 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Momentum-based Paradigm of Decentralized SGD for Non-Convex Models and Heterogeneous Data
Mar 01, 2023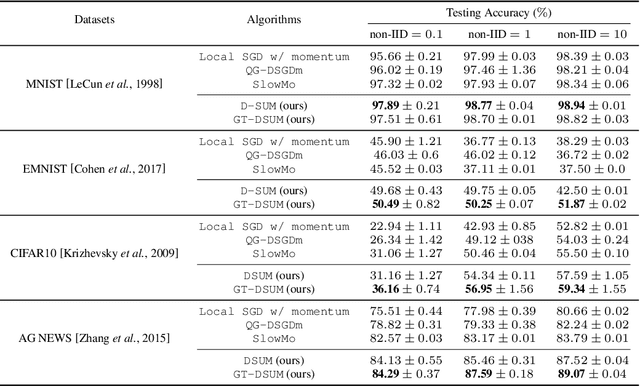
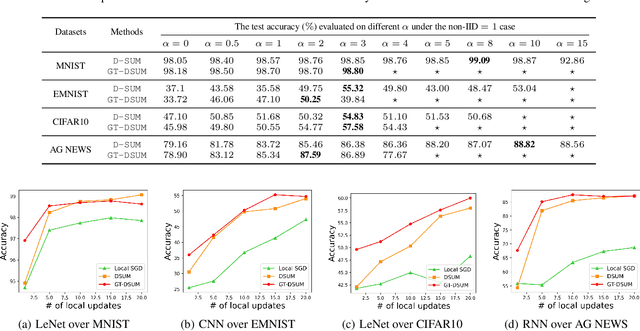
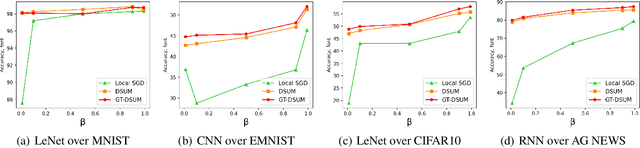
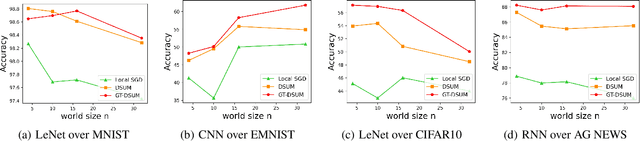
Emerging distributed applications recently boosted the development of decentralized machine learning, especially in IoT and edge computing fields. In real-world scenarios, the common problems of non-convexity and data heterogeneity result in inefficiency, performance degradation, and development stagnation. The bulk of studies concentrates on one of the issues mentioned above without having a more general framework that has been proven optimal. To this end, we propose a unified paradigm called UMP, which comprises two algorithms, D-SUM and GT-DSUM, based on the momentum technique with decentralized stochastic gradient descent(SGD). The former provides a convergence guarantee for general non-convex objectives. At the same time, the latter is extended by introducing gradient tracking, which estimates the global optimization direction to mitigate data heterogeneity(i.e., distribution drift). We can cover most momentum-based variants based on the classical heavy ball or Nesterov's acceleration with different parameters in UMP. In theory, we rigorously provide the convergence analysis of these two approaches for non-convex objectives and conduct extensive experiments, demonstrating a significant improvement in model accuracy by up to 57.6% compared to other methods in practice.
Aggregation in the Mirror Space : Fast, Accurate Distributed Machine Learning in Military Settings
Oct 28, 2022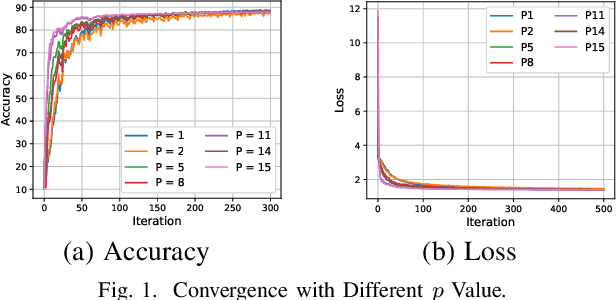
Distributed machine learning (DML) can be an important capability for modern military to take advantage of data and devices distributed at multiple vantage points to adapt and learn. The existing distributed machine learning frameworks, however, cannot realize the full benefits of DML, because they are all based on the simple linear aggregation framework, but linear aggregation cannot handle the $\textit{divergence challenges}$ arising in military settings: the learning data at different devices can be heterogeneous ($\textit{i.e.}$, Non-IID data), leading to model divergence, but the ability for devices to communicate is substantially limited ($\textit{i.e.}$, weak connectivity due to sparse and dynamic communications), reducing the ability for devices to reconcile model divergence. In this paper, we introduce a novel DML framework called aggregation in the mirror space (AIMS) that allows a DML system to introduce a general mirror function to map a model into a mirror space to conduct aggregation and gradient descent. Adapting the convexity of the mirror function according to the divergence force, AIMS allows automatic optimization of DML. We conduct both rigorous analysis and extensive experimental evaluations to demonstrate the benefits of AIMS. For example, we prove that AIMS achieves a loss of $O\left((\frac{m^{r+1}}{T})^{\frac1r}\right)$ after $T$ network-wide updates, where $m$ is the number of devices and $r$ the convexity of the mirror function, with existing linear aggregation frameworks being a special case with $r=2$. Our experimental evaluations using EMANE (Extendable Mobile Ad-hoc Network Emulator) for military communications settings show similar results: AIMS can improve DML convergence rate by up to 57\% and scale well to more devices with weak connectivity, all with little additional computation overhead compared to traditional linear aggregation.
Achieving Efficient Distributed Machine Learning Using a Novel Non-Linear Class of Aggregation Functions
Jan 29, 2022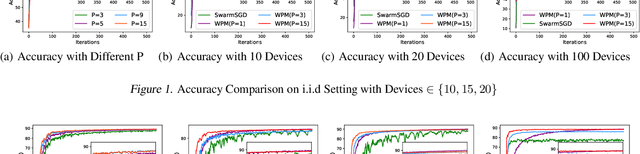
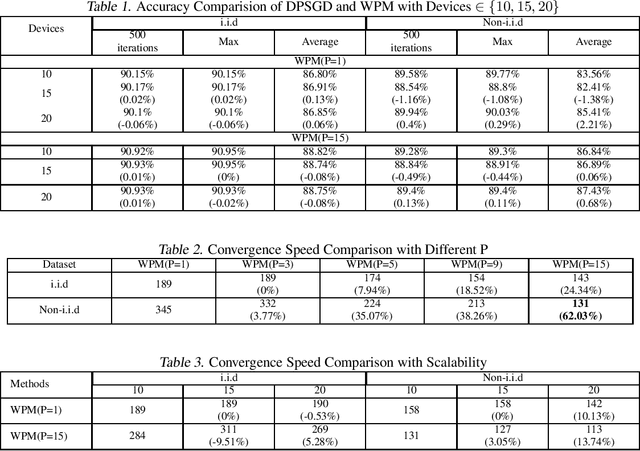


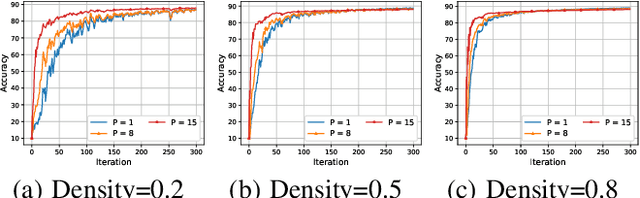
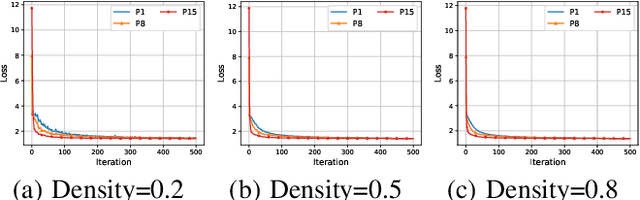
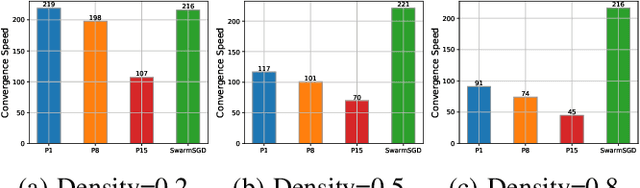
Distributed machine learning (DML) over time-varying networks can be an enabler for emerging decentralized ML applications such as autonomous driving and drone fleeting. However, the commonly used weighted arithmetic mean model aggregation function in existing DML systems can result in high model loss, low model accuracy, and slow convergence speed over time-varying networks. To address this issue, in this paper, we propose a novel non-linear class of model aggregation functions to achieve efficient DML over time-varying networks. Instead of taking a linear aggregation of neighboring models as most existing studies do, our mechanism uses a nonlinear aggregation, a weighted power-p mean (WPM) where p is a positive odd integer, as the aggregation function of local models from neighbors. The subsequent optimizing steps are taken using mirror descent defined by a Bregman divergence that maintains convergence to optimality. In this paper, we analyze properties of the WPM and rigorously prove convergence properties of our aggregation mechanism. Additionally, through extensive experiments, we show that when p > 1, our design significantly improves the convergence speed of the model and the scalability of DML under time-varying networks compared with arithmetic mean aggregation functions, with little additional 26computation overhead.
Vulcan: Solving the Steiner Tree Problem with Graph Neural Networks and Deep Reinforcement Learning
Nov 21, 2021

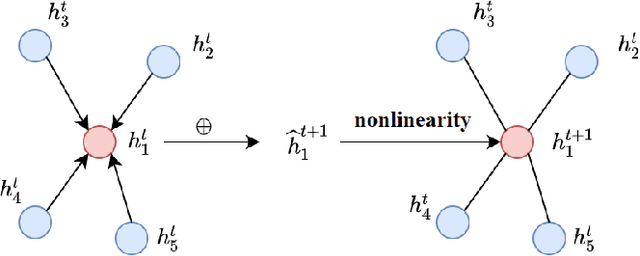

Steiner Tree Problem (STP) in graphs aims to find a tree of minimum weight in the graph that connects a given set of vertices. It is a classic NP-hard combinatorial optimization problem and has many real-world applications (e.g., VLSI chip design, transportation network planning and wireless sensor networks). Many exact and approximate algorithms have been developed for STP, but they suffer from high computational complexity and weak worst-case solution guarantees, respectively. Heuristic algorithms are also developed. However, each of them requires application domain knowledge to design and is only suitable for specific scenarios. Motivated by the recently reported observation that instances of the same NP-hard combinatorial problem may maintain the same or similar combinatorial structure but mainly differ in their data, we investigate the feasibility and benefits of applying machine learning techniques to solving STP. To this end, we design a novel model Vulcan based on novel graph neural networks and deep reinforcement learning. The core of Vulcan is a novel, compact graph embedding that transforms highdimensional graph structure data (i.e., path-changed information) into a low-dimensional vector representation. Given an STP instance, Vulcan uses this embedding to encode its pathrelated information and sends the encoded graph to a deep reinforcement learning component based on a double deep Q network (DDQN) to find solutions. In addition to STP, Vulcan can also find solutions to a wide range of NP-hard problems (e.g., SAT, MVC and X3C) by reducing them to STP. We implement a prototype of Vulcan and demonstrate its efficacy and efficiency with extensive experiments using real-world and synthetic datasets.
Isomer: Transfer enhanced Dual-Channel Heterogeneous Dependency Attention Network for Aspect-based Sentiment Classification
Nov 21, 2021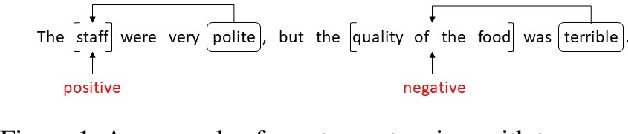
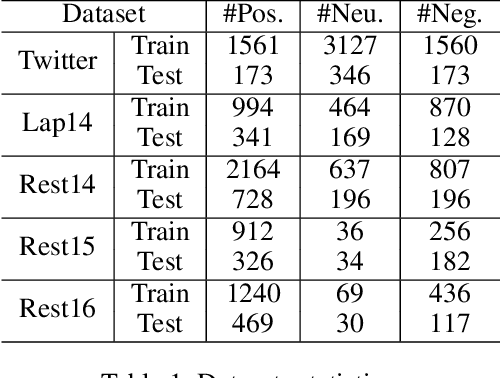
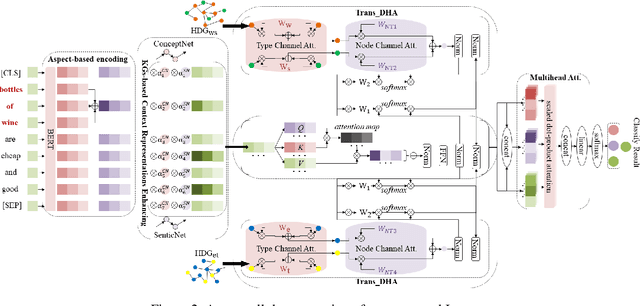
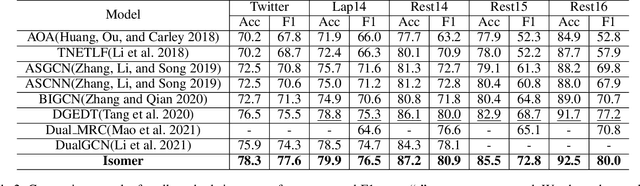
Aspect-based sentiment classification aims to predict the sentiment polarity of a specific aspect in a sentence. However, most existing methods attempt to construct dependency relations into a homogeneous dependency graph with the sparsity and ambiguity, which cannot cover the comprehensive contextualized features of short texts or consider any additional node types or semantic relation information. To solve those issues, we present a sentiment analysis model named Isomer, which performs a dual-channel attention on heterogeneous dependency graphs incorporating external knowledge, to effectively integrate other additional information. Specifically, a transfer-enhanced dual-channel heterogeneous dependency attention network is devised in Isomer to model short texts using heterogeneous dependency graphs. These heterogeneous dependency graphs not only consider different types of information but also incorporate external knowledge. Experiments studies show that our model outperforms recent models on benchmark datasets. Furthermore, the results suggest that our method captures the importance of various information features to focus on informative contextual words.
Toward Efficient Federated Learning in Multi-Channeled Mobile Edge Network with Layerd Gradient Compression
Sep 18, 2021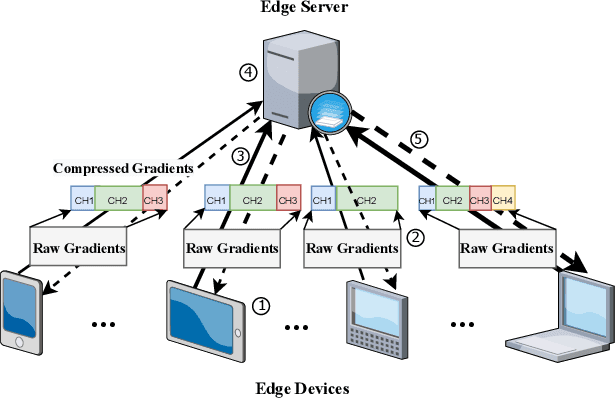

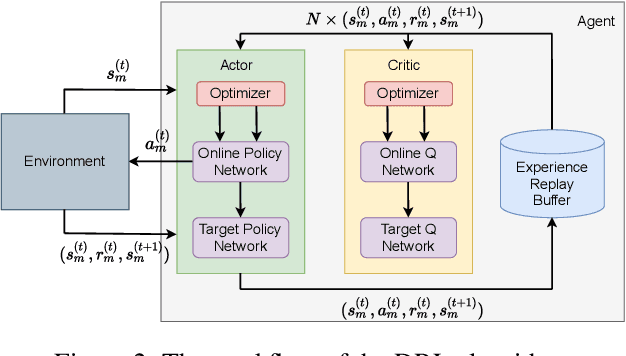
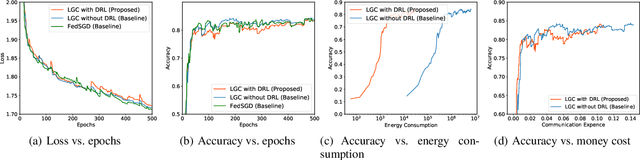
A fundamental issue for federated learning (FL) is how to achieve optimal model performance under highly dynamic communication environments. This issue can be alleviated by the fact that modern edge devices usually can connect to the edge FL server via multiple communication channels (e.g., 4G, LTE and 5G). However, having an edge device send copies of local models to the FL server along multiple channels is redundant, time-consuming, and would waste resources (e.g., bandwidth, battery life and monetary cost). In this paper, motivated by the layered coding techniques in video streaming, we propose a novel FL framework called layered gradient compression (LGC). Specifically, in LGC, local gradients from a device is coded into several layers and each layer is sent to the FL server along a different channel. The FL server aggregates the received layers of local gradients from devices to update the global model, and sends the result back to the devices. We prove the convergence of LGC, and formally define the problem of resource-efficient federated learning with LGC. We then propose a learning based algorithm for each device to dynamically adjust its local computation (i.e., the number of local stochastic descent) and communication decisions (i.e.,the compression level of different layers and the layer to channel mapping) in each iteration. Results from extensive experiments show that using our algorithm, LGC significantly reduces the training time, improves the resource utilization, while achieving a similar accuracy, compared with well-known FL mechanisms.
Controllable Multi-Character Psychology-Oriented Story Generation
Oct 11, 2020
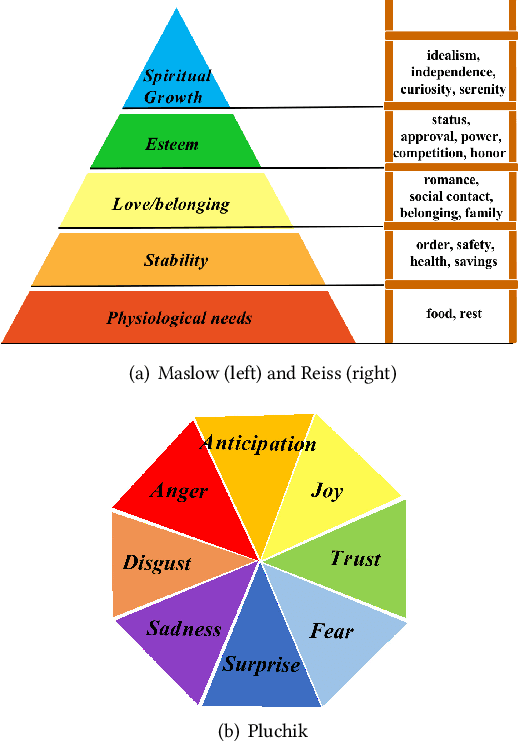
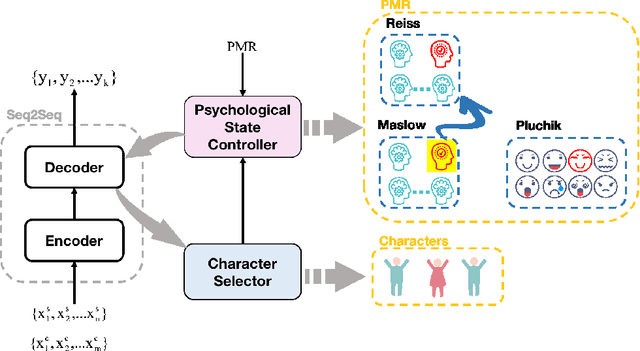
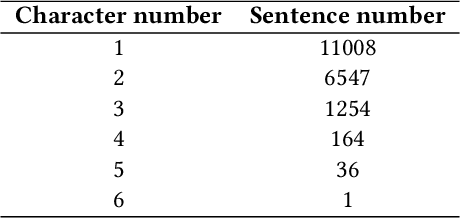
Story generation, which aims to generate a long and coherent story automatically based on the title or an input sentence, is an important research area in the field of natural language generation. There is relatively little work on story generation with appointed emotions. Most existing works focus on using only one specific emotion to control the generation of a whole story and ignore the emotional changes in the characters in the course of the story. In our work, we aim to design an emotional line for each character that considers multiple emotions common in psychological theories, with the goal of generating stories with richer emotional changes in the characters. To the best of our knowledge, this work is first to focuses on characters' emotional lines in story generation. We present a novel model-based attention mechanism that we call SoCP (Storytelling of multi-Character Psychology). We show that the proposed model can generate stories considering the changes in the psychological state of different characters. To take into account the particularity of the model, in addition to commonly used evaluation indicators(BLEU, ROUGE, etc.), we introduce the accuracy rate of psychological state control as a novel evaluation metric. The new indicator reflects the effect of the model on the psychological state control of story characters. Experiments show that with SoCP, the generated stories follow the psychological state for each character according to both automatic and human evaluations.