 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Voice Activity Detection with Self-Supervised Representations
Paper and Code
Sep 22, 2022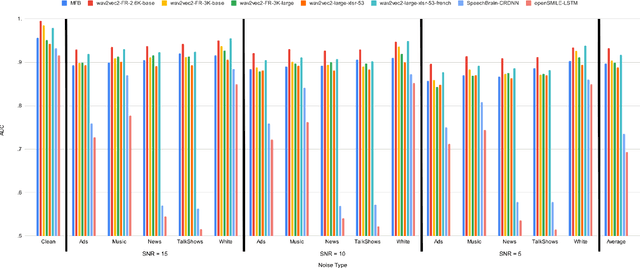
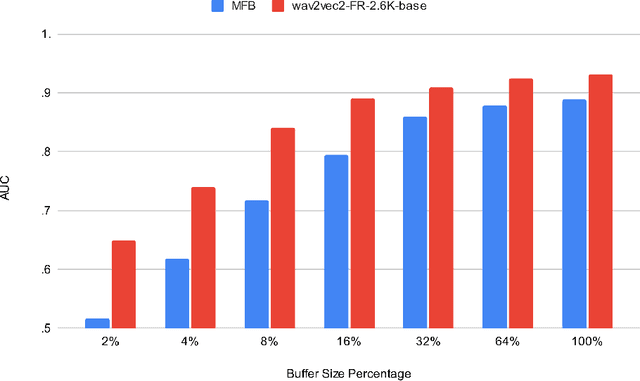
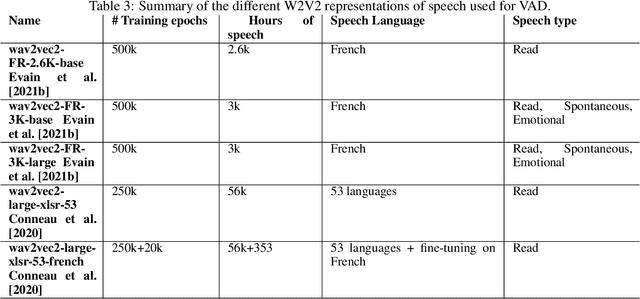
Voice Activity Detection (VAD) aims at detecting speech segments on an audio signal, which is a necessary first step for many today's speech based applications. Current state-of-the-art methods focus on training a neural network exploiting features directly contained in the acoustics, such as Mel Filter Banks (MFBs). Such methods therefore require an extra normalisation step to adapt to a new domain where the acoustics is impacted, which can be simply due to a change of speaker, microphone, or environment. In addition, this normalisation step is usually a rather rudimentary method that has certain limitations, such as being highly susceptible to the amount of data available for the new domain. Here, we exploited the crowd-sourced Common Voice (CV) corpus to show that representations based on Self-Supervised Learning (SSL) can adapt well to different domains, because they are computed with contextualised representations of speech across multiple domains. SSL representations also achieve better results than systems based on hand-crafted representations (MFBs), and off-the-shelf VADs, with significant improvement in cross-domain settings.