 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMT-Obfuscator Attack: Ignore a sentence in translation with only one word
Nov 19, 2024



Neural Machine Translation systems are used in diverse applications due to their impressive performance. However, recent studies have shown that these systems are vulnerable to carefully crafted small perturbations to their inputs, known as adversarial attacks. In this paper, we propose a new type of adversarial attack against NMT models. In this attack, we find a word to be added between two sentences such that the second sentence is ignored and not translated by the NMT model. The word added between the two sentences is such that the whole adversarial text is natural in the source language. This type of attack can be harmful in practical scenarios since the attacker can hide malicious information in the automatic translation made by the target NMT model. Our experiments show that different NMT models and translation tasks are vulnerable to this type of attack. Our attack can successfully force the NMT models to ignore the second part of the input in the translation for more than 50% of all cases while being able to maintain low perplexity for the whole input.
A Classification-Guided Approach for Adversarial Attacks against Neural Machine Translation
Aug 29, 2023Neural Machine Translation (NMT) models have been shown to be vulnerable to adversarial attacks, wherein carefully crafted perturbations of the input can mislead the target model. In this paper, we introduce ACT, a novel adversarial attack framework against NMT systems guided by a classifier. In our attack, the adversary aims to craft meaning-preserving adversarial examples whose translations by the NMT model belong to a different class than the original translations in the target language. Unlike previous attacks, our new approach has a more substantial effect on the translation by altering the overall meaning, which leads to a different class determined by a classifier. To evaluate the robustness of NMT models to this attack, we propose enhancements to existing black-box word-replacement-based attacks by incorporating output translations of the target NMT model and the output logits of a classifier within the attack process. Extensive experiments in various settings, including a comparison with existing untargeted attacks, demonstrate that the proposed attack is considerably more successful in altering the class of the output translation and has more effect on the translation. This new paradigm can show the vulnerabilities of NMT systems by focusing on the class of translation rather than the mere translation quality as studied traditionally.
A Relaxed Optimization Approach for Adversarial Attacks against Neural Machine Translation Models
Jun 14, 2023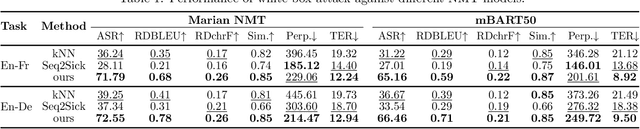
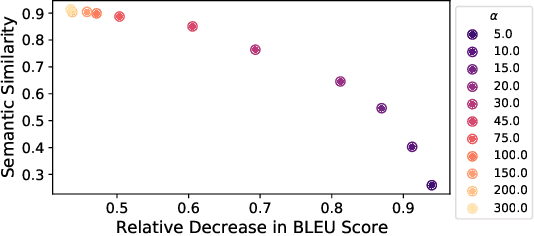

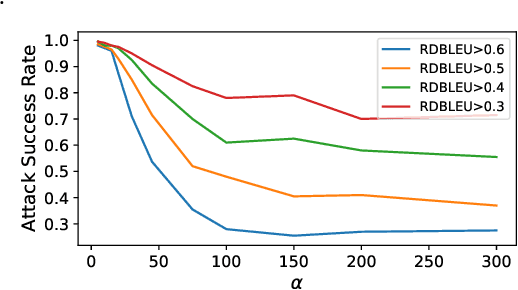
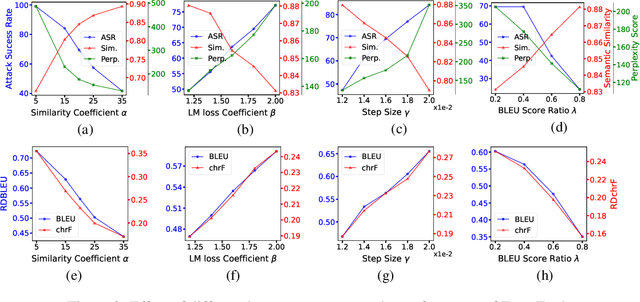
In this paper, we propose an optimization-based adversarial attack against Neural Machine Translation (NMT) models. First, we propose an optimization problem to generate adversarial examples that are semantically similar to the original sentences but destroy the translation generated by the target NMT model. This optimization problem is discrete, and we propose a continuous relaxation to solve it. With this relaxation, we find a probability distribution for each token in the adversarial example, and then we can generate multiple adversarial examples by sampling from these distributions. Experimental results show that our attack significantly degrades the translation quality of multiple NMT models while maintaining the semantic similarity between the original and adversarial sentences. Furthermore, our attack outperforms the baselines in terms of success rate, similarity preservation, effect on translation quality, and token error rate. Finally, we propose a black-box extension of our attack by sampling from an optimized probability distribution for a reference model whose gradients are accessible.
Targeted Adversarial Attacks against Neural Machine Translation
Mar 02, 2023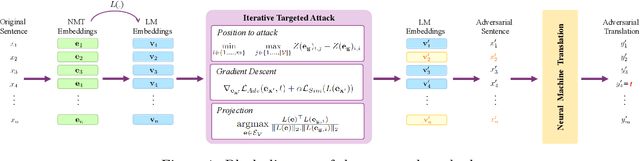

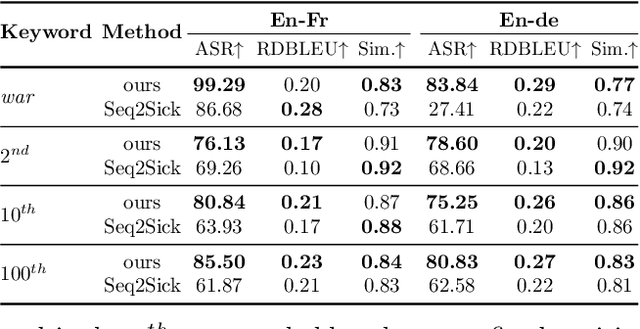
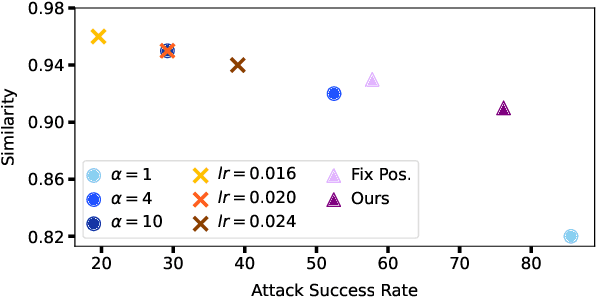
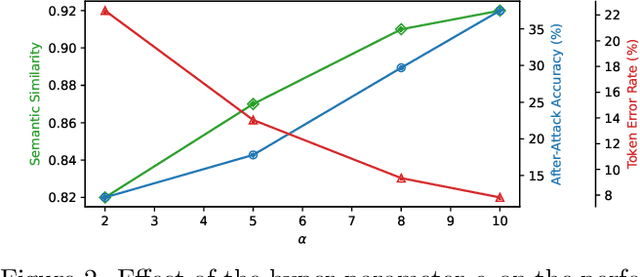
Neural Machine Translation (NMT) systems are used in various applications. However, it has been shown that they are vulnerable to very small perturbations of their inputs, known as adversarial attacks. In this paper, we propose a new targeted adversarial attack against NMT models. In particular, our goal is to insert a predefined target keyword into the translation of the adversarial sentence while maintaining similarity between the original sentence and the perturbed one in the source domain. To this aim, we propose an optimization problem, including an adversarial loss term and a similarity term. We use gradient projection in the embedding space to craft an adversarial sentence. Experimental results show that our attack outperforms Seq2Sick, the other targeted adversarial attack against NMT models, in terms of success rate and decrease in translation quality. Our attack succeeds in inserting a keyword into the translation for more than 75% of sentences while similarity with the original sentence stays preserved.
TransFool: An Adversarial Attack against Neural Machine Translation Models
Feb 02, 2023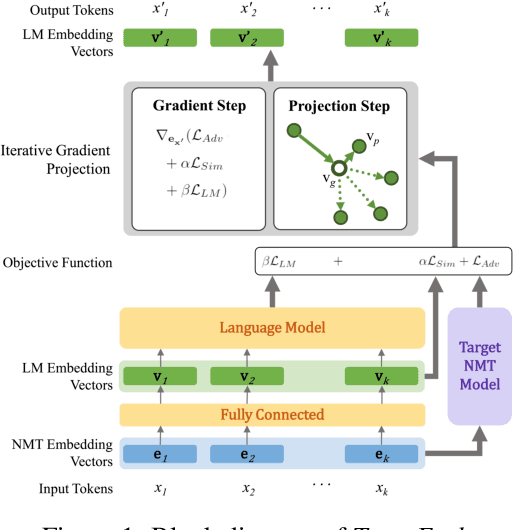
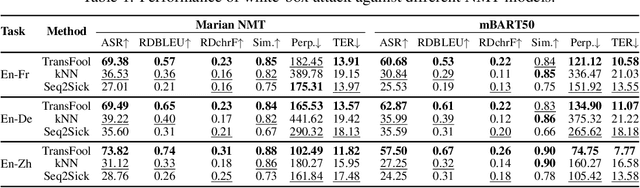

Deep neural networks have been shown to be vulnerable to small perturbations of their inputs, known as adversarial attacks. In this paper, we investigate the vulnerability of Neural Machine Translation (NMT) models to adversarial attacks and propose a new attack algorithm called TransFool. To fool NMT models, TransFool builds on a multi-term optimization problem and a gradient projection step. By integrating the embedding representation of a language model, we generate fluent adversarial examples in the source language that maintain a high level of semantic similarity with the clean samples. Experimental results demonstrate that, for different translation tasks and NMT architectures, our white-box attack can severely degrade the translation quality while the semantic similarity between the original and the adversarial sentences stays high. Moreover, we show that TransFool is transferable to unknown target models. Finally, based on automatic and human evaluations, TransFool leads to improvement in terms of success rate, semantic similarity, and fluency compared to the existing attacks both in white-box and black-box settings. Thus, TransFool permits us to better characterize the vulnerability of NMT models and outlines the necessity to design strong defense mechanisms and more robust NMT systems for real-life applications.
Block-Sparse Adversarial Attack to Fool Transformer-Based Text Classifiers
Mar 11, 2022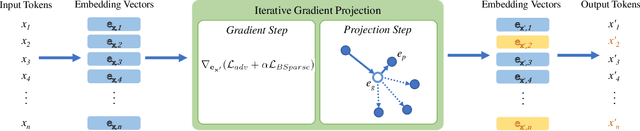

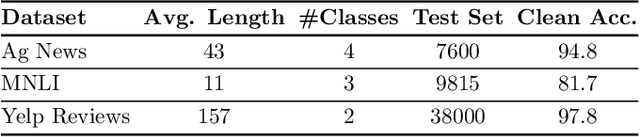
Recently, it has been shown that, in spite of the significant performance of deep neural networks in different fields, those are vulnerable to adversarial examples. In this paper, we propose a gradient-based adversarial attack against transformer-based text classifiers. The adversarial perturbation in our method is imposed to be block-sparse so that the resultant adversarial example differs from the original sentence in only a few words. Due to the discrete nature of textual data, we perform gradient projection to find the minimizer of our proposed optimization problem. Experimental results demonstrate that, while our adversarial attack maintains the semantics of the sentence, it can reduce the accuracy of GPT-2 to less than 5% on different datasets (AG News, MNLI, and Yelp Reviews). Furthermore, the block-sparsity constraint of the proposed optimization problem results in small perturbations in the adversarial example.