 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Emotion Intensity Prediction
Apr 08, 2020
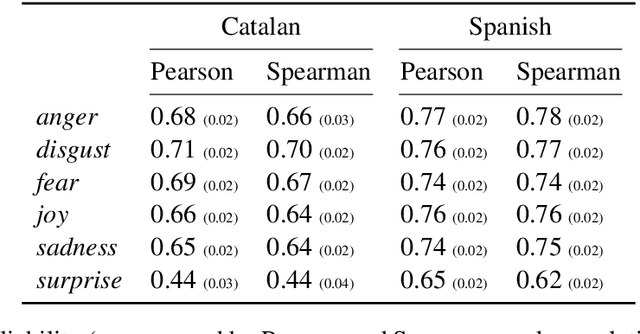
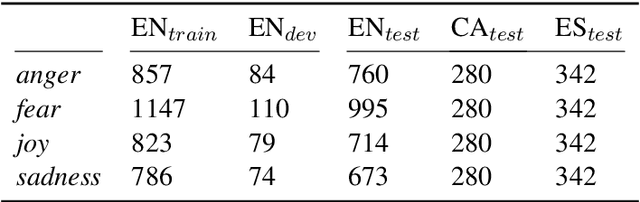
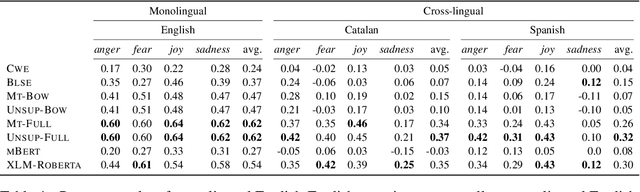
Emotion intensity prediction determines the degree or intensity of an emotion that the author intends to express in a text, extending previous categorical approaches to emotion detection. While most previous work on this topic has concentrated on English texts, other languages would also benefit from fine-grained emotion classification, preferably without having to recreate the amount of annotated data available in English in each new language. Consequently, we explore cross-lingual transfer approaches for fine-grained emotion detection in Spanish and Catalan tweets. To this end we annotate a test set of Spanish and Catalan tweets using Best-Worst scaling. We compare four cross-lingual approaches, e.g., machine translation and cross-lingual embedding projection, which have varying requirements for parallel data -- from millions of parallel sentences to completely unsupervised. The results show that on this data, low-resource methods perform surprisingly better than conventional supervised methods, which we explain through an in-depth error analysis. We make the dataset and the code available at https://github.com/jbarnesspain/fine-grained_cross-lingual_emotion.
On the Effect of Word Order on Cross-lingual Sentiment Analysis
Jun 13, 2019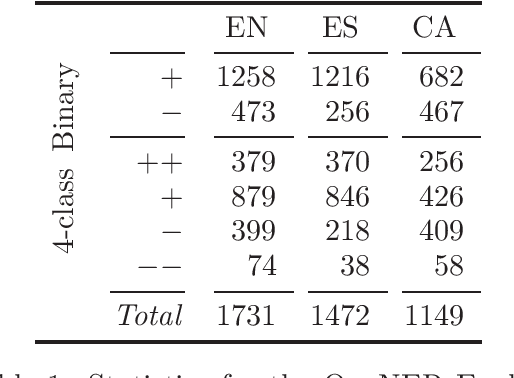

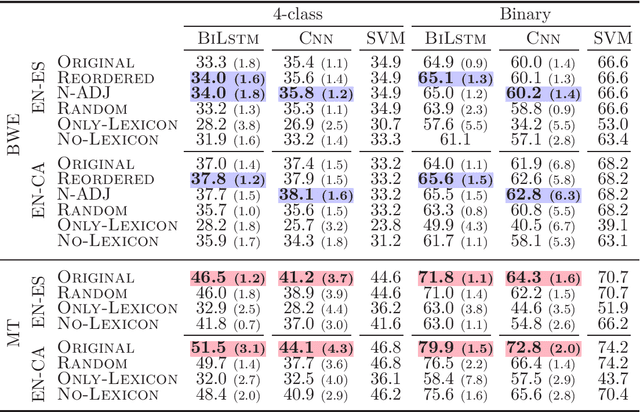
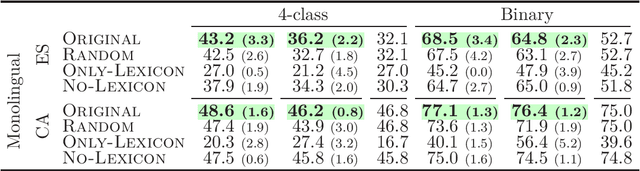
Current state-of-the-art models for sentiment analysis make use of word order either explicitly by pre-training on a language modeling objective or implicitly by using recurrent neural networks (RNNs) or convolutional networks (CNNs). This is a problem for cross-lingual models that use bilingual embeddings as features, as the difference in word order between source and target languages is not resolved. In this work, we explore reordering as a pre-processing step for sentence-level cross-lingual sentiment classification with two language combinations (English-Spanish, English-Catalan). We find that while reordering helps both models, CNNS are more sensitive to local reorderings, while global reordering benefits RNNs.
MultiBooked: A Corpus of Basque and Catalan Hotel Reviews Annotated for Aspect-level Sentiment Classification
Mar 22, 2018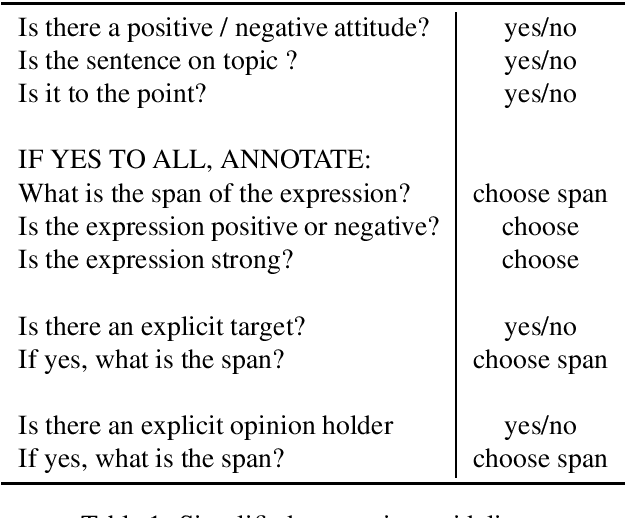
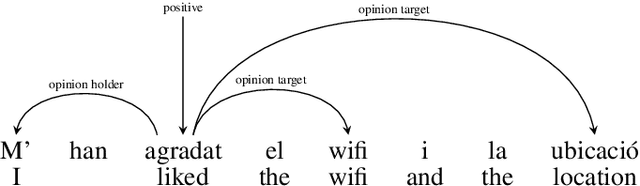
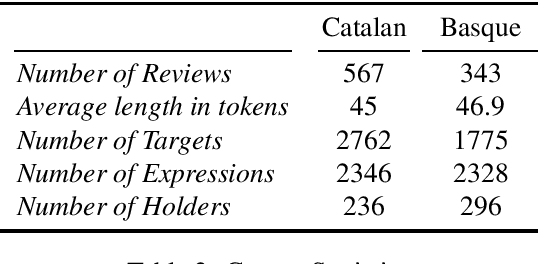
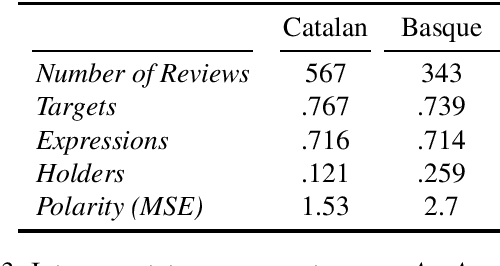
While sentiment analysis has become an established field in the NLP community, research into languages other than English has been hindered by the lack of resources. Although much research in multi-lingual and cross-lingual sentiment analysis has focused on unsupervised or semi-supervised approaches, these still require a large number of resources and do not reach the performance of supervised approaches. With this in mind, we introduce two datasets for supervised aspect-level sentiment analysis in Basque and Catalan, both of which are under-resourced languages. We provide high-quality annotations and benchmarks with the hope that they will be useful to the growing community of researchers working on these languages.