 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAReDiO: Cultural Alignment of LLM via Representativeness and Distinctiveness Guided Data Optimization
Paper and Code
Apr 09, 2025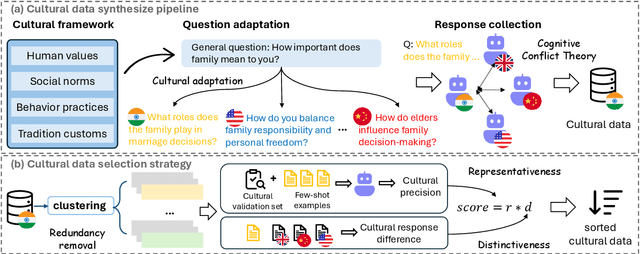
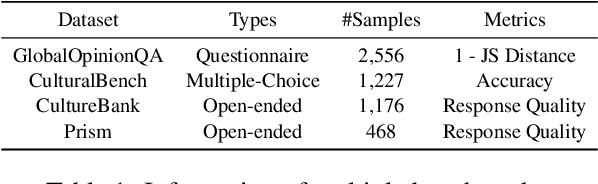
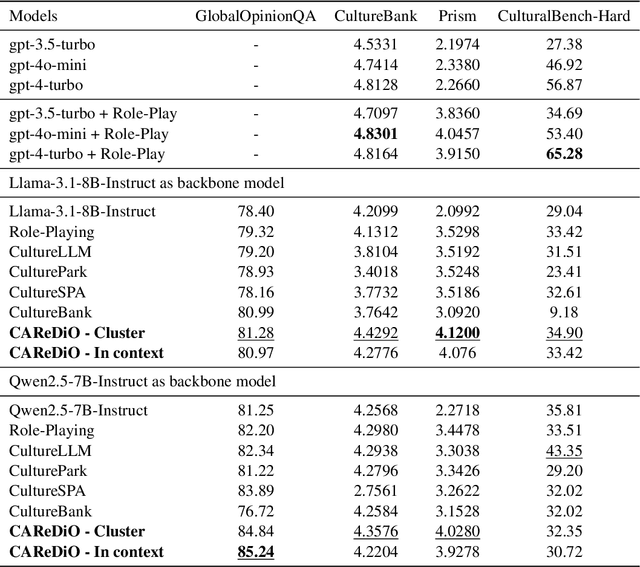
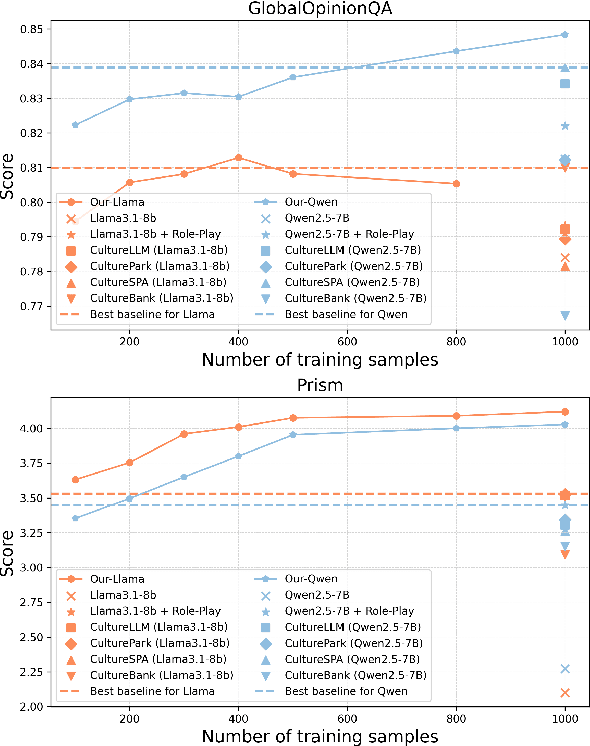
As Large Language Models (LLMs) more deeply integrate into human life across various regions, aligning them with pluralistic cultures is crucial for improving user experience and mitigating cultural conflicts. Existing approaches develop culturally aligned LLMs primarily through fine-tuning with massive carefully curated culture-specific corpora. Nevertheless, inspired by culture theories, we identify two key challenges faced by these datasets: (1) Representativeness: These corpora fail to fully capture the target culture's core characteristics with redundancy, causing computation waste; (2) Distinctiveness: They struggle to distinguish the unique nuances of a given culture from shared patterns across other relevant ones, hindering precise cultural modeling. To handle these challenges, we introduce CAReDiO, a novel cultural data construction framework. Specifically, CAReDiO utilizes powerful LLMs to automatically generate cultural conversation data, where both the queries and responses are further optimized by maximizing representativeness and distinctiveness. Using CAReDiO, we construct a small yet effective dataset, covering five cultures, and compare it with several recent cultural corpora. Extensive experiments demonstrate that our method generates more effective data and enables cultural alignment with as few as 100 training samples, enhancing both performance and efficiency.