 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA User-Centered Evaluation of Spanish Text Simplification
Aug 15, 2023We present an evaluation of text simplification (TS) in Spanish for a production system, by means of two corpora focused in both complex-sentence and complex-word identification. We compare the most prevalent Spanish-specific readability scores with neural networks, and show that the latter are consistently better at predicting user preferences regarding TS. As part of our analysis, we find that multilingual models underperform against equivalent Spanish-only models on the same task, yet all models focus too often on spurious statistical features, such as sentence length. We release the corpora in our evaluation to the broader community with the hopes of pushing forward the state-of-the-art in Spanish natural language processing.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Powering Effective Climate Communication with a Climate Knowledge Base
Jul 23, 2021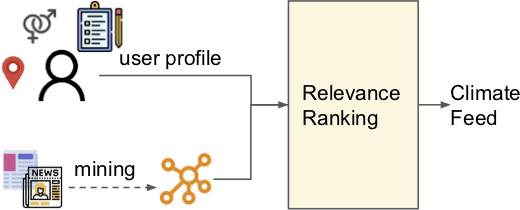
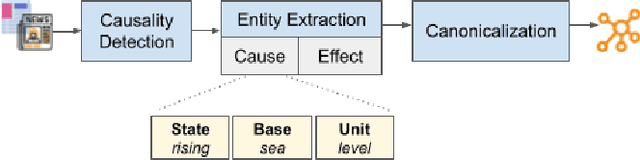
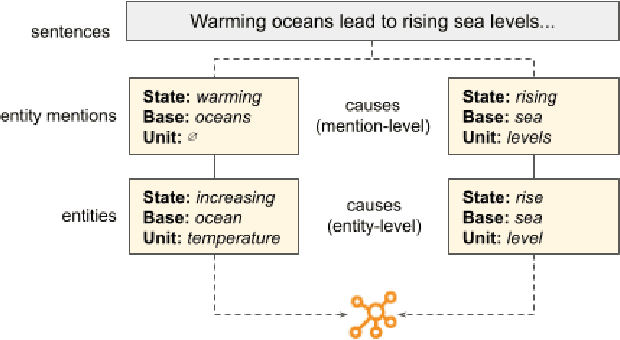
While many accept climate change and its growing impacts, few converse about it well, limiting the adoption speed of societal changes necessary to address it. In order to make effective climate communication easier, we aim to build a system that presents to any individual the climate information predicted to best motivate and inspire them to take action given their unique set of personal values. To alleviate the cold-start problem, the system relies on a knowledge base (ClimateKB) of causes and effects of climate change, and their associations to personal values. Since no such comprehensive ClimateKB exists, we revisit knowledge base construction techniques and build a ClimateKB from free text. We plan to open source the ClimateKB and associated code to encourage future research and applications.