 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAMeGEn: Creative Name Generation via A Novel Agent-based Multiple Personalized Goal Enhancement Framework
Nov 19, 2025Trained on diverse human-authored texts, Large Language Models (LLMs) unlocked the potential for Creative Natural Language Generation (CNLG), benefiting various applications like advertising and storytelling. Nevertheless, CNLG still remains difficult due to two main challenges. (1) Multi-objective flexibility: user requirements are often personalized, fine-grained, and pluralistic, which LLMs struggle to satisfy simultaneously; (2) Interpretive complexity: beyond generation, creativity also involves understanding and interpreting implicit meaning to enhance users' perception. These challenges significantly limit current methods, especially in short-form text generation, in generating creative and insightful content. To address this, we focus on Chinese baby naming, a representative short-form CNLG task requiring adherence to explicit user constraints (e.g., length, semantics, anthroponymy) while offering meaningful aesthetic explanations. We propose NAMeGEn, a novel multi-agent optimization framework that iteratively alternates between objective extraction, name generation, and evaluation to meet diverse requirements and generate accurate explanations. To support this task, we further construct a classical Chinese poetry corpus with 17k+ poems to enhance aesthetics, and introduce CBNames, a new benchmark with tailored metrics. Extensive experiments demonstrate that NAMeGEn effectively generates creative names that meet diverse, personalized requirements while providing meaningful explanations, outperforming six baseline methods spanning various LLM backbones without any training.
On the Essence and Prospect: An Investigation of Alignment Approaches for Big Models
Mar 07, 2024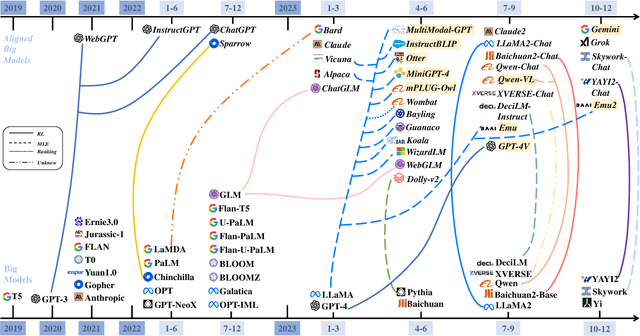
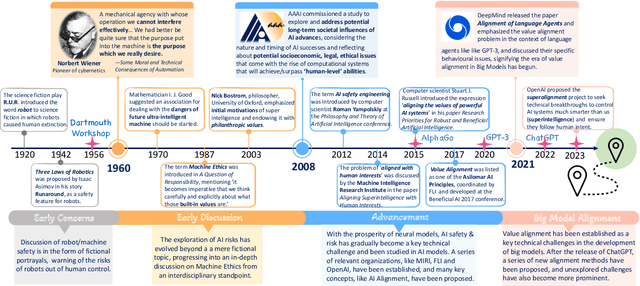
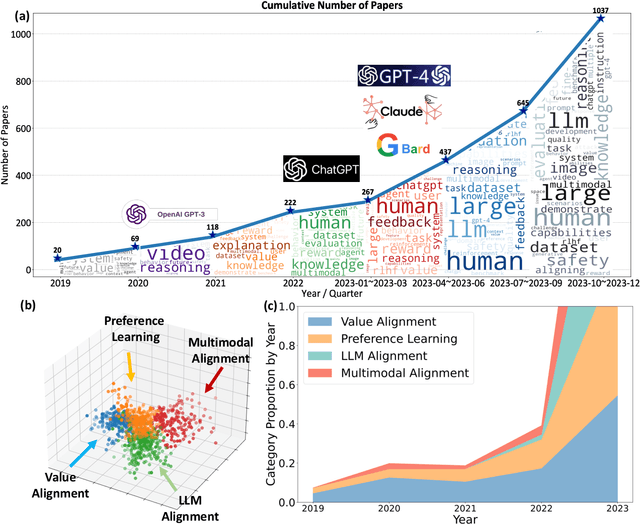
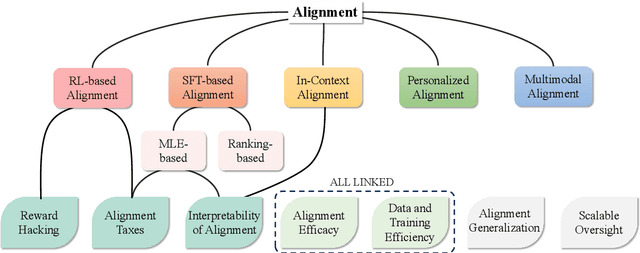
Big models have achieved revolutionary breakthroughs in the field of AI, but they might also pose potential concerns. Addressing such concerns, alignment technologies were introduced to make these models conform to human preferences and values. Despite considerable advancements in the past year, various challenges lie in establishing the optimal alignment strategy, such as data cost and scalable oversight, and how to align remains an open question. In this survey paper, we comprehensively investigate value alignment approaches. We first unpack the historical context of alignment tracing back to the 1920s (where it comes from), then delve into the mathematical essence of alignment (what it is), shedding light on the inherent challenges. Following this foundation, we provide a detailed examination of existing alignment methods, which fall into three categories: Reinforcement Learning, Supervised Fine-Tuning, and In-context Learning, and demonstrate their intrinsic connections, strengths, and limitations, helping readers better understand this research area. In addition, two emerging topics, personal alignment, and multimodal alignment, are also discussed as novel frontiers in this field. Looking forward, we discuss potential alignment paradigms and how they could handle remaining challenges, prospecting where future alignment will go.
ToViLaG: Your Visual-Language Generative Model is Also An Evildoer
Dec 13, 2023



Warning: this paper includes model outputs showing offensive content. Recent large-scale Visual-Language Generative Models (VLGMs) have achieved unprecedented improvement in multimodal image/text generation. However, these models might also generate toxic content, e.g., offensive text and pornography images, raising significant ethical risks. Despite exhaustive studies on toxic degeneration of language models, this problem remains largely unexplored within the context of visual-language generation. This work delves into the propensity for toxicity generation and susceptibility to toxic data across various VLGMs. For this purpose, we built ToViLaG, a dataset comprising 32K co-toxic/mono-toxic text-image pairs and 1K innocuous but evocative text that tends to stimulate toxicity. Furthermore, we propose WInToRe, a novel toxicity metric tailored to visual-language generation, which theoretically reflects different aspects of toxicity considering both input and output. On such a basis, we benchmarked the toxicity of a diverse spectrum of VLGMs and discovered that some models do more evil than expected while some are more vulnerable to infection, underscoring the necessity of VLGMs detoxification. Therefore, we develop an innovative bottleneck-based detoxification method. Our method could reduce toxicity while maintaining comparable generation quality, providing a promising initial solution to this line of research.
CHAE: Fine-Grained Controllable Story Generation with Characters, Actions and Emotions
Oct 11, 2022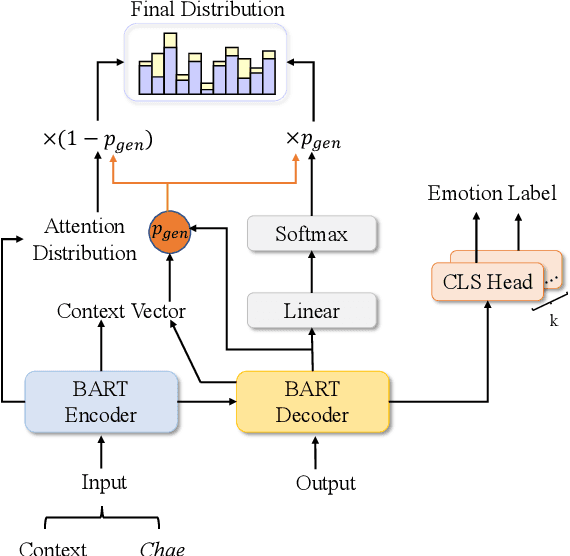


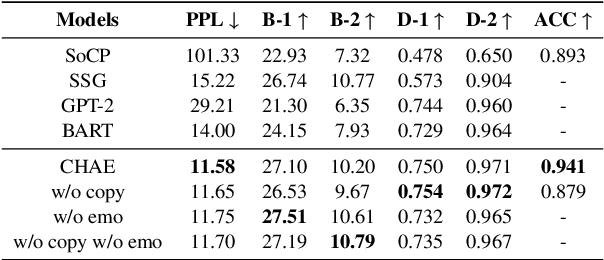
Story generation has emerged as an interesting yet challenging NLP task in recent years. Some existing studies aim at generating fluent and coherent stories from keywords and outlines; while others attempt to control the global features of the story, such as emotion, style and topic. However, these works focus on coarse-grained control on the story, neglecting control on the details of the story, which is also crucial for the task. To fill the gap, this paper proposes a model for fine-grained control on the story, which allows the generation of customized stories with characters, corresponding actions and emotions arbitrarily assigned. Extensive experimental results on both automatic and human manual evaluations show the superiority of our method. It has strong controllability to generate stories according to the fine-grained personalized guidance, unveiling the effectiveness of our methodology. Our code is available at https://github.com/victorup/CHAE.
Open-domain Dialogue Generation Grounded with Dynamic Multi-form Knowledge Fusion
Apr 24, 2022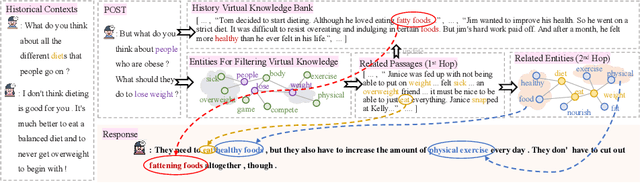

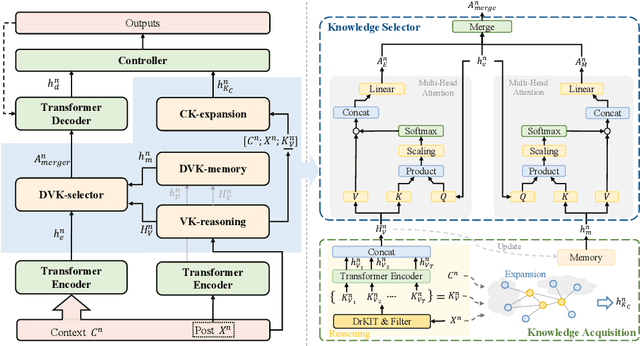
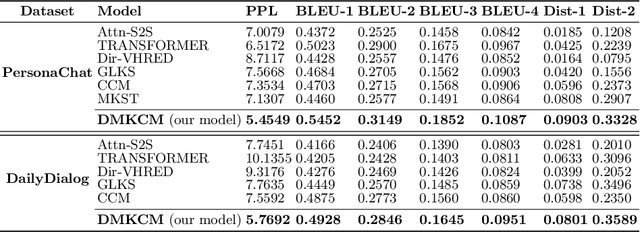
Open-domain multi-turn conversations normally face the challenges of how to enrich and expand the content of the conversation. Recently, many approaches based on external knowledge are proposed to generate rich semantic and information conversation. Two types of knowledge have been studied for knowledge-aware open-domain dialogue generation: structured triples from knowledge graphs and unstructured texts from documents. To take both advantages of abundant unstructured latent knowledge in the documents and the information expansion capabilities of the structured knowledge graph, this paper presents a new dialogue generation model, Dynamic Multi-form Knowledge Fusion based Open-domain Chatt-ing Machine (DMKCM).In particular, DMKCM applies an indexed text (a virtual Knowledge Base) to locate relevant documents as 1st hop and then expands the content of the dialogue and its 1st hop using a commonsense knowledge graph to get apposite triples as 2nd hop. To merge these two forms of knowledge into the dialogue effectively, we design a dynamic virtual knowledge selector and a controller that help to enrich and expand knowledge space. Moreover, DMKCM adopts a novel dynamic knowledge memory module that effectively uses historical reasoning knowledge to generate better responses. Experimental results indicate the effectiveness of our method in terms of dialogue coherence and informativeness.
Controllable Multi-Character Psychology-Oriented Story Generation
Oct 11, 2020
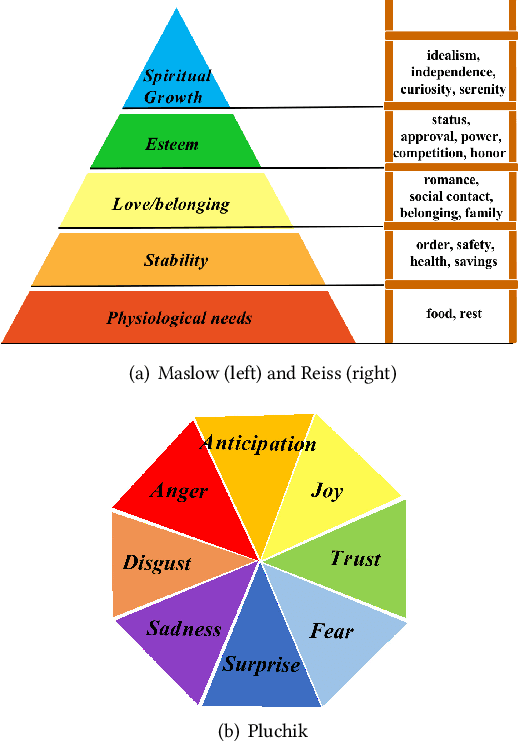
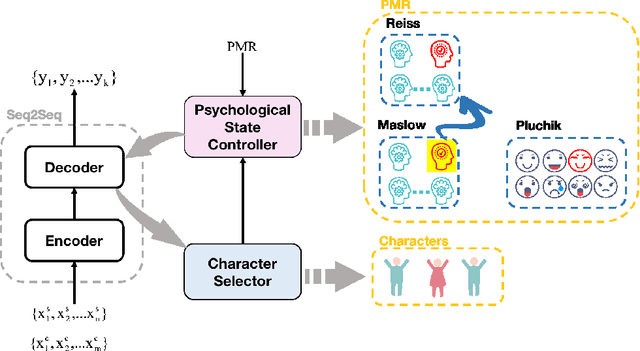
Story generation, which aims to generate a long and coherent story automatically based on the title or an input sentence, is an important research area in the field of natural language generation. There is relatively little work on story generation with appointed emotions. Most existing works focus on using only one specific emotion to control the generation of a whole story and ignore the emotional changes in the characters in the course of the story. In our work, we aim to design an emotional line for each character that considers multiple emotions common in psychological theories, with the goal of generating stories with richer emotional changes in the characters. To the best of our knowledge, this work is first to focuses on characters' emotional lines in story generation. We present a novel model-based attention mechanism that we call SoCP (Storytelling of multi-Character Psychology). We show that the proposed model can generate stories considering the changes in the psychological state of different characters. To take into account the particularity of the model, in addition to commonly used evaluation indicators(BLEU, ROUGE, etc.), we introduce the accuracy rate of psychological state control as a novel evaluation metric. The new indicator reflects the effect of the model on the psychological state control of story characters. Experiments show that with SoCP, the generated stories follow the psychological state for each character according to both automatic and human evaluations.