 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Systematic Monolingual NLP Surveys: GenA of Greek NLP
Jul 13, 2024Natural Language Processing (NLP) research has traditionally been predominantly focused on English, driven by the availability of resources, the size of the research community, and market demands. Recently, there has been a noticeable shift towards multilingualism in NLP, recognizing the need for inclusivity and effectiveness across diverse languages and cultures. Monolingual surveys have the potential to complement the broader trend towards multilingualism in NLP by providing foundational insights and resources necessary for effectively addressing the linguistic diversity of global communication. However, monolingual NLP surveys are extremely rare in literature. This study fills the gap by introducing a method for creating systematic and comprehensive monolingual NLP surveys. Characterized by a structured search protocol, it can be used to select publications and organize them through a taxonomy of NLP tasks. We include a classification of Language Resources (LRs), according to their availability, and datasets, according to their annotation, to highlight publicly-available and machine-actionable LRs. By applying our method, we conducted a systematic literature review of Greek NLP from 2012 to 2022, providing a comprehensive overview of the current state and challenges of Greek NLP research. We discuss the progress of Greek NLP and outline encountered Greek LRs, classified by availability and usability. As we show, our proposed method helps avoid common pitfalls, such as data leakage and contamination, and to assess language support per NLP task. We consider this systematic literature review of Greek NLP an application of our method that showcases the benefits of a monolingual NLP survey. Similar applications could be regard the myriads of languages whose progress in NLP lags behind that of well-supported languages.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020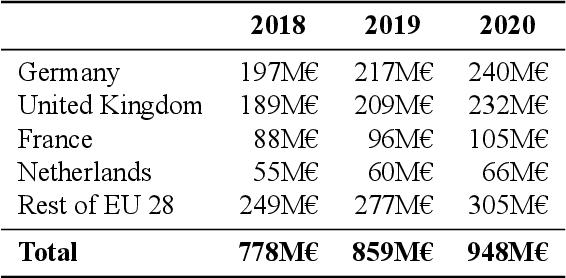
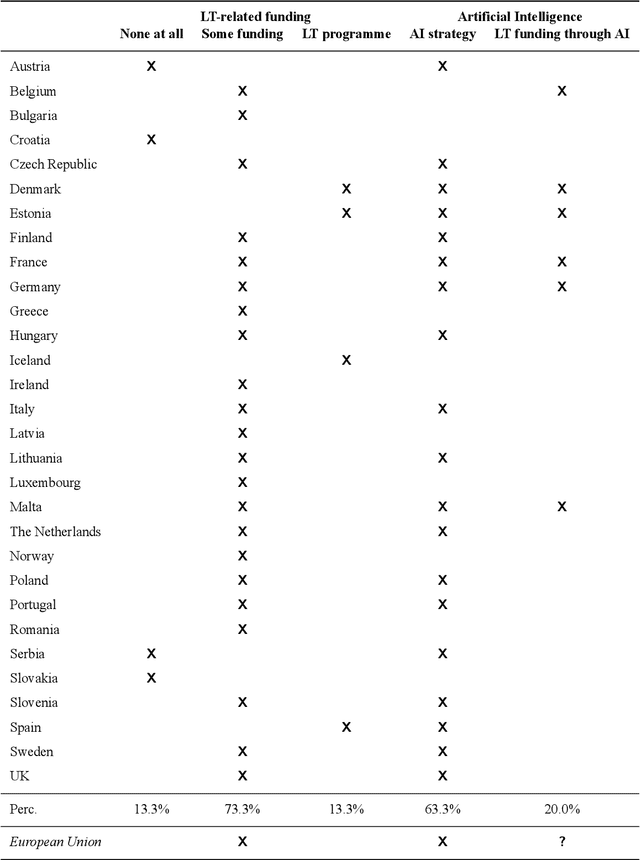
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
Making Metadata Fit for Next Generation Language Technology Platforms: The Metadata Schema of the European Language Grid
Mar 30, 2020
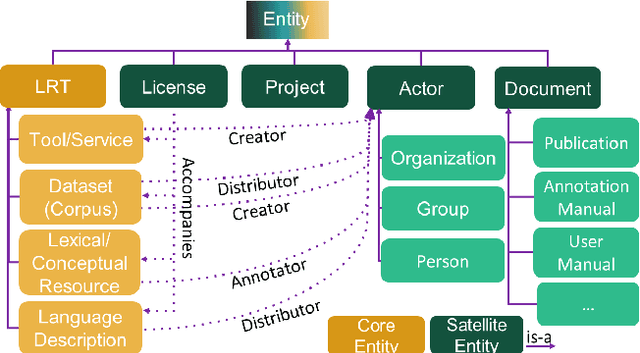
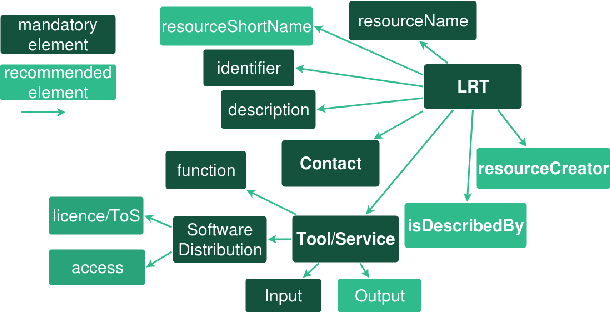

The current scientific and technological landscape is characterised by the increasing availability of data resources and processing tools and services. In this setting, metadata have emerged as a key factor facilitating management, sharing and usage of such digital assets. In this paper we present ELG-SHARE, a rich metadata schema catering for the description of Language Resources and Technologies (processing and generation services and tools, models, corpora, term lists, etc.), as well as related entities (e.g., organizations, projects, supporting documents, etc.). The schema powers the European Language Grid platform that aims to be the primary hub and marketplace for industry-relevant Language Technology in Europe. ELG-SHARE has been based on various metadata schemas, vocabularies, and ontologies, as well as related recommendations and guidelines.