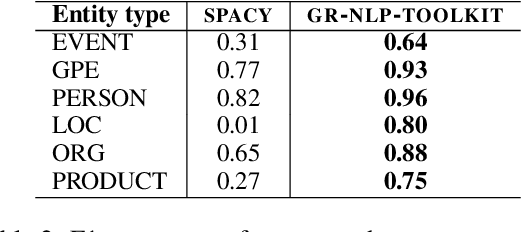
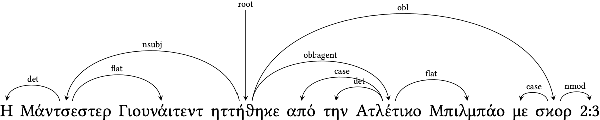
We present GR-NLP-TOOLKIT, an open-source natural language processing (NLP) toolkit developed specifically for modern Greek. The toolkit provides state-of-the-art performance in five core NLP tasks, namely part-of-speech tagging, morphological tagging, dependency parsing, named entity recognition, and Greeklishto-Greek transliteration. The toolkit is based on pre-trained Transformers, it is freely available, and can be easily installed in Python (pip install gr-nlp-toolkit). It is also accessible through a demonstration platform on HuggingFace, along with a publicly available API for non-commercial use. We discuss the functionality provided for each task, the underlying methods, experiments against comparable open-source toolkits, and future possible enhancements. The toolkit is available at: https://github.com/nlpaueb/gr-nlp-toolkit
GREEK-BERT: The Greeks visiting Sesame Street
Sep 03, 2020Transformer-based language models, such as BERT and its variants, have achieved state-of-the-art performance in several downstream natural language processing (NLP) tasks on generic benchmark datasets (e.g., GLUE, SQUAD, RACE). However, these models have mostly been applied to the resource-rich English language. In this paper, we present GREEK-BERT, a monolingual BERT-based language model for modern Greek. We evaluate its performance in three NLP tasks, i.e., part-of-speech tagging, named entity recognition, and natural language inference, obtaining state-of-the-art performance. Interestingly, in two of the benchmarks GREEK-BERT outperforms two multilingual Transformer-based models (M-BERT, XLM-R), as well as shallower neural baselines operating on pre-trained word embeddings, by a large margin (5%-10%). Most importantly, we make both GREEK-BERT and our training code publicly available, along with code illustrating how GREEK-BERT can be fine-tuned for downstream NLP tasks. We expect these resources to boost NLP research and applications for modern Greek.