 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Training Schedule of Multilingual NMT using Reinforcement Learning
Oct 08, 2024



Multilingual NMT is a viable solution for translating low-resource languages (LRLs) when data from high-resource languages (HRLs) from the same language family is available. However, the training schedule, i.e. the order of presentation of languages, has an impact on the quality of such systems. Here, in a many-to-one translation setting, we propose to apply two algorithms that use reinforcement learning to optimize the training schedule of NMT: (1) Teacher-Student Curriculum Learning and (2) Deep Q Network. The former uses an exponentially smoothed estimate of the returns of each action based on the loss on monolingual or multilingual development subsets, while the latter estimates rewards using an additional neural network trained from the history of actions selected in different states of the system, together with the rewards received. On a 8-to-1 translation dataset with LRLs and HRLs, our second method improves BLEU and COMET scores with respect to both random selection of monolingual batches and shuffled multilingual batches, by adjusting the number of presentations of LRL vs. HRL batches.
Can the Variation of Model Weights be used as a Criterion for Self-Paced Multilingual NMT?
Oct 05, 2024Many-to-one neural machine translation systems improve over one-to-one systems when training data is scarce. In this paper, we design and test a novel algorithm for selecting the language of minibatches when training such systems. The algorithm changes the language of the minibatch when the weights of the model do not evolve significantly, as measured by the smoothed KL divergence between all layers of the Transformer network. This algorithm outperforms the use of alternating monolingual batches, but not the use of shuffled batches, in terms of translation quality (measured with BLEU and COMET) and convergence speed.
Small Batch Sizes Improve Training of Low-Resource Neural MT
Mar 20, 2022
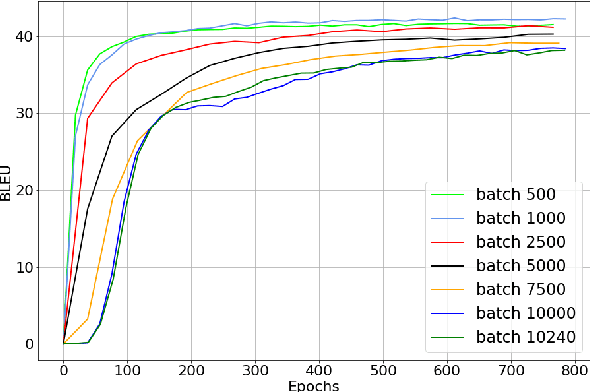
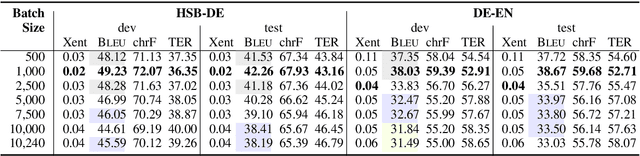

We study the role of an essential hyper-parameter that governs the training of Transformers for neural machine translation in a low-resource setting: the batch size. Using theoretical insights and experimental evidence, we argue against the widespread belief that batch size should be set as large as allowed by the memory of the GPUs. We show that in a low-resource setting, a smaller batch size leads to higher scores in a shorter training time, and argue that this is due to better regularization of the gradients during training.
On the Effect of Word Order on Cross-lingual Sentiment Analysis
Jun 13, 2019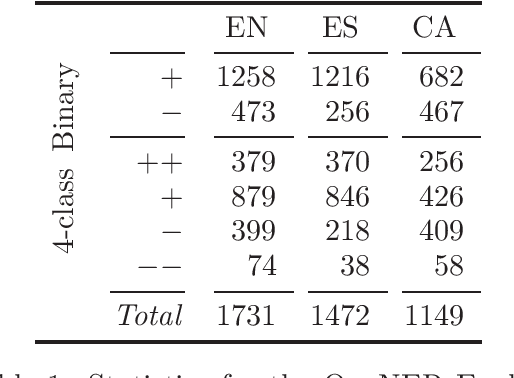

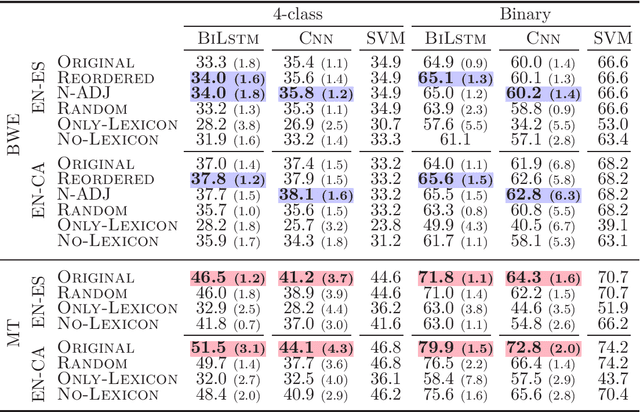
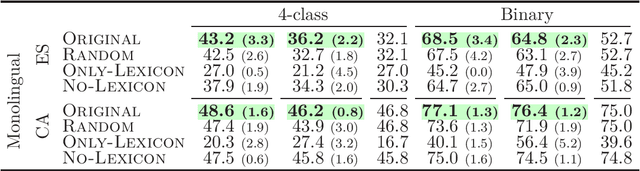
Current state-of-the-art models for sentiment analysis make use of word order either explicitly by pre-training on a language modeling objective or implicitly by using recurrent neural networks (RNNs) or convolutional networks (CNNs). This is a problem for cross-lingual models that use bilingual embeddings as features, as the difference in word order between source and target languages is not resolved. In this work, we explore reordering as a pre-processing step for sentence-level cross-lingual sentiment classification with two language combinations (English-Spanish, English-Catalan). We find that while reordering helps both models, CNNS are more sensitive to local reorderings, while global reordering benefits RNNs.